

This article was co-written by Applied Research Scientists Vipul Raheja and Dhruv Kumar.
A polished piece of writing doesn’t just spring, fully formed, into being—it takes shape gradually over successive rounds of editing. Revising iteratively is how authors deliberate over and organize their thoughts, find better lines of argument, and develop their style and voice.
The NLP community has made great strides in modeling problems that are related to revision, like Grammatical Error Correction and Text Simplification. But the iterative text revision process is a complex cognitive task, and modeling it remains difficult.
To support a better understanding of real-world text editing, Grammarly researchers Wanyu Du1, Vipul Raheja, and Dhruv Kumar, along with collaborators Dongyeop Kang (University of Minnesota) and Zae Myung Kim (Université Grenoble Alpes), present IteraTeR: the first large-scale, multi-domain, edit-intention annotated corpus for the Iterative Text Revision task. In this blog post, we’ll explain how we built IteraTeR. We’ll also share the results of experimentally modeling text revision using this dataset.

Here’s a sample from our dataset showing an iteratively revised ArXiv abstract snippet that has been annotated with edit intentions.
For a more in-depth read, please see our research paper, Understanding Iterative Revision from Human-Written Text by Wanyu Du, Vipul Raheja, Dhruv Kumar, Zae Myung Kim, Melissa Lopez, and Dongyeop Kang, which appeared at the 60th Annual Meeting of the Association for Computational Linguists (ACL) in 2022.
The writing process
There has been extensive research dating back to the eighties showing that writing involves three distinct cognitive processes: planning (generating and organizing ideas), translation (expressing ideas through language), and revision (addressing the discrepancies between the intended meaning and the actual meaning).2
This sounds like a tidy progression in theory, but in reality, the writing process is anything but. Instead, the process twists and turns in on itself: Editing leads back into the planning and drafting stages as writers uncover new directions to explore. In other words, writing—and specifically, revising—isn’t a linear process; it’s an iterative one.
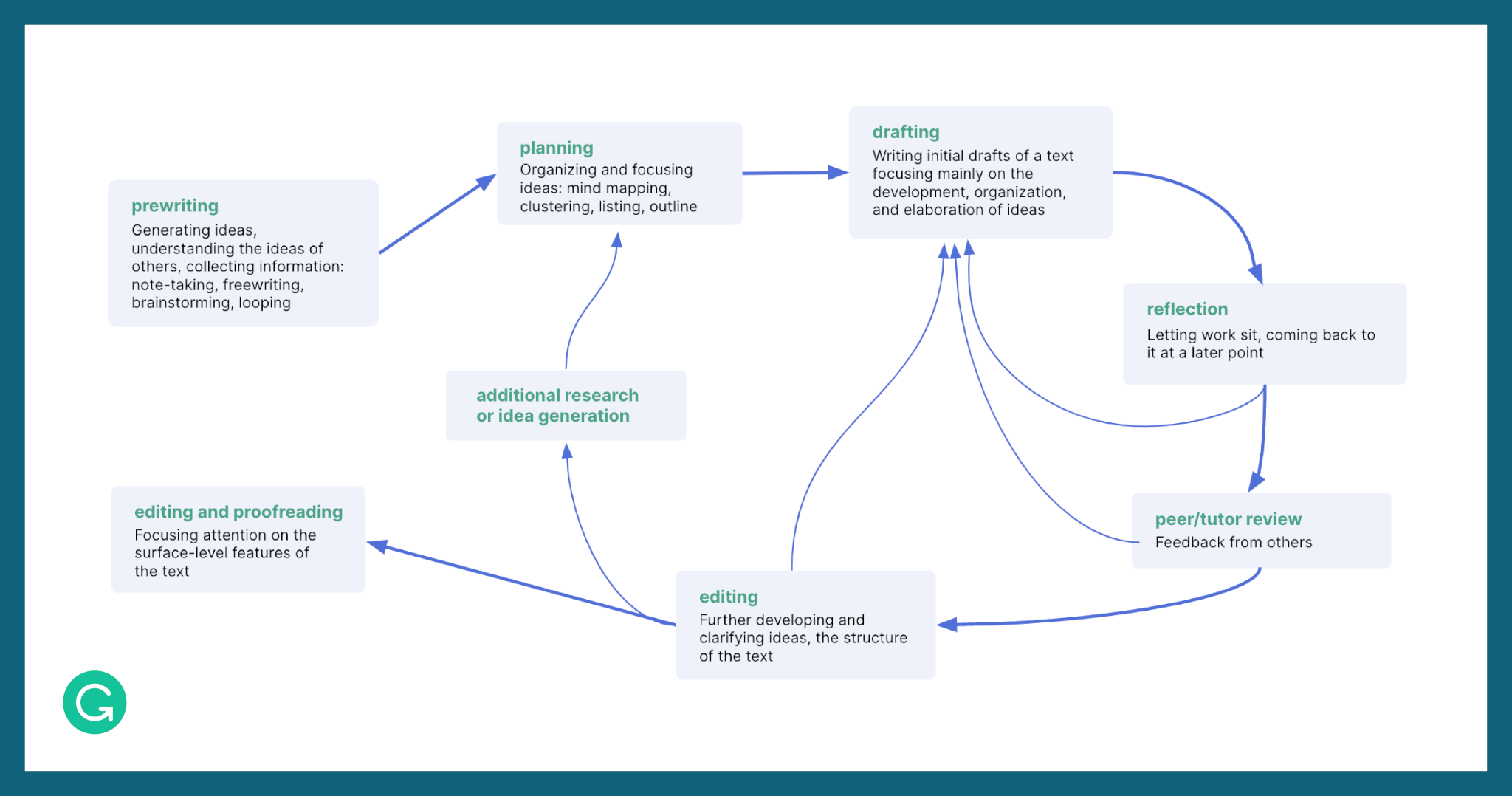
Source: Caroline Coffin, et al. Teaching academic writing: A toolkit for higher education. Routledge, 2005.
What we did
In our research, we sought to address the gaps in the prior work on Iterative Text Revision. These limitations were:
- Simplifying the task to a non-iterative setting by converting an original text to a final text in a single pass (using sequence-to-sequence text generation)
- Focusing on sentence-level editing only
