

This article was co-written by applied research scientists Vipul Raheja and Dhruv Kumar.
Introduction
At Grammarly, we’re always exploring ways to make the writing and editing process better. This has included extensive use of large language models (LLMs), which got us wondering: What if we made LLMs specialize in text editing?
We’ve noticed a gap in current research: LLMs are generally trained for a broad set of text-generation tasks. However, for more well-scoped tasks like text editing, instruction tuning can be a very effective way to build higher-quality, smaller, and more performant LLMs. These LLMs, in turn, can be higher-quality, intelligent writing assistants. This approach involves refining a base LLM with a dataset of well-crafted examples, including instructions and corresponding text inputs and outputs, a process known as instruction fine-tuning. But critically, its success depends on the quality of these instructional examples.
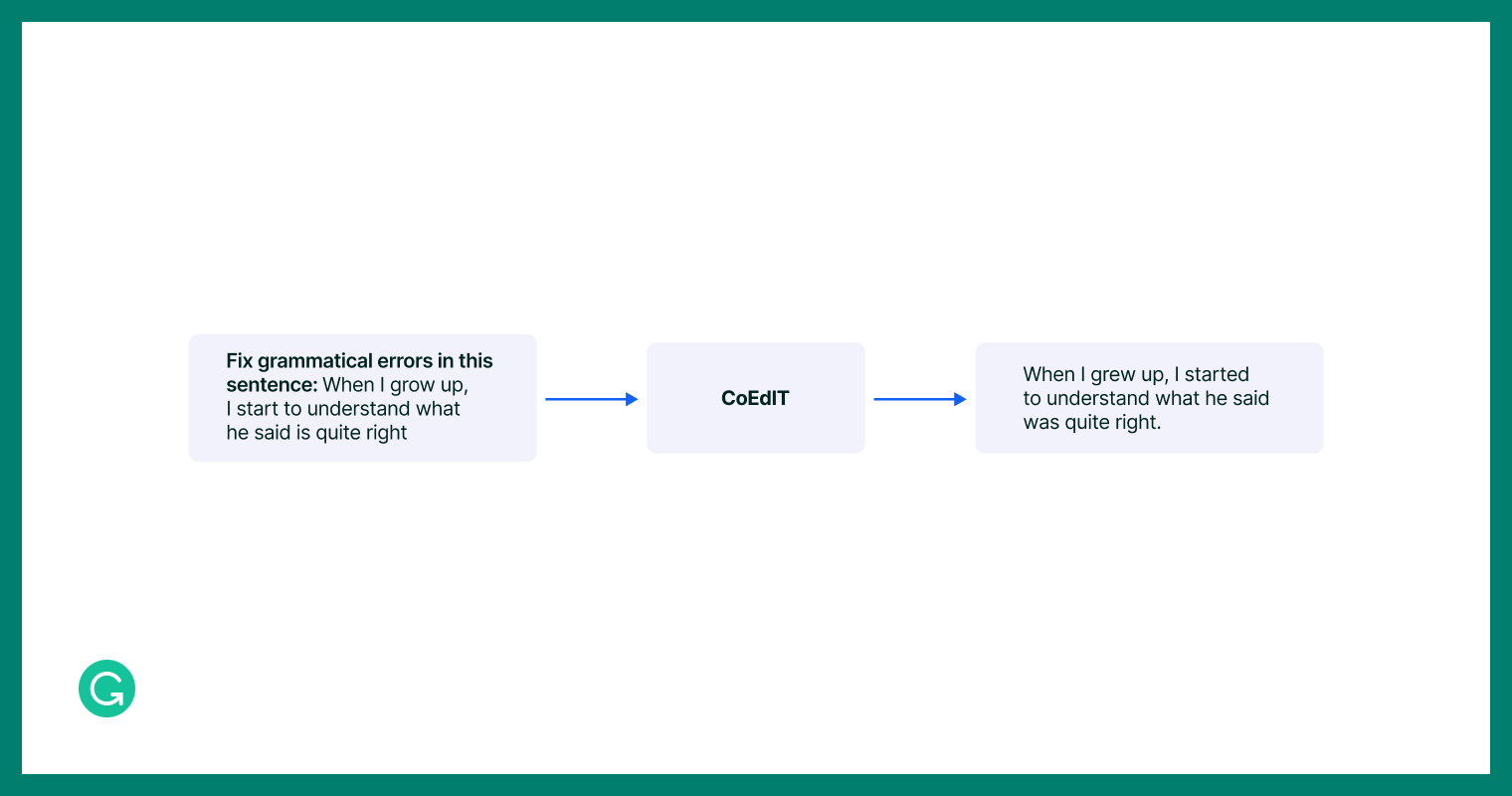
An example of a single instruction-tuning data row.
