

We’re happy to announce UA-GEC 2.0, the second version of Grammarly’s publicly available grammatical error correction (GEC) dataset for the Ukrainian language. UA-GEC is the first-ever GEC dataset for Ukrainian, with version 1.0 released in January 2021. You can access UA-GEC 2.0 here.
While there are multiple GEC datasets for English, historically, many languages, including Ukrainian, haven’t had any publicly available GEC datasets. Grammarly has a deep connection to Ukraine—our company was founded there. Therefore, our team was eager to create a useful resource that would enable the local and international NLP communities to do robust multilingual research and modeling for the Ukrainian language. You can read our original blog post about the dataset to find out more about the motivation behind creating it, the details of the data collection and the data annotation processes, and the statistics and release information for UA-GEC 1.0.
In 2021–22, we collected and annotated more textual data, and made further improvements to the corpus. UA-GEC 2.0 differs from the original version of the corpus in three major ways:
1 We increased the size of the corpus
The new version contains 1,872 texts (33,735 sentences and 500,618 tokens) written by 828 unique contributors. This is 1.6 times more than the version 1.0 corpus.
We collected the data from Ukrainian speakers using the same data collection web page as the original version of the corpus. As a reminder, volunteers were prompted to complete one of the following tasks:
- Translate a short fragment of text from a foreign language into Ukrainian
- Write a message on one of twenty provided topics
- Submit original writing (from anywhere), ideally without proofreading
The distribution of task choices in version 2.0 is as follows:
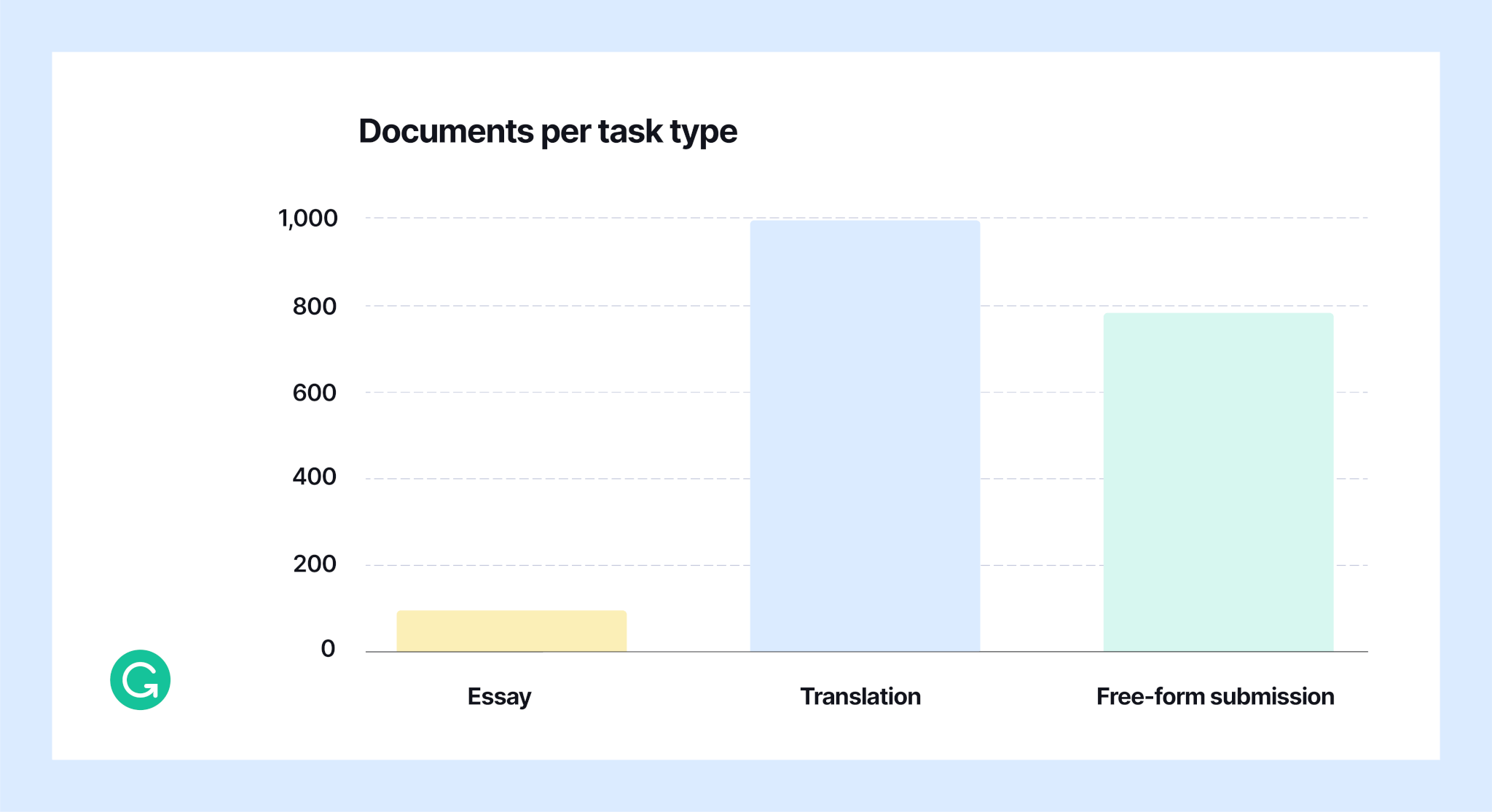
As can be seen, most people chose the translation task, which ensured a variety of classical texts in the corpus. Also, a large number of participants completed the third task—submitting their own texts—which helped to expand the number of styles and genres in the corpus, ranging from casual social network chats to formal and creative writing.
2 We introduced a more fine-grained categorization of errors
