

This post was written with Joel Tetreault, the director of research at Grammarly.
A majority of our communication now happens online, through social media, discussion forums, and online conversations. People have been talking together online now for nearly four decades, giving rise to a very active area of research: understanding online communication. But online conversations aren’t always human-to-human interactions. Computers work alongside human professionals to provide customer support. Chatbots market products and enable customers to make purchases. Smart-home devices and voice assistants have enabled hands-free operation through voice commands. And businesses are replacing cluttered UI with intuitive natural language interfaces. As conversational interfaces like these become more ubiquitous, understanding how online conversations work is more essential than ever in creating a fulfilling and productive experience for the people who engage with them. After all, in order for a chatbot to help you book the right plane tickets or suggest a good restaurant, it needs to understand what you’re looking for.
Computer scientists call this area of research “Dialogue Understanding,” and it’s the subject of new research from Grammarly that will appear at the NAACL conference in Minneapolis this week.
What are dialogue acts—and why care about them?
Before diving into the details of our algorithms, let’s take a look at an example of a typical conversation:
Maddie: Hey James! Greeting
Maddie: How have you been? Greeting-Question
James: Hey Maddie! Greeting
James: Doing alright, thanks! Greeting-Answer
Maddie: So what did you do this weekend? Question
James: Well, uh, pretty much spent most of my time in the yard. Statement
Maddie: Uh-Huh. Backchannel
Maddie: What do you have planned for your yard? Question
James: Well, we’re in the process of revitalizing it. Statement-non-opinion
…
Maddie: Florida is pretty good about recycling isn’t it? Yes-No-Question
James: Well, they just kicked it off down here in Sarasota County. Dispreferred answers
Maddie: Oh, they did? Backchannel-question
James: Yeah, they started first in Sarasota city. Statement-non-opinion
In the above conversation, each response is called an utterance, and each utterance is labeled with what is called a dialogue act. To guide the flow of conversations, dialogue acts (such as greeting, question, opinion, request, etc.) are useful identifiers of the general intent of an utterance. When combined with the overall topic of a conversation, they can help immensely in natural language understanding (NLU)—the technology that enables the development of conversational systems. In the above conversation, it is easy to see how the conversation naturally flows from greetings and pleasantries to asking questions and exchanging information. In order for a conversational system to engage in a conversation that feels natural to a human partner, it needs to keep up with this natural flow. And to that end, it must be able to correctly identify the intent of each utterance. If the system knows that the previous two utterances were a greeting and a question, it can formulate a more suitable response.
A system that understands the natural flow of a conversation has applications that go beyond just chatting directly with humans. It could, for example, transcribe a business meeting and autonomously generate a high-quality summary of the important points. Or it could help enable a smooth conversation between two people from different backgrounds or professions. In the context of conversational flow, identifying dialogue acts is the first step toward building such an NLU system. It’s the fundamental task that other downstream components of an NLU system would build on. Hence, accurately identifying dialogue acts is a crucial task.
What we did
We built a deep learning model to learn to tag a sequence of utterances in a conversation. Deep learning is an area of AI that’s based on artificial neural networks, that involves teaching an algorithm to perform tasks automatically by showing it lots of examples rather than by providing a series of rigidly predefined steps. We drew from recent advances in natural language processing (NLP), such as self-attention, hierarchical deep learning models, and contextual dependencies, to produce a dialogue act classification model that is effective across multiple domains.