So we compiled a dataset for instruction tuning on text editing examples to build CoEdIT, an instruction-tuned LLM for text editing. CoEdIT is an open-source LLM that is not only up to 60 times smaller than popular LLMs like GPT-3-Edit (175 billion parameters) and ChatGPT, it also outperforms them on a range of writing assistance tasks. In this post, we’ll summarize the results from our paper, “CoEdIT: Text Editing by Task-Specific Instruction Tuning,” which was accepted as a Findings paper at the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP 2023). It was co-authored with our collaborators Ryan Koo and Dongyeop Kang (University of Minnesota) and built on our previous work on IteraTeR: NLP Text Revision Dataset Generation and DELIteraTeR, a Delineate-and-Edit Approach to Iterative Text Revision. We’ll share how we built the CoEdIT fine-tuning dataset and how we constructed and evaluated the CoEdIT models, all of which are publicly available in the CoEdIT repository on GitHub.
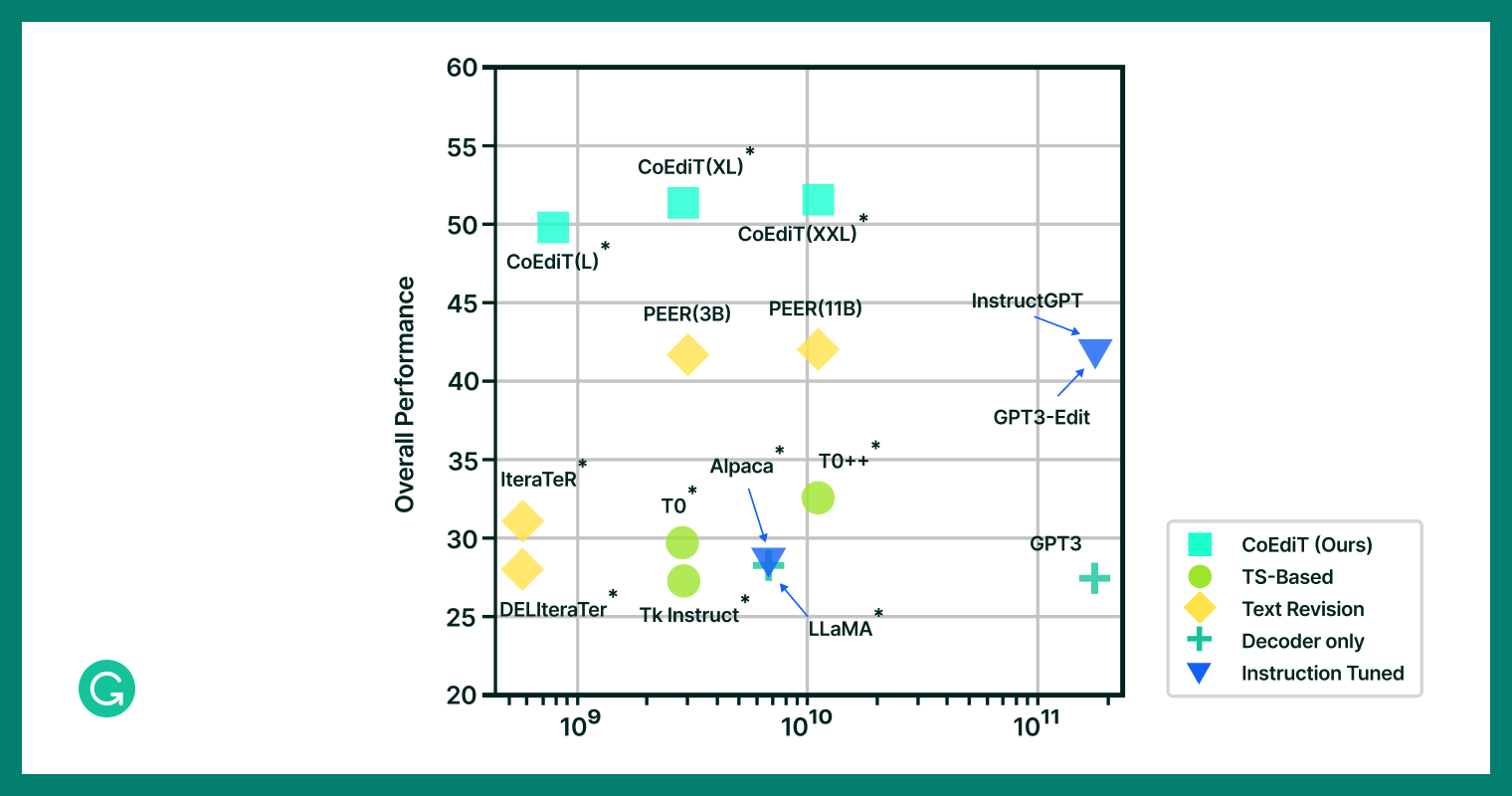
Model performance versus size: larger models notably fall short in text editing performance compared to CoEdIT.
What we did
In this work, we began by addressing some of the gaps present in developing general-purpose text editing models using LLMs, as they significantly limited model effectiveness, performance, or usability:
- Lack of training with instruction tuning, which limited their usability and interpretability
- Training on undersized models, which limited their capabilities
- Not training on task-specific datasets (i.e., training on highly general datasets), which limited their quality
- Lack of public availability (i.e., not open-source), which limited their usability and reproducibility
We thought that fine-tuning LLMs using text editing tasks, rather than a broader list of general tasks, could do a lot to address the gaps we identified. General