

This article was co-written by Grammarly Applied Research Scientists Kostiantyn Omelianchuk, Vipul Raheja, and Oleksandr Skurzhanskyi.
Grammarly’s goal is to improve communication for everyone, and part of that is helping people understand text that may be convoluted or complicated to read. Machine learning (ML) and natural language processing (NLP), which are central to Grammarly’s mission, can help by taking a complex piece of text and converting it into a simpler form. Text simplification can be applied to any piece of communication, from research papers to emails.

Many text simplification solutions coming out of the NLP research community use black-box neural network models to perform autoregressive generation: They take a complex sentence and try to sequentially predict each word in the simplified version. These models can take a long time to make predictions and require large amounts of data. Seeking a more efficient and scalable approach, Grammarly’s research team experimented with a non-autoregressive technique where we predict the edit operations (or “tags”) needed to transform complex text into a simpler version.
With Text Simplification by Tagging (TST), our experimental model achieves near state-of-the-art performance on benchmark test datasets for the task and performs faster inference than the current state-of-the-art text simplification system (by about 11 times). It also relies much less on annotated data, and the results are easier to interpret and explain. This research is the subject of a new paper by Grammarly Applied Research Scientists Kostiantyn Omelianchuk, Vipul Raheja, and Oleksandr Skurzhanskyi, which was accepted to the 16th Workshop on Innovative Use of NLP for Building Education Applications (BEA) at the European Chapter of the Association for Computational Linguistics (EACL) conference in 2021.
Tag vs. rewrite
Most state-of-the-art text simplification techniques that have been proposed in the NLP research community have taken the approach of “translating” complex text into a simpler form, essentially generating all the words from scratch. However, there are limitations to using these approaches for real-world applications. The models have long inference times and require huge amounts of annotated data. And, their decisions aren’t interpretable and explainable to the end user.
TST doesn’t follow the typical approach of rewriting the text. Instead, we trained a model to tag the text with edit operations and applied those edit operations to go from complex sentences to simpler ones. We initially developed the “tag, not rewrite” method for the NLP problem of grammatical error correction, or GEC, achieving state-of-the-art results with our “GECToR” system. With TST, our hypothesis was that we could extend this technique to text simplification, since it reflects the way humans write and edit: We usually simplify our sentences by changing certain words and phrases, instead of concocting a new sentence from scratch. In fact, when we look at the canonical datasets for this task, the simplified sentences retain 70%–80% of the same words as the original.
Defining the tags
In our system, each word gets a tag indicating what type of edit operation should be applied to it. When we developed our tagging approach for GEC, we created a set of 5,000 tags. As we looked to adapt the GECToR approach to text simplification, the first question was whether we’d be able to use the same set of tags for both problems.
To answer this question, we developed a set of tags for TST independently, and found a 92.64% overlap with the tag distribution for GECToR. This wasn’t surprising, since we designed GECToR to be broad enough to handle many kinds of text-editing tasks. With so much similarity between the tags, we decided to use the same set of 5,000 tags for TST. This allowed us to initialize our model with what it had already learned from the GEC task, which boosted our results.
The tags break down into a few groups:
- The $KEEP tag indicates that this word should remain unchanged in the output text.
- The $DELETE tag indicates that this word should be removed from the output text.
- $APPEND_{t1} describes a set of tags that append a new word to the existing one. The “transformation suffix” in the braces describes what should be appended. There are 1,167 unique APPEND tags in our model’s vocabulary.
- $REPLACE_{t2} describes a set of tags that replace the word with a different one in the output text. Our model contains 3,802 unique REPLACE tags.
- The remaining 29 tags represent highly specific grammatical changes, such as NOUN NUMBER and VERB FORM tags that will convert singular nouns to plural ones or change a verb to express a different number or tense.
Iterative tagging
After we tag the original sentence, we apply the edit operations as indicated by the tags, giving us a new sentence.

As we saw with GECToR, some edit operations in a sentence may depend on others, and we may need to do another round of tagging and simplifying. More iterations tend to improve the model’s performance, but can slow down the results. In our research, we experimented with between one and five iterations (the results can be found in the paper).
Tagging model
Tags do not depend on each other directly the way that words do, so our model does not need to predict edit operations one-by-one as when rewriting text. Instead, we can parallelize the model’s predictions, helping it run much faster than traditional methods.
We achieve this by using two feed-forward layers for edit operation detection and classification, respectively. For every position in the input sequence, the edit-detection layer predicts the probability that the text should be changed, whereas the edit-classification layer predicts the type of tag that should be applied. We also have a minimum edit probability threshold. If the output of the edit-detection layer is below this threshold at any position in the predicted sentence, we do not perform any edit operations.
