

In this article, we will delve into the world of neural networks, exploring their inner workings, types, applications, and the challenges they face.
Table of contents
How neural networks are structured
How neural networks generate answers
What is a neural network?
A neural network is a type of deep learning model within the broader field of machine learning (ML) that simulates the human brain. It processes data through interconnected nodes or neurons arranged in layers—input, hidden, and output. Each node performs simple computations, contributing to the model’s ability to recognize patterns and make predictions.
Deep learning neural networks are particularly effective in handling complex tasks such as image and speech recognition, forming a crucial component of many AI applications. Recent advances in neural network architectures and training techniques have substantially enhanced the capabilities of AI systems.
How neural networks are structured
As indicated by its name, a neural network model takes inspiration from neurons, the brain’s building blocks. Adult humans have around 85 billion neurons, each connected to about 1,000 others. One brain cell talks to another by sending chemicals called neurotransmitters. If the receiving cell gets enough of these chemicals, it gets excited and sends its own chemicals to another cell.
The fundamental unit of what is sometimes called an artificial neural network (ANN) is a node, which, instead of being a cell, is a mathematical function. Just like neurons, they communicate with other nodes if they get enough input.
That’s about where the similarities end. Neural networks are structured much simpler than the brain, with neatly defined layers: input, hidden, and output. A collection of these layers is called a model.They learn or train by repeatedly trying to artificially generate output most closely resembling the desired results. (More on that in a minute.)
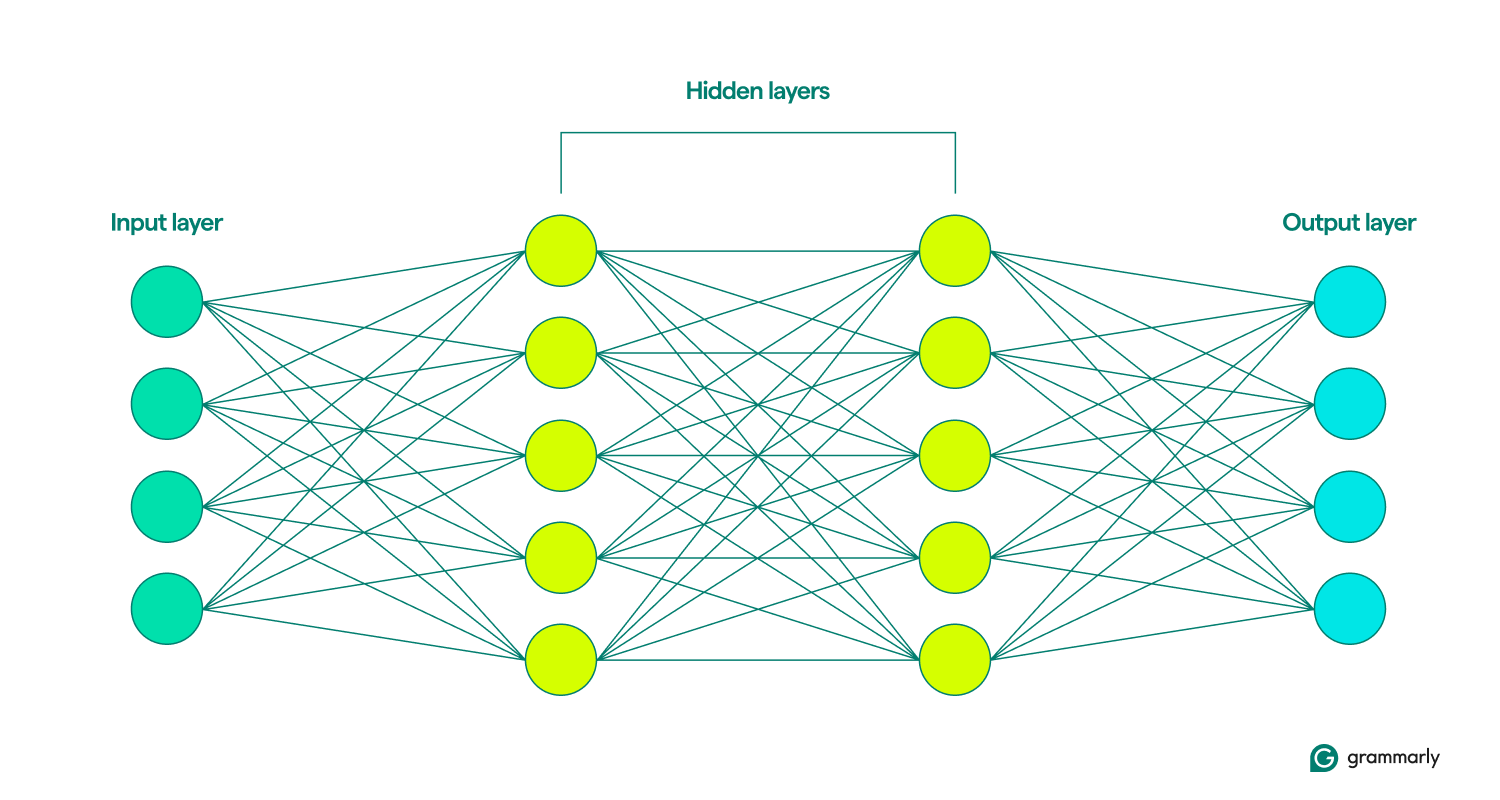
The input and output layers are pretty self-explanatory. Most of what neural networks do takes place in the hidden layers. When a node is activated by input from a previous layer, it does its calculations and decides whether to pass along output to the nodes in the next layer. These layers are so named because their operations are invisible to the end user, though there are techniques for engineers to see what’s happening in the so-called hidden layers.