tasks represent a “sparse task distribution”—anything from “summarize this text’” to “translate this text to French,” which are both useful but not very closely related to one another. We might think of a human that could handle these tasks as having a “generalist” skill set. On the other hand, a more specific, or “dense,” task distribution would cover tasks that are more closely related, like “paraphrase this text” and “make this text coherent.” In a human, we might attribute a set of skills like this to a text editing specialist (i.e., an editor).
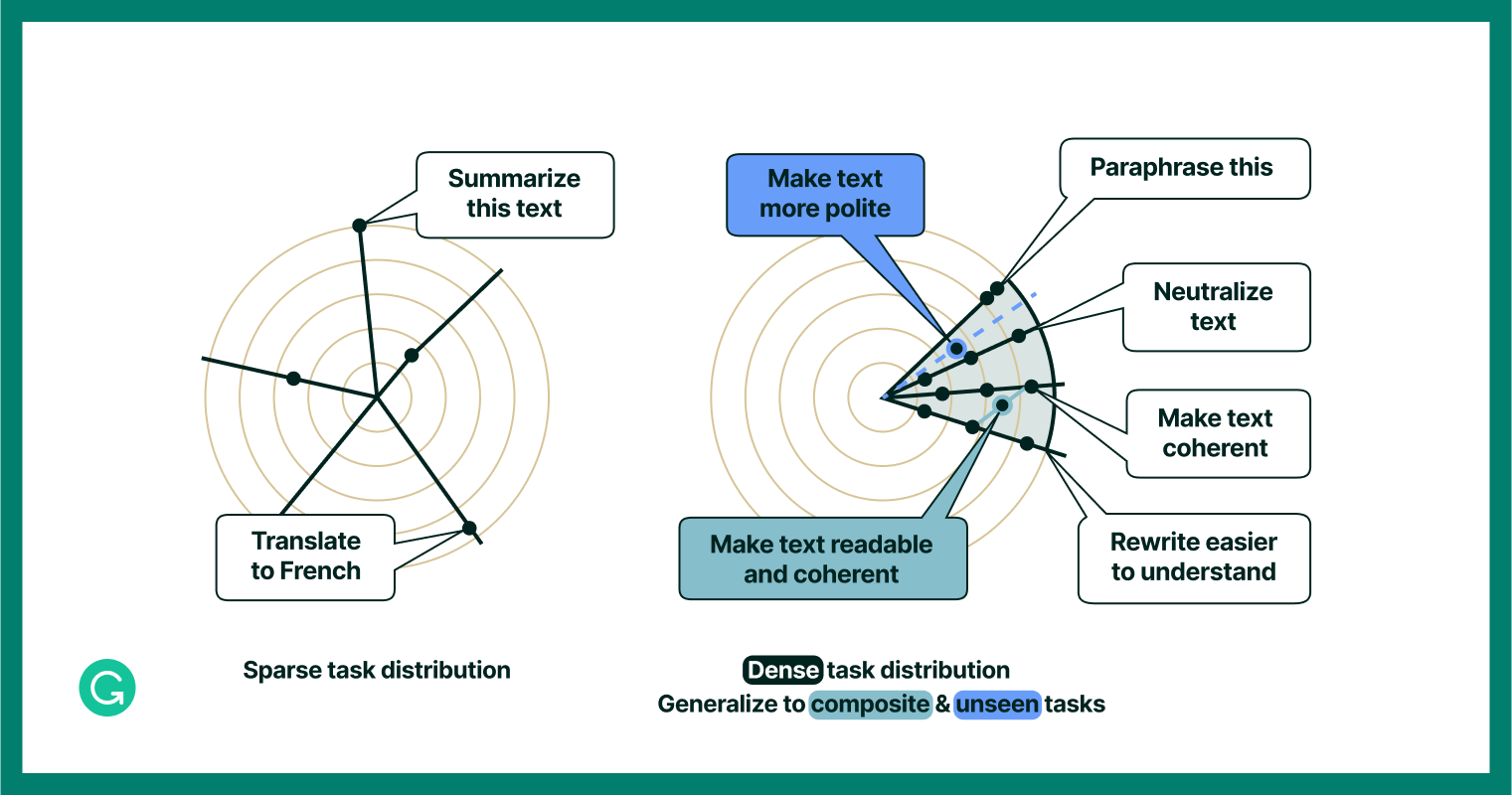
An illustrative example of how dense training task distribution can lead to better generalization to composite and unseen tasks.
The opportunity, then, was to use instruction tuning to turn CoEdIT into a text editing specialist. And just like a human specialist, we thought that performing well on “adjacent” tasks—tasks that are close to, but not exactly, its specialty—would be significantly easier for CoEdIT than it would be for an LLM generalist.