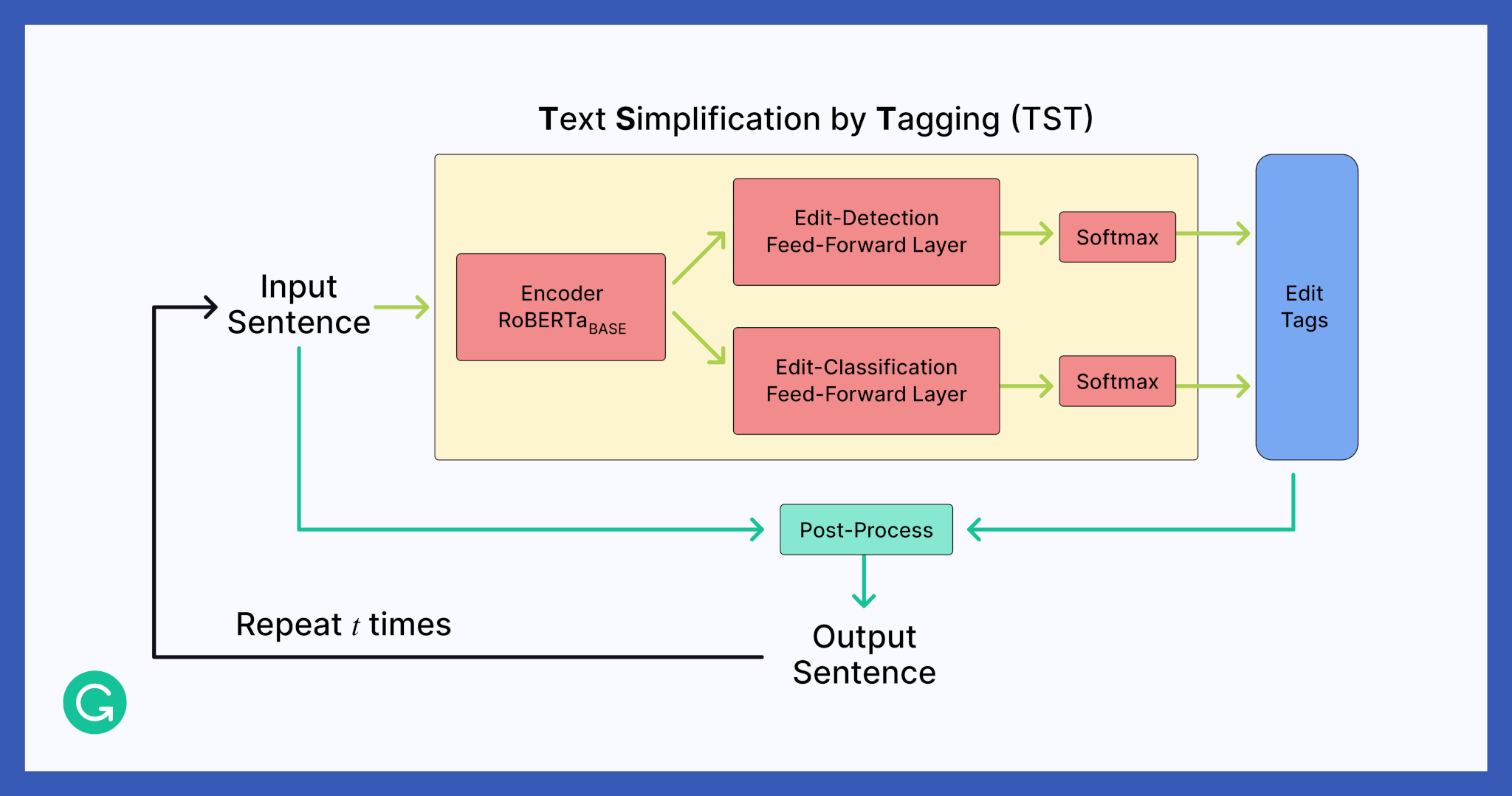
We use a pre-trained RoBERTaBASE Transformer (Liu et al., 2019) as the encoder, which gives us additional context about the words in the text. The encodings are passed to two concurrent feed-forward layers, followed by corresponding Softmax layers. From there, the model outputs edit-operation tags, applies them, and may undertake additional iterations.
Data
Compared to GEC, there is not a wide selection of high-quality datasets that can be used to train and evaluate models for text simplification. The only publicly available dataset consists of automatically paired sentences from English Wikipedia (EW) and Simple English Wikipedia (SEW). This dataset is also the common benchmark for the task, so it was important for us to use it for evaluation. The Wikipedia data has around 384,000 sentences total; for training, we looked into how we could increase the number of examples.
Text simplification is (ironically, perhaps) a complex task. With a problem like GEC, the space of possible “correct” sentences is relatively small. But with text simplification, there are many different sentences that could be considered a simpler version than the original. Thus, we sought to provide our models with a wider range of target simplified sentences to learn from.