When neural networks include multiple hidden layers, they are called deep learning networks. Modern deep neural networks usually have many layers, including specialized sub-layers that perform distinct functions. For example, some sub-layers enhance the network’s ability to consider contextual information beyond the immediate input being analyzed.
How neural networks work
Think of how babies learn. They try something, fail, and try again a different way. The loop continues over and over until they’ve perfected the behavior. That’s more or less how neural networks learn, too.
At the very beginning of their training, neural networks make random guesses. A node on the input layer randomly decides which of the nodes in the first hidden layer to activate, and then those nodes randomly activate nodes in the next layer, and so on, until this random process reaches the output layer. (Large language models such as GPT-4 have around 100 layers, with tens or hundreds of thousands of nodes in each layer.)
Considering all the randomness, the model compares its output—which is probably terrible—and figures out how wrong it was. It then adjusts each node’s connection to other nodes, changing how more or less prone they should be to activate based on a given input. It does this repeatedly until its outputs are as close to the desired answers.
So, how do neural networks know what they’re supposed to be doing? Machine learning can be divided into different approaches, including supervised and unsupervised learning. In supervised learning, the model is trained on data that includes explicit labels or answers, like images paired with descriptive text. Unsupervised learning, however, involves providing the model with unlabeled data, allowing it to identify patterns and relationships independently.
A common supplement to this training is reinforcement learning, where the model improves in response to feedback. Frequently, this is provided by human evaluators (if you’ve ever clicked thumbs-up or thumbs-down to a computer’s suggestion, you have contributed to reinforcement learning). Still, there are ways for models to iteratively learn independently, too.
It is accurate and instructive to think of a neural network’s output as a prediction. Whether assessing creditworthiness or generating a song, AI models work by guessing what is most likely right. Generative AI, such as ChatGPT, takes prediction a step further. It works sequentially, making guesses about what should come after the output it just made. (We’ll get into why this can be problematic later.)
How neural networks generate answers
Once a network is trained, how does it process the information it sees to predict the correct response? When you type a prompt like “Tell me a story about fairies” into the ChatGPT interface, how does ChatGPT decide how to respond?
The first step is for the neural network’s input layer to break your prompt into small chunks of information, known as tokens. For an image recognition network, tokens might be pixels. For a network that uses natural language processing (NLP), like ChatGPT, a token is typically a word, a part of a word, or a very short phrase.
Once the network has registered the tokens in the input, that information is passed through the earlier trained hidden layers. The nodes it passes from one layer to the next analyze larger and larger sections of the input. This way, an NLP network can eventually interpret a whole sentence or paragraph, not just a word or a letter.
Now the network can start crafting its response, which it does as a series of word-by-word predictions of what would come next based on everything it’s been trained on.
Consider the prompt, “Tell me a story about fairies.” To generate a response, the neural network analyzes the prompt to predict the most likely first word. For example, it might determine there’s an 80% chance that “The” is the best choice, a 10% chance for “A,” and a 10% chance for “Once.” It then randomly selects a number: If the number is between 1 and 8, it chooses “The”; if it’s 9, it chooses “A”; and if it’s 10, it chooses “Once.” Suppose the random number is 4, which corresponds to “The.” The network then updates the prompt to “Tell me a story about fairies. The” and repeats the process to predict the next word following “The.” This cycle continues, with each new word prediction based on the updated prompt, until a complete story is generated.
Different networks will make this prediction differently. For example, an image recognition model may try to predict which label to give to an image of a dog and determine that there’s a 70% probability that the correct label is “chocolate Lab,” 20% for “English spaniel,” and 10% for “golden retriever.” In the case of classification, generally, the network will go with the most likely choice rather than a probabilistic guess.
Types of neural networks
Here’s an overview of the different types of neural networks and how they work.
- Feedforward neural networks (FNNs): In these models, information flows in one direction: from the input layer, through the hidden layers, and finally to the output layer. This model type is best for simpler prediction tasks, such as detecting credit card fraud.
- Recurrent neural networks (RNNs): In contrast to FNNs, RNNs consider previous inputs when generating a prediction. This makes them well-suited to language processing tasks since the end of a sentence generated in response to a prompt depends upon how the sentence began.
- Long short-term memory networks (LSTMs): LSTMs selectively forget information, which allows them to work more efficiently. This is crucial for processing large amounts of text; for example, Google Translate’s 2016 upgrade to neural machine translation relied on LSTMs.