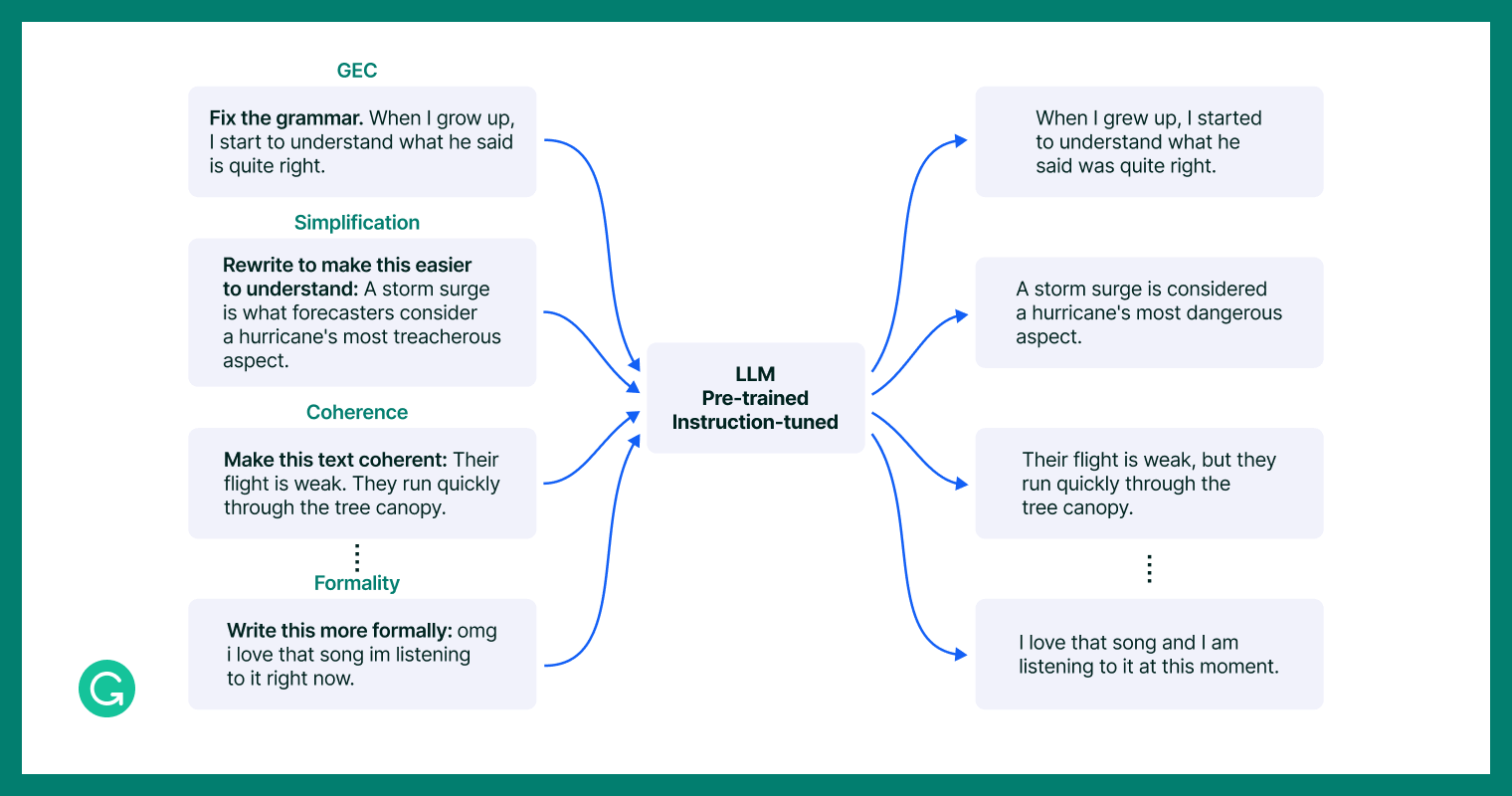
Example tasks that the instruction-tuned CoEdIT model, as a “specialist” in the dense task space of text editing, might undertake more effectively.
Building the training dataset
This begs the question: How would we achieve a dense text editing task distribution for the CoEdIT dataset?
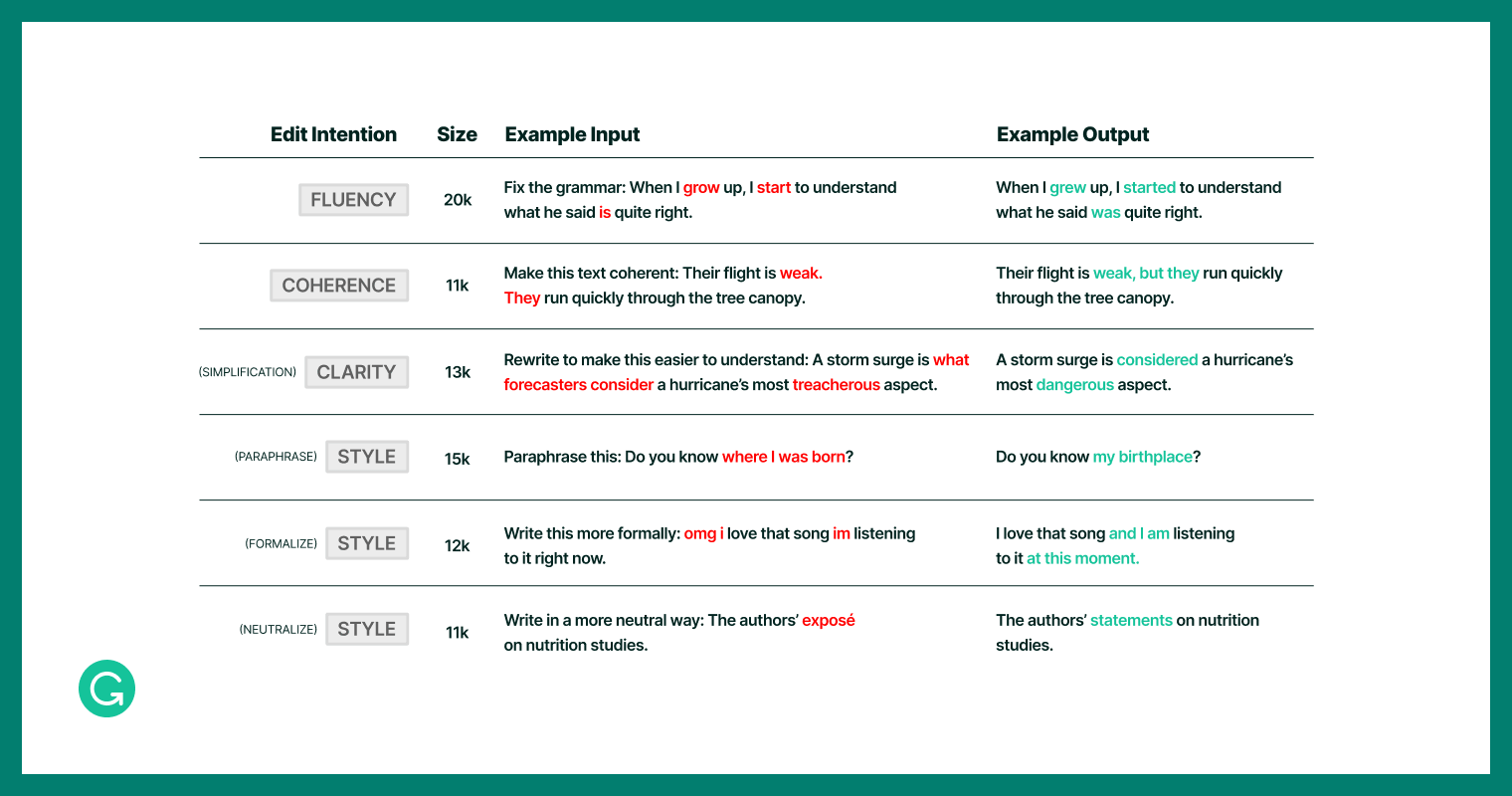
To construct our dataset, we built upon the IteraTeR+ dataset1, which contains a variety of text editing tasks while focusing on non-meaning-changing edits. We translated edit categories—Fluency, Coherence, Clarity, Style—into natural language instructions, such as “Make this more coherent.” To achieve consistency, particularly in subjective areas like style, we introduced specific sub-intentions like Paraphrasing, Formality Style Transfer, and Neutralization. Additionally, to make sure our model would understand different phrasings of the same actual instruction (i.e., “write” versus “rewrite” a sentence), we created paraphrases of instruction templates and added those to the dataset.
Training the model
Once the work of creating the dataset was complete, we fine-tuned a few different versions of a pre-trained FLANT5<sup>2</sup> LLM (L: 770 million parameters, XL: 3 billion parameters, XXL: 11 billion parameters) with the CoEdIT dataset. We named these models CoEdIT-L, CoEdIT-XL, and CoEdIT-XXL respectively.
Evaluating performance
Judging writing and edit quality is a naturally subjective process: Any one writer’s opinion might differ from another’s. But in a larger aggregate, there is often meaningful consensus.
Given this subjectivity, and the lack of accepted quantitative measures for some of the qualities we were interested in, we devised both qualitative and quantitative benchmarks of how well CoEdIT performed.