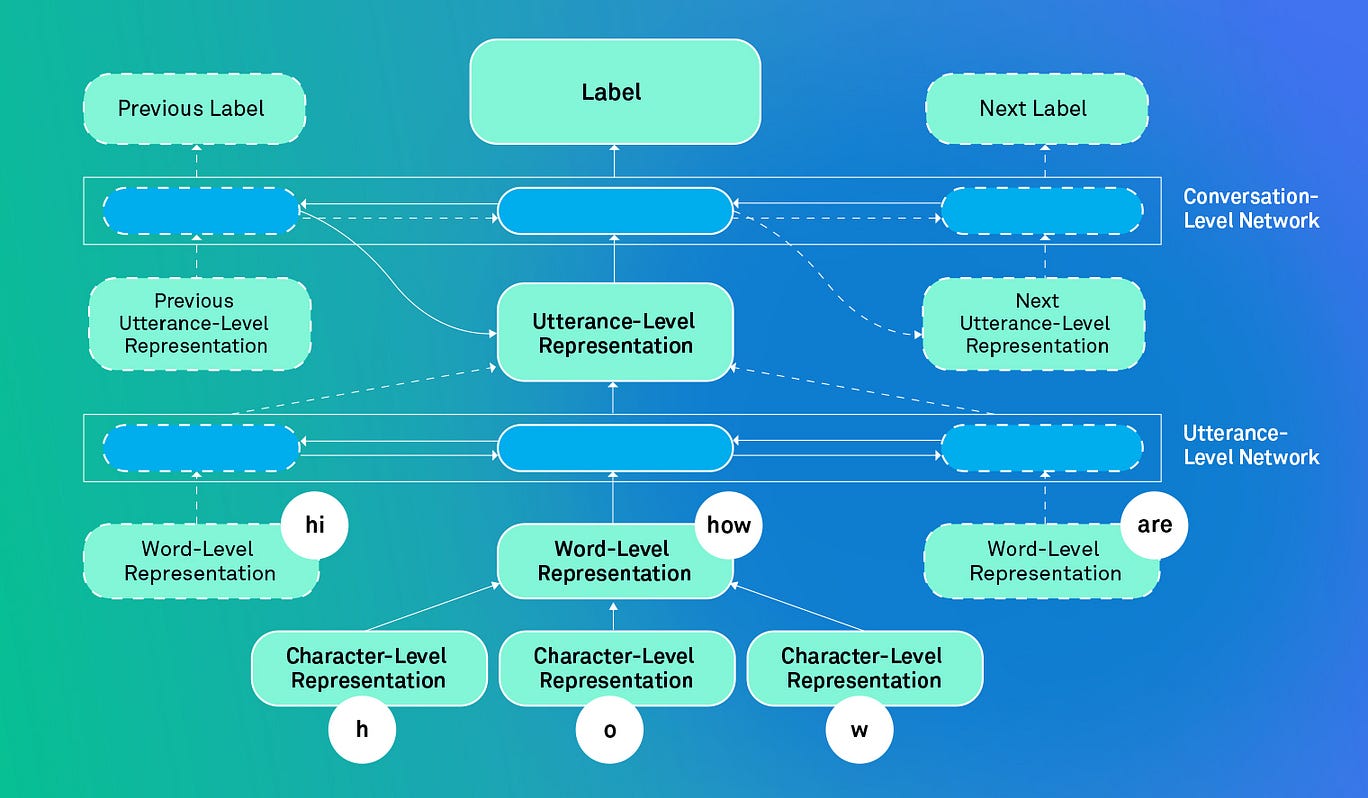
Consider a simple phrase like “hi, how are you?” The model learns a representation of this utterance as a string of characters, and then as a combination of words that are formed by those characters. The model then combines those word-level representations to learn the utterance representation. Further, representations of utterances from the previous turn and the predicted labels of utterances in the conversation so far are also used for context. The model uses all of this combined information to try to correctly identify the dialogue act of the current utterance. The powerful thing about such an architecture is that at any given point, the utterance representation reflects the system’s understanding of the conversation so far. Technical details of the model and its architecture can be found in the paper.
We trained our model on two standard datasets for the task—the Switchboard Dialogue Act Corpus (SwDA) consisting of 43 classes, and the 5-class version of the ICSI Meeting Recorder Dialogue Act Corpus (MRDA) corpus. We used the same method to evaluate our system on these datasets as Lee and Dernoncourt (2016).
What we found
Once the models were trained, we tested them on a set of conversations in the dataset that the model had not yet seen. We found that the model outperformed leading models on the Switchboard dataset, and came quite close to being the best on MRDA. Experimenting with different ways of learning an utterance representation led to many insights about conversational understanding. One is that conversations are contextual—a system is highly empowered by seeing what has been said before, and performs much better when it properly learns the progression of a conversation. Another is that conversations are noisy. This makes them hard to understand, especially if they are long since the context cannot be modeled appropriately. This calls for more robust modeling techniques. And another is that conversations have a hierarchical dependency—representations learned at the utterance level can affect what the system models at the conversation level.
Looking forward
Dialogue Act Classification is just the first step. There’s a lot more work to be done in understanding conversations and a lot of exciting applications for a system that can reliably classify dialogue acts in a conversation. One day, a system like this could not only tell you how a conversation is going but also help you understand what is being said, and how to craft an appropriate response to what is being said — leading to higher quality conversations.
As for Grammarly, this work is yet another step toward our vision of creating a comprehensive communication assistant that helps you understand another person’s message, and have your message be understood just as intended.
Vipul Raheja is a research scientist at Grammarly. Joel Tetreault is the director of research at Grammarly. They will be presenting this research at the 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics in Minneapolis, June 2–7, 2019. The accompanying research paper, entitled “Dialogue Act Classification with Context-Aware Self-Attention,” will be published in the Proceedings of the NAACL.






