

Recurrent neural networks (RNNs) are a foundational architecture in data analysis, machine learning (ML), and deep learning. This article explores the structure and functionality of RNNs, their applications, and the advantages and limitations they present within the broader context of deep learning.
Table of contents
RNNs vs. transformers and CNNs
What is a recurrent neural network?
A recurrent neural network is a deep neural network that can process sequential data by maintaining an internal memory, allowing it to keep track of past inputs to generate outputs. RNNs are a fundamental component of deep learning and are particularly suited for tasks that involve sequential data.
The “recurrent” in “recurrent neural network” refers to how the model combines information from past inputs with current inputs. Information from old inputs is stored in a kind of internal memory, called a “hidden state.” It recurs—feeding previous computations back into itself to create a continuous flow of information.
Let’s demonstrate with an example: Suppose we wanted to use an RNN to detect the sentiment (either positive or negative) of the sentence “He ate the pie happily.” The RNN would process the word he, update its hidden state to incorporate that word, and then move on to ate, combine that with what it learned from he, and so on with each word until the sentence is done. To put it in perspective, a human reading this sentence would update their understanding with every word. Once they’ve read and understood the whole sentence, the human can say the sentence is positive or negative. This human process of understanding is what the hidden state tries to approximate.
RNNs are one of the fundamental deep learning models. They’ve done very well on natural language processing (NLP) tasks, though transformers have supplanted them. Transformers are advanced neural network architectures that improve on RNN performance by, for example, processing data in parallel and being able to discover relationships between words that are far apart in the source text (using attention mechanisms). However, RNNs are still useful for time-series data and for situations where simpler models are sufficient.
How RNNs work
To describe in detail how RNNs work, let’s return to the earlier example task: Classify the sentiment of the sentence “He ate the pie happily.”
We start with a trained RNN that accepts text inputs and returns a binary output (1 representing positive and 0 representing negative). Before the input is given to the model, the hidden state is generic—it was learned from the training process but is not specific to the input yet.
The first word, He, is passed into the model. Inside the RNN, its hidden state is then updated (to hidden state h1) to incorporate the word He. Next, the word ate is passed into the RNN, and h1 is updated (to h2) to include this new word. This process recurs until the last word is passed in. The hidden state (h4) is updated to include the last word. Then the updated hidden state is used to generate either a 0 or 1.
Here’s a visual representation of how the RNN process works:
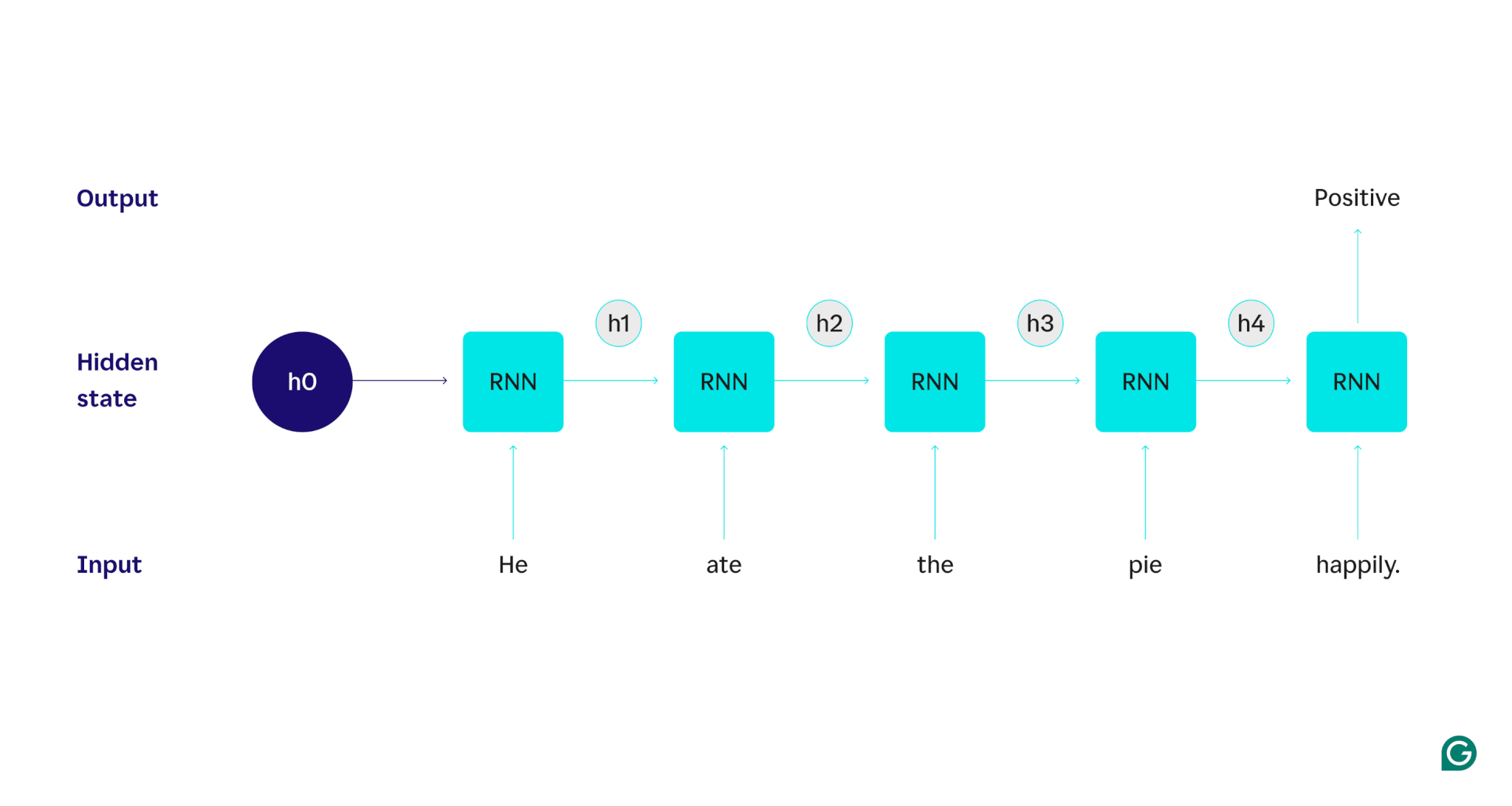
That recurrence is the core of the RNN, but there are a few other considerations:
- Text embedding: The RNN can’t process text directly since it works only on numeric representations. The text must be converted into embeddings before it can be processed by an RNN.