Models compared against
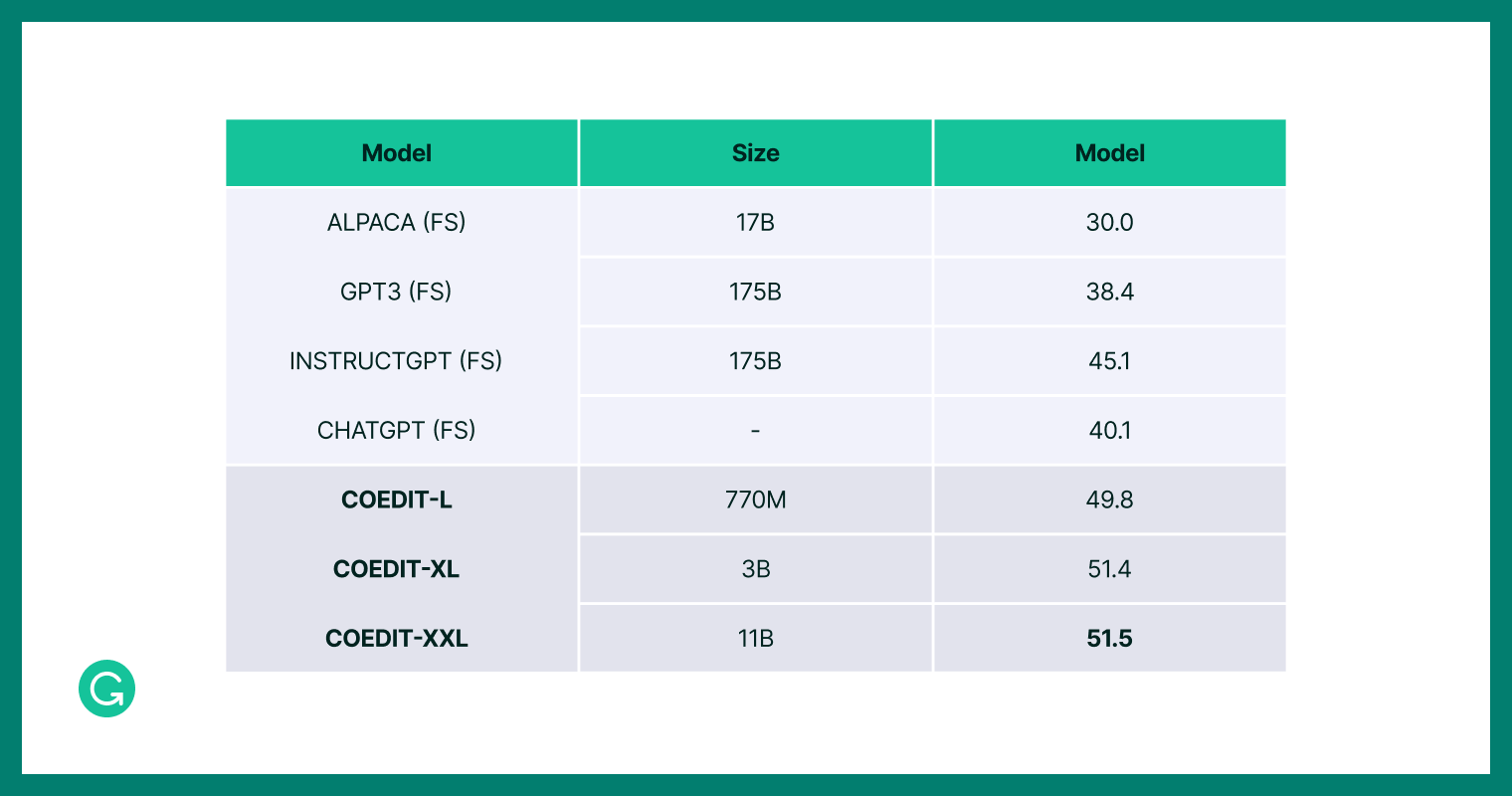
To figure out just how well CoEdIT did, we needed something to compare against. So, we devised four comparison groups:
- A no-edit baseline: Outputs are simply copies of the source, with the instruction removed.
- Supervised text editing models: Supervised models trained on iterative text revision tasks. See the IteraTeR Iterative Text Revision and DELIteraTeR, a Delineate-and-Edit Approach to Iterative Text Revision Grammarly blog posts for more.
- Instruction-tuned LLMs: LLMs that have been instruction-tuned, albeit on different instruction corpora than CoEdIT, like ChatGPT3 and GPT3-Edit4
- Decoder-only LLMs: LLMs with no instruction tuning, like GPT-35 and LLaMA6
To see the full details of the models used, and the conditions they were evaluated in, please refer to the full paper.