- Convolutional neural networks (CNNs): CNNs work best when processing images. They use convolutional layers to scan the entire image and look for features such as lines or shapes. This allows CNNs to consider spatial location, like determining if an object is located at the top or bottom half of the image, and also to identify a shape or object type regardless of its location.
- Generative adversarial networks (GANs): GANs are often used to generate new images based on a description or an existing image. They’re structured as a competition between two neural networks: a generator network, which tries to fool a discriminator network into believing that a fake input is real.
- Transformers and attention networks: Transformers are responsible for the current explosion in AI capabilities. These models incorporate an attentional spotlight that allows them to filter their inputs to focus on the most important elements, and how those elements relate to each other, even across pages of text. Transformers can also train on enormous amounts of data, so models like ChatGPT and Gemini are called large language models (LLMs).
Applications of neural networks
There are far too many to list, so here is a selection of ways neural networks are used today, with an emphasis on natural language.
Writing assistance: Transformers have, well, transformed how computers can help people write better. AI writing tools, such as Grammarly, offer sentence and paragraph-level rewrites to improve tone and clarity. This model type has also improved the speed and accuracy of basic grammatical suggestions. Learn more about how Grammarly uses AI.
Content generation: If you’ve used ChatGPT or DALL-E, you’ve experienced generative AI firsthand. Transformers have revolutionized computers’ capacity to create media that resonates with humans, from bedtime stories to hyperrealistic architectural renderings.
While generative AI output is often clear and well-structured, it usually lacks the nuance of human expression, making it sound formal, predictable, or formulaic. If you’re looking for an easy way to make your AI-generated writing more engaging, try our AI humanizer tool, which improves flow and phrasing so your content sounds more natural and is easier to read.
Speech recognition: Computers are getting better every day at recognizing human speech. With newer technologies that allow them to consider more context, models have become increasingly accurate in recognizing what the speaker intends to say, even if the sounds alone could have multiple interpretations.
Medical diagnosis and research: Neural networks excel at pattern detection and classification, which are increasingly used to help researchers and healthcare providers understand and address disease. For instance, we have AI to thank partly for the rapid development of COVID-19 vaccines.
Challenges and limitations of neural networks
Here’s a brief look at some, but not all, of the issues raised by neural networks.
Bias: A neural network can learn only from what it’s been told. If it’s exposed to sexist or racist content, its output will likely be sexist or racist too. This can occur in translating from a non-gendered language to a gendered one, where stereotypes persist without explicit gender identification.
Overfitting: An improperly trained model can read too much into the data it’s been given and struggle with novel inputs. For instance, facial recognition software trained mostly on people of a certain ethnicity might do poorly with faces from other races. Or a spam filter might miss a new variety of junk mail because it’s too focused on patterns it’s seen before.
Hallucinations: Much of today’s generative AI uses probability to some extent to choose what to produce rather than always selecting the top-ranking choice. This approach helps it be more creative and produce text that sounds more natural, but it can also lead it to make statements that are simply false. (This is also why LLMs sometimes get basic math wrong.) Unfortunately, these hallucinations are hard to detect unless you know better or fact-check with other sources.
Interpretability: It’s often impossible to know exactly how a neural network makes predictions. While this can be frustrating from the perspective of someone trying to improve the model, it can also be consequential, as AI is increasingly relied upon to make decisions that greatly impact people’s lives. Some models used today aren’t based on neural networks precisely because their creators want to be able to inspect and understand every stage of the process.
Intellectual property: Many believe that LLMs violate copyright by incorporating writing and other works of art without permission. While they tend not to reproduce copyrighted works directly, these models have been known to create images or phrasing that are likely derived from specific artists or even create works in an artist’s distinctive style when prompted.
Power consumption: All of this training and running of transformer models uses tremendous energy. In fact, within a few years, AI could consume as much power as Sweden or Argentina. This highlights the growing importance of considering energy sources and efficiency in AI development.
Future of neural networks
Predicting the future of AI is notoriously difficult. In 1970, one of the top AI researchers predicted that “in three to eight years, we will have a machine with the general intelligence of an average human being.” (We are still not very close to artificial general intelligence (AGI). At least most people don’t think so.)
However, we can point to a few trends to watch out for. More efficient models would reduce power consumption and run more powerful neural networks directly on devices like smartphones. New training techniques could allow for more useful predictions with less training data. A breakthrough in interpretability could increase trust and pave new pathways for improving neural network output. Finally, combining quantum computing and neural networks could lead to innovations we can only begin to imagine.
Conclusion
Neural networks, inspired by the structure and function of the human brain, are fundamental to modern artificial intelligence. They excel in pattern recognition and prediction tasks, underpinning many of today’s AI applications, from image and speech recognition to natural language processing. With advancements in architecture and training techniques, neural networks continue to drive significant improvements in AI capabilities.
Despite their potential, neural networks face challenges such as bias, overfitting, and high energy consumption. Addressing these issues is crucial as AI continues to evolve. Looking ahead, innovations in model efficiency, interpretability, and integration with quantum computing promise to further expand the possibilities of neural networks, potentially leading to even more transformative applications.