- Developing an edit intention taxonomy that doesn’t generalize beyond a specific domain (like Wikipedia or academic papers)
Combined, these factors limit our understanding of how text revision happens iteratively in the real world. We wanted to develop a taxonomy and dataset that would more broadly encompass the dimensions and nuances of the task.
Building blocks for Iterative Text Revision
We first sought to consolidate the key pieces of the Iterative Text Revision task into a framework that can be applied and reused broadly. The following building blocks receive formal definitions in our work:
- Edit action: A local change applied to a certain text object. Local changes include insert, delete, and modify and operate at multiple granularities: word, sentence, or paragraph level.
- Edit intention: The revising goal of an editor when making an edit action. For now, we’ve assumed one goal only per edit action.
- Document revision: A set of edit actions and their respective edit intentions that, when applied, create a new document. Think of someone clicking “save” after editing a Wikipedia article—that’s a new document revision.
Edit intention taxonomy
Our next step was to create a new edit intention taxonomy that could scale to additional domains and support different levels of granularity and revision depth.
We collected thousands of public documents along with their revision histories across different domains (there’s more info on the dataset in the next section). Then, our team of professional linguists analyzed the edits that occur in those documents. Building on prior literature, we then came up with a new edit intention taxonomy to comprehensively model the iterative text revision process:

Our edit intention taxonomy features Fluency, Coherence, Clarity, and Style categories. We have a separate category for edits that change the meaning of the text. Finally, we use “Other” if the intention cannot be categorized using our taxonomy.
From a modeling point of view, it’s more tractable—and of more practical value—to focus on the types of revisions that improve the quality of the text rather than changing the meaning. So, we separated edits that change the meaning from other kinds of edits. Focusing on quality improvements, we defined edit intention subcategories: Fluency, Coherence, Clarity, and Style.
Data collection
To ensure that we had a dataset representing different kinds of writing goals, formats, and revision patterns, we sourced our data from the following places:
- Wikipedia: We collected revision histories of the main contents of Wikipedia articles.
- ArXiv: We collected research paper abstracts submitted at different timestamps (and therefore representing different versions).