The first way we generated more sample data was using a technique called back-translation. By taking a sentence in one language, translating it to a different one, and then translating it back into the original language, you’ll typically get a new sentence. Using high-quality bilingual models, we took each simplified sentence from the Wikipedia dataset and translated it from English to French, and then back to English—and did the same thing with German. This technique tripled the amount of training data we had to work with.
The other technique we used for generating training data is called ensemble distillation. In machine learning, an ensemble approach combines the predictions from several different models. When the output from an ensemble approach is itself used as training data, this “distills” the models’ knowledge by feeding it back into the system. We built an ensemble of three variants of our text-simplification model:
- Our text-simplification-by-tagging base model, trained on the original Wikipedia data
- The same base model, but fine-tuned on the GEC task ahead of time
- Our text-simplification-by-tagging base model, trained on the Wikipedia data and the back-translated data
We used this ensemble to make predictions on the original Wikipedia dataset and with that output, we doubled the training data. Unsurprisingly, including this ensemble training dataset gave our model performance an even bigger boost than including the back-translated data.
Inference tweaks
One of the advantages of tagging instead of rewriting is that we have more precise control over the model’s predictions. For example, we can decide to boost or decrease the model’s confidence about applying certain tags. Building on our work on GECToR, we added some confidence biases to the KEEP and DELETE tags.
Most text simplification systems use a large number of tuning hyperparameters, making them more complex and slower on inference. We avoid this and achieve additional robustness by tuning the prediction confidences only for KEEP and DELETE, which are the most commonly used edit operations for text simplification.
And as discussed earlier, we added a sentence-level minimum edit probability threshold, which enabled the model to predict only the most confident edits and led to better performance.
Evaluation metrics
To report results, we used two widely adopted metrics for the text simplification task: FKGL (Kincaid et al., 1975) and SARI (Xu et al., 2016b).
FKGL (Flesch-Kincaid Grade Level) is used to measure readability, with a lower score indicating a simpler text. Each point on this scale represents a reading grade level. FKGL doesn’t use source sentences or references for computing the score. It is a linear combination of the number of words per sentence and the number of syllables per word.
On the other hand, SARI (System output Against References and against the Input sentence) evaluates the quality of the model by looking at which words were inserted, kept, and deleted to simplify the input sentence. For each complex sentence, SARI compares the model’s simplified version with the references in the test data. The more the model’s ADD, KEEP, and DELETE operations match the edits in the reference sentences, the higher the SARI score.
Results
We evaluated TST against three canonical test sets taken from the Wikipedia data. We presented a baseline model without any optimizations alongside the final model, where we added enhancements like GEC initialization, data augmentation, and inference tweaks. We compared both models against the state-of-the-art system for text simplification (Martin et al., 2020b). This system is notable for having many hyperparameters, making it quite large and slow but providing a lot of flexibility on tuning.
In terms of the FKGL score, TST performed better than the state-of-the-art system by 0.23 points on average, indicating that the simplifying edits made by our models are easier to understand. Looking at the SARI metrics, we achieved a competitive score simply by using our baseline architecture trained on the standard Wikipedia dataset. When we added optimizations like data augmentation with ensemble distillation and especially the inference tweaks, we achieved within 1 SARI point of the current state of the art.
Digging deeper into the results, some interesting observations emerged: Our models scored higher on ADD and DELETE SARI operations, while existing text simplification systems scored higher on KEEP. This shows that earlier models learned a safe but inefficient strategy of simplification that leans heavily on copying the source sentences. By contrast, our model made more changes (which sometimes caused its results to be penalized by SARI for moving too far from the references). Prior works have much longer output sentence lengths (average of 19.26 words) compared to ours (average of 16.7 words), which is another indication that our models employed a more aggressive simplification strategy than their predecessors.
Finally, we looked at the inference time for our approach, compared to previously proposed text-simplification systems. Our models were 11.75 times faster than pure BART, which is the core component of the current state of the art (Martin et al., 2020b). More details can be found in our paper.
Conclusion
Our approach achieved great results with an architecture that is inherently lightweight, parallelizable, and explainable, making it better suited for industry applications than the existing research. Yet text simplification remains a very open problem. The evaluation metrics are far from perfect, and the public datasets are under-resourced. We were able to overcome this somewhat by using techniques to augment our training data. However, the qualitative results show room for improvement and the potential for future work on text simplification.
With TST, we explored how the approach of training models using edit tags rather than full-text rewrites can be extended to problems outside of grammatical error correction. We are continuing our research into how we can use the proposed technique to approach other NLP problems in the future.
NLP research is core to everything we do at Grammarly as we explore ways to help people communicate more clearly, concisely, and effectively. Check out our open roles to learn more about opportunities for applied research scientists and ML engineers.