Quantitative analysis
Representatives from each of these four comparison groups, along with CoEdIT, were then evaluated against standard test sets from a variety of text editing benchmarks7. We found that CoEdIT achieves state-of-the-art performance on multiple benchmark test sets, spanning syntactic, semantic, and stylistic edit requirements. But perhaps equally interesting, we found that even our smallest model, CoEdIT-L, outperforms other supervised text editing models, instruction-tuned models, and general-purpose LLMs. And it does so with anywhere between 12 times and 60 times fewer parameters on both automated and manual evaluations.
Qualitative analysis
To complement our quantitative analysis, we performed human evaluations to understand human perception and preference of edits generated by CoEdIT. Our expert evaluators compared the outputs of two models, CoEdIT-XL (3 billion) and GPT3-Edit (175 billion), for fluency, accuracy, and preservation of meaning. The results were clear: Evaluators preferred CoEdIT’s output 64 percent of the time, compared to just 10 percent for GPT3-Edit.
But we were interested in more than just how CoEdIT performed on familiar tasks. How would it fare with “adjacent” tasks it hadn’t encountered before? We tested it with two related tasks that were new to CoEdIT: sentence compression and politeness transfer. On both, we found that CoEdIT outperformed competitors, including GPT3-Edit. As we’d expected, CoEdIT was an expert at adapting to new tasks related to its text editing specialty due to task-specific instruction tuning.
Evaluating performance on composite tasks
Real-world editing tasks often involve editing sequences, like “make the text simpler, paraphrase it, and make it formal.” To assess CoEdIT’s aptitude for these “composite” editing tasks, we enriched its training set with multi-part tasks, like “grammatical-error-correction with paraphrasing and simplification.” This led to the development of CoEdIT-Composite, trained on this set of composite tasks.
In the absence of a benchmark for composite tasks, human evaluators compared this new model’s output with that of CoEdIT-XL and GPT3-Edit across the same prompts. CoEdIT-Composite was preferred, outshining GPT3-Edit (38 percent to 34 percent) and the original CoEdIT-XL (34 percent to 21 percent). However, the closer margins signaled opportunities for future enhancements, so we’re excited to continue this promising line of research with composite-tuned CoEdIT.
Looking forward
It has been clear for some time that LLMs will be an enormous aid for intelligent writing assistance. CoEdIT makes this use case significantly more accessible with its state-of-the-art performance, small size (up to 60 times smaller than comparable performers), ability to generalize to adjacent and composite editing tasks, and open-source models and data, which you can access in the CoEdIT repository.
With further improvements to our training methods, we believe CoEdIT will be able to help with even larger and more complex parts of the editing process. This will include enhancements like expanding its ability to handle longer texts, and better accounting for prompt sensitivity in training and testing the model, making CoEdIT an even more capable natural-language-based writing assistant.
With research explorations like CoEdIT, in addition to our core product efforts, Grammarly remains committed to its mission of improving lives by improving communication. If that mission, and solving problems like these, resonates, then we have good news: Grammarly’s NLP team is hiring! We’re passionate about exploring and leveraging the potential of LLMs and generative AI to make writing and communication better for everyone, and you can check out our open roles for more information.
1Zae Myung Kim, Wanyu Du, Vipul Raheja, Dhruv Kumar, and Dongyeop Kang. 2022. Improving iterative text revision by learning where to edit from other revision tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9986–9999, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
2 Hyung Won Chung, Le Hou, S. Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Wei Yu, Vincent Zhao, Yanping Huang, Andrew M. Dai, Hongkun Yu, Slav Petrov, Ed Huai hsin Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc Le, and Jason Wei. 2022a. Scaling instruction fine-tuned language models. ArXiv, abs/2210.11416.
3 Using OpenAI APIs for inference
4GPT-3 also offers a text Editing API (the “Edit API”, using the text-davinci-edit-001 model), referred to here as GPT3-Edit, which is usable for editing tasks rather than completion, making it directly comparable to the tasks we trained CoEdIT on.
5Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners.
6 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix,Methods in Natural Language Processing, pages 584– 594, Copenhagen, Denmark. Association for Computational Linguistics
7 See the paper, section 4.2, for details on test sets and what they test.