- Wikinews: We collected revision histories of news content.
We performed a combination of manual and automatic annotation (more details are in the paper). IteraTeR is currently intended to support formal writing only, because this is where iterative text revision happens most frequently, often with multiple editors working on a piece. That said, extending the dataset to cover informal communication like email and blogs is an area we might explore in the future.
What we found
Data insights
Our dataset contains texts at different iterations (depths) of editing, and each change is annotated with the human editor’s most likely intention. Here’s how those intentions were distributed across revision depths for different types of writing in our dataset:
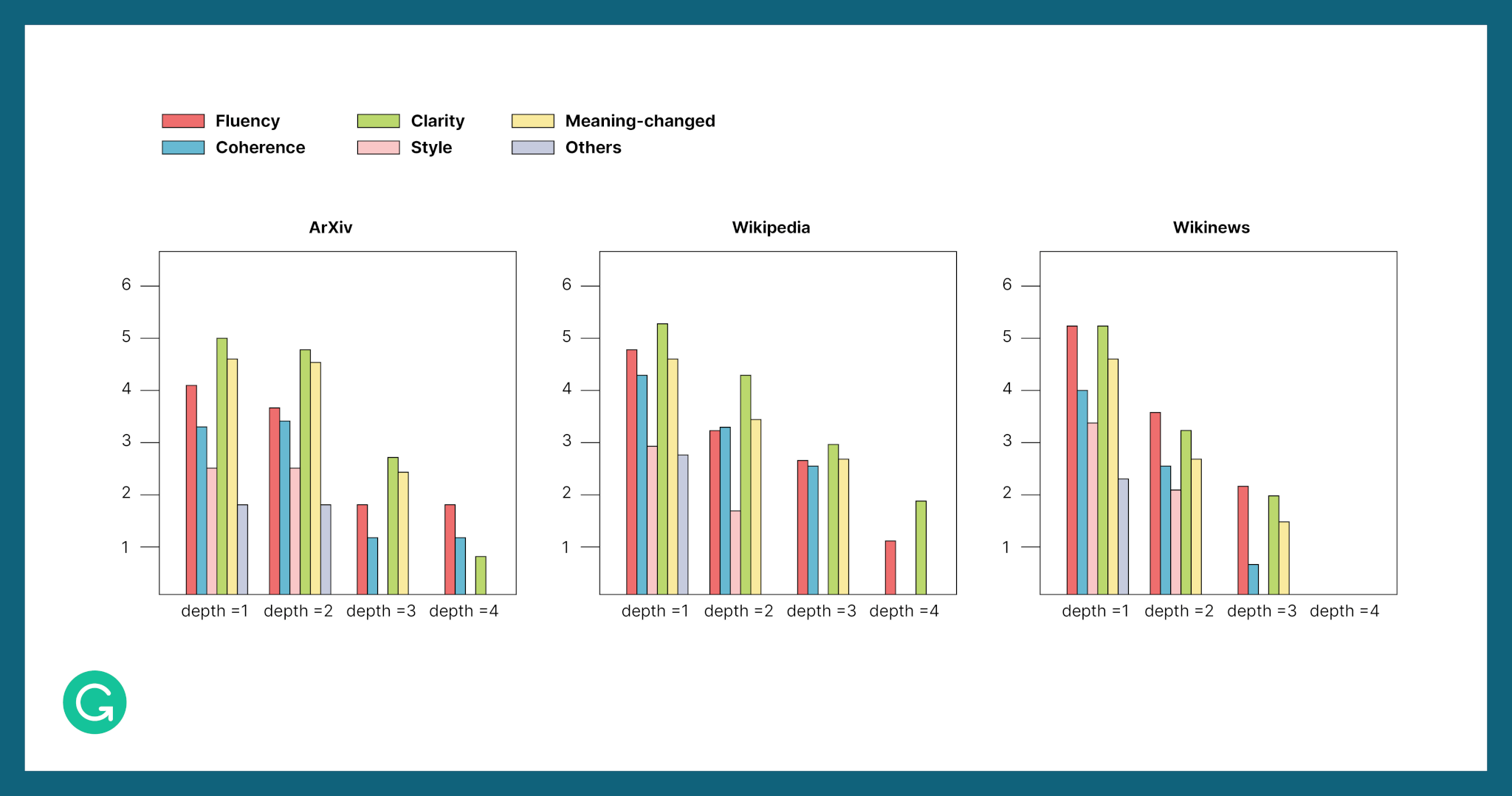
In all three domains, authors tend to make most edits at revision depth 1. The number rapidly decreases at depth 2 and drops off further at depths 3 and 4. We also found that clarity edits are the most frequent type of edits across all the domains, which shows that improving readability is a priority during revision.