- Output generation: An output will be generated by the RNN at each step. However, the output may not be very accurate until most of the source data is processed. For example, after processing only the “He ate” part of the sentence, the RNN might be uncertain as to whether it represents a positive or negative sentiment—“He ate” might come across as neutral. Only after processing the full sentence would the RNN’s output be accurate.
- Training the RNN: The RNN must be trained to perform sentiment analysis accurately. Training involves using many labeled examples (e.g., “He ate the pie angrily,” labeled as negative), running them through the RNN, and adjusting the model based on how far off its predictions are. This process sets the default value and change mechanism for the hidden state, allowing the RNN to learn which words are significant for tracking throughout the input.
Types of recurrent neural networks
There are several different types of RNNs, each varying in their structure and application. Basic RNNs differ mostly in the size of their inputs and outputs. Advanced RNNs, such as long short-term memory (LSTM) networks, address some of the limitations of basic RNNs.
Basic RNNs
One-to-one RNN: This RNN takes in an input of length one and returns an output of length one. Therefore, no recurrence actually happens, making it a standard neural network rather than an RNN. An example of a one-to-one RNN would be an image classifier, where the input is a single image and the output is a label (e.g., “bird”).
One-to-many RNN: This RNN takes in an input of length one and returns a multipart output. For example, in an image-captioning task, the input is one image, and the output is a sequence of words describing the image (e.g., “A bird crosses over a river on a sunny day”).
Many-to-one RNN: This RNN takes in a multipart input (e.g., a sentence, a series of images, or time-series data) and returns an output of length one. For example, a sentence sentiment classifier (like the one we discussed), where the input is a sentence and the output is a single sentiment label (either positive or negative).
Many-to-many RNN: This RNN takes a multipart input and returns a multipart output. An example is a speech recognition model, where the input is a series of audio waveforms and the output is a sequence of words representing the spoken content.
Advanced RNN: Long short-term memory (LSTM)
Long short-term memory networks are designed to address a significant issue with standard RNNs: They forget information over long inputs. In standard RNNs, the hidden state is heavily weighted toward recent parts of the input. In an input that’s thousands of words long, the RNN will forget important details from the opening sentences. LSTMs have a special architecture to get around this forgetting problem. They have modules that pick and choose which information to explicitly remember and forget. So recent but useless information will be forgotten, while old but relevant information will be retained. As a result, LSTMs are far more common than standard RNNs—they simply perform better on complex or long tasks. However, they are not perfect since they still choose to forget items.
RNNs vs. transformers and CNNs
Two other common deep learning models are convolutional neural networks (CNNs) and transformers. How do they differ?
RNNs vs. transformers
Both RNNs and transformers are heavily used in NLP. However, they differ significantly in their architectures and approaches to processing input.
Architecture and processing
- RNNs: RNNs process input sequentially, one word at a time, maintaining a hidden state that carries information from previous words. This sequential nature means that RNNs can struggle with long-term dependencies due to this forgetting, in which earlier information can be lost as the sequence progresses.