We were curious about which kinds of edits improved the quality of the text. In addition to automatic evaluations, we asked human annotators to look at revisions in our dataset and judge whether the resulting text was of higher or lower quality than the original. This experiment showed that Fluency intentions (edits that fix grammar mistakes) and Coherence intentions (edits that make the text more logically consistent) were the most successful at improving text quality, as judged by human linguistic experts.
Here’s an example:



Interestingly, Style was the one category of edit intention that had an overall negative effect on quality as judged by our human annotators. Style edits may have less to do with improving the reader’s experience and more to do with expressing the writer’s personal preferences.

Here are three examples of Style edit intentions where we had inter-annotator agreement that the resulting text was lower quality than the original.
Modeling framework
Ultimately, the goal of IteraTeR is to help machine learning practitioners and natural language processing researchers model the Iterative Text Revision task. So we wanted to explore how different kinds of models would perform when trained to do iterative text revision using IteraTeR.
We experimented with two kinds of models: edit-based (“tag and insert”) models like FELIX and Transformer-based encoder-decoder models like BART and PEGASUS. We also tried training the models without edit intention annotations to see how the edit intention information affected the iterative revision performance.
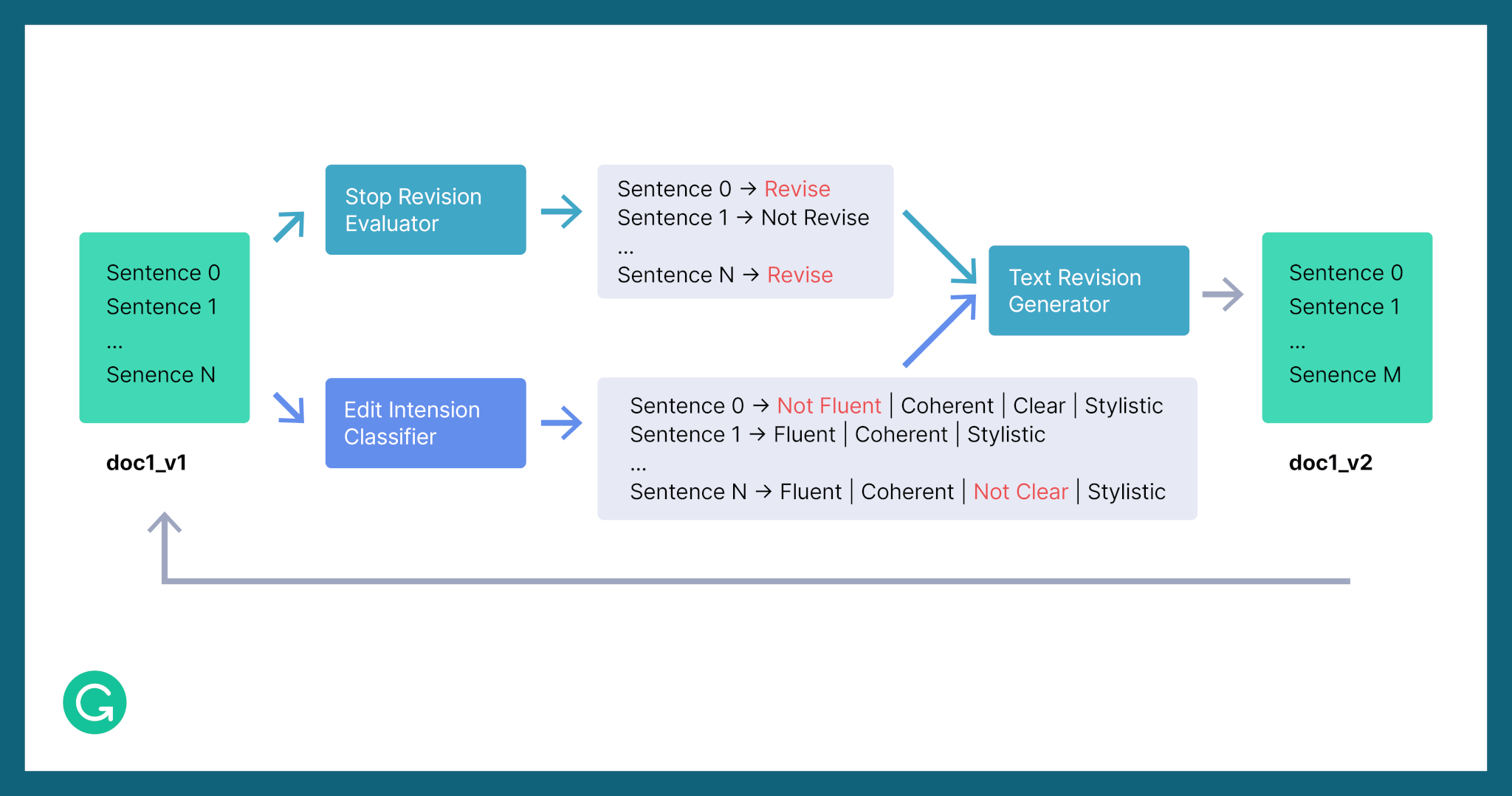
Here’s how we set up our system:
- Given a document with n sentences, we first predict whether the document needs revision and what type of revisions (edit intentions) are needed.
- Next, for predicted sentences that need revision, a text revision model makes the edits, leading to a new document revision.
- The process repeats until we predict that it’s appropriate to stop.
Modeling results
We computed several automatic metrics for our models. The SARI score, which measures the words that were added, deleted, and kept by the system compared to the reference text, indicated that the models’ revisions did in fact improve the overall quality of the documents. Both kinds of models performed better on the dataset with edit intentions compared to the dataset without edit intentions, showing that edit intention annotations are helpful in making text revisions. Please refer to the paper for more details.
Since this is a complex and subjective task, automatic metrics aren’t enough—we also had our best-performing model evaluated by human experts on four different quality criteria:
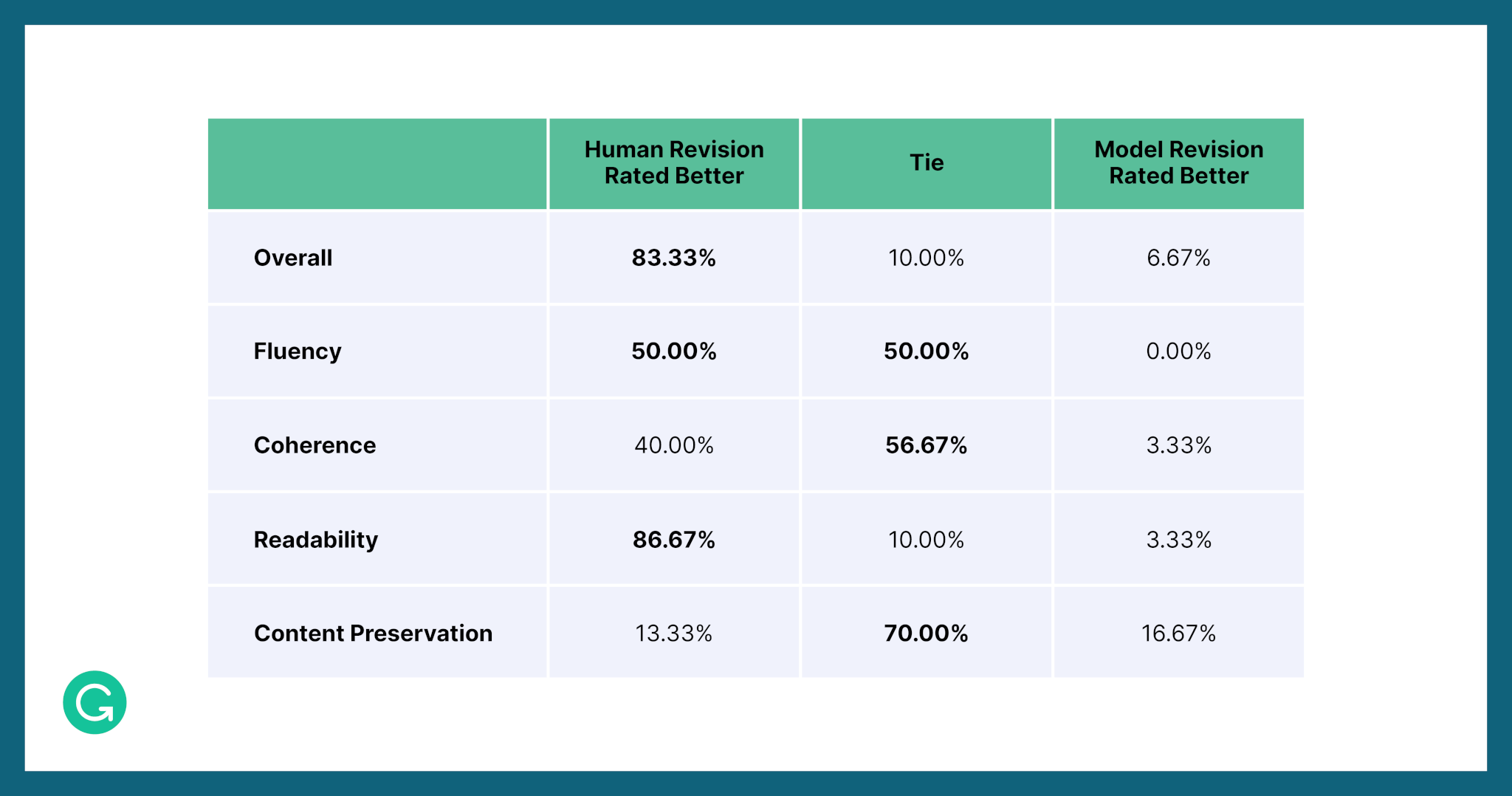
You can see that there is a large gap between the best performing model’s revisions and human revisions, indicating the challenging nature of this problem. While model-based revisions can achieve comparable performance with human revisions on fluency, coherence, and meaning preservation, human revisions still outperform model-based ones in terms of readability and overall quality.
Iterative-ness
We also experimented with our models’ ability to learn when to stop revising. We removed the edit intention classifier and the stop revision evaluator, and we simply let the model make revisions until it stopped. We discovered that FELIX was unable to effectively evaluate the text quality for each revision and kept revising until our cutoff of ten iterations. PEGASUS, on the other hand, learned to stop revising after a certain text quality had been reached. This is an interesting insight, showing that a generative model was able to pick up on the nuances of iterative revisions and decide whether or not to make further changes.