- Transformers: Transformers use a mechanism called “attention” to process input. Unlike RNNs, transformers look at the entire sequence simultaneously, comparing each word with every other word. This approach eliminates the forgetting issue, as each word has direct access to the entire input context. Transformers have shown superior performance in tasks like text generation and sentiment analysis due to this capability.
Parallelization
- RNNs: The sequential nature of RNNs means that the model must complete processing one part of the input before moving on to the next. This is very time-consuming, as each step depends on the previous one.
- Transformers: Transformers process all parts of the input simultaneously, as their architecture does not rely on a sequential hidden state. This makes them much more parallelizable and efficient. For example, if processing a sentence takes 5 seconds per word, an RNN would take 25 seconds for a 5-word sentence, whereas a transformer would take only 5 seconds.
Practical implications
Due to these advantages, transformers are more widely used in industry. However, RNNs, particularly long short-term memory (LSTM) networks, can still be effective for simpler tasks or when dealing with shorter sequences. LSTMs are often used as critical memory storage modules in large machine learning architectures.
RNNs vs. CNNs
CNNs are fundamentally different from RNNs in terms of the data they handle and their operational mechanisms.
Data type
- RNNs: RNNs are designed for sequential data, such as text or time series, where the order of the data points is important.
- CNNs: CNNs are used primarily for spatial data, like images, where the focus is on the relationships between adjacent data points (e.g., the color, intensity, and other properties of a pixel in an image are closely related to the properties of other nearby pixels).
Operation
- RNNs: RNNs maintain a memory of the entire sequence, making them suitable for tasks where context and sequence matter.
- CNNs: CNNs operate by looking at local regions of the input (e.g., neighboring pixels) through convolutional layers. This makes them highly effective for image processing but less so for sequential data, where long-term dependencies might be more important.
Input length
- RNNs: RNNs can handle variable-length input sequences with a less defined structure, making them flexible for different sequential data types.
- CNNs: CNNs typically require fixed-size inputs, which can be a limitation for handling variable-length sequences.
Applications of RNNs
RNNs are widely used in various fields due to their ability to handle sequential data effectively.
Natural language processing
Language is a highly sequential form of data, so RNNs perform well on language tasks. RNNs excel in tasks such as text generation, sentiment analysis, translation, and summarization. With libraries like PyTorch, someone could create a simple chatbot using an RNN and a few gigabytes of text examples.
Speech recognition
Speech recognition is language at its core and so is highly sequential, as well. A many-to-many RNN could be used for this task. At each step, the RNN takes in the previous hidden state and the waveform, outputting the word associated with the waveform (based on the context of the sentence up to that point).
Music generation
Music is also highly sequential. The previous beats in a song strongly influence the future beats. A many-to-many RNN could take a few starting beats as input and then generate additional beats as desired by the user. Alternatively, it could take a text input like “melodic jazz” and output its best approximation of melodic jazz beats.
Advantages of RNNs
Although RNNs are no longer the de facto NLP model, they still have some uses due to a few factors.
Good sequential performance
RNNs, especially LSTMs, do well on sequential data. LSTMs, with their specialized memory architecture, can manage long and complex sequential inputs. For instance, Google Translate used to run on an LSTM model before the era of transformers. LSTMs can be used to add strategic memory modules when transformer-based networks are combined to form more advanced architectures.
Smaller, simpler models
RNNs usually have fewer model parameters than transformers. The attention and feedforward layers in transformers require more parameters to function effectively. RNNs can be trained with fewer runs and data examples, making them more efficient for simpler use cases. This results in smaller, less expensive, and more efficient models that are still sufficiently performant.
Disadvantages of RNNs
RNNs have fallen out of favor for a reason: Transformers, despite their larger size and training process, don’t have the same flaws as RNNs do.
Limited memory
The hidden state in standard RNNs heavily biases recent inputs, making it difficult to retain long-range dependencies. Tasks with long inputs do not perform as well with RNNs. While LSTMs aim to address this issue, they only mitigate it and do not fully resolve it. Many AI tasks require handling long inputs, making limited memory a significant drawback.
Not parallelizable
Each run of the RNN model depends on the output of the previous run, specifically the updated hidden state. As a result, the entire model must be processed sequentially for each part of an input. In contrast, transformers and CNNs can process the entire input simultaneously. This allows for parallel processing across multiple GPUs, significantly speeding up the computation. RNNs’ lack of parallelizability leads to slower training, slower output generation, and a lower maximum amount of data that can be learned from.
Gradient issues
Training RNNs can be challenging because the backpropagation process must go through each input step (backpropagation through time). Due to the many time steps, the gradients—which indicate how each model parameter should be adjusted—can degrade and become ineffective. Gradients can fail by vanishing, which means they become very small and the model can no longer use them to learn, or by exploding, wherein gradients become very large and the model overshoots its updates, making the model unusable. Balancing these issues is difficult.