Looking forward
Writing assistance systems capable of iteratively revising text could dramatically improve how we communicate. Our research team saw firsthand that modeling iterative text revision is extremely challenging, and this work is a step toward understanding this rather complex process.
As we move forward, we envision many new forms of human-machine collaborative writing in which writers rely on machines not only for low-level, simple language assistance but also for high-level, advanced collaboration—including revision. To explore potential applications, our research group investigated using revision models as part of a human-in-the-loop text editing system, where writers can revise documents iteratively by interacting with the system and accepting or rejecting its suggested edits, leading to a more productive revision experience.
We hope that, by making our data and models public, we and others in the field will have a way to benchmark each other and move this area of research forward. We’re excited about the potential for IteraTeR to serve as a foundation for further improvements in building iterative writing assistance systems. Grammarly co-organized and sponsored the First Workshop on Intelligent and Interactive Writing Assistants (In2Writing) at ACL 2022 to promote further research in this area.
If you’re interested in working on problems like these, Grammarly’s NLP team is hiring! Check out our open roles for more information.
1 Wanyu Du, a PhD student at the University of Virginia, contributed to this work as a research intern at Grammarly.
2 Linda Flower and John R. Hayes, “The Cognition of Discovery: Defining a Rhetorical Problem,” College Composition and Communication 31, no. 1 (February 1980): 21–32.