The original version of UA-GEC contained four error categories: grammar, spelling, punctuation, and fluency. For the second version, we developed a more fine-grained categorization, with grammar and fluency being subdivided into thirteen and five subcategories respectively. We introduced an additional subcategory, titled “other,” for errors that do not fall into any of the new subcategories.
| Category | Subcategories |
| Grammar | Case, Gender, Number, Aspect, Tense, VerbVoice, PartVoice, VerbAForm, Prep, Participle, UngrammaticalStructure, Comparison, Conjunction, Other |
| Spelling | No subcategories |
| Punctuation | No subcategories |
| Fluency | Style, Calque, Collocation, PoorFlow, Repetition, Other |
The categorization of UA-GEC 2.0 includes subcategories for grammar and fluency that were not available in UA-GEC 1.0.
Fine-grained categorization allows for detailed analytics based on types of errors. For example, “Do secondary language speakers make more Case or Gender mistakes?” Furthermore, error-correction models can be trained for specific types of errors (this may be useful in an instructional setting).
3 We prepared two separate versions of the corpus: GEC-only and GEC+Fluency
Being highly subjective, fluency is a tricky category, as different annotators may provide different fluency edits for the same text. To give corpus users an opportunity to exclude this category from their training/test data, we created two separate versions of the corpus: GEC-only and GEC+Fluency. After removing fluency edits, we reviewed the corpus to ensure that the remaining corrections are grammatically accurate and complete.
Release
We’ve released the UA-GEC 2.0 dataset on GitHub: https://github.com/grammarly/ua-gec. The dataset is available under a CC BY 4.0 license, which allows users to remix, transform, and build upon the material for any purpose, even commercially.
Additionally, we’ve released a Python package that simplifies processing annotated text files and already includes all the corpus data. Refer to the documentation for more details.
We are excited about the opportunities this dataset can provide for the NLP communities, and hope that it will be useful for Ukrainian language research as well as support the creation or improvement of tools for correcting grammatical errors in Ukrainian.
Interested in working on NLP at Grammarly? We’re currently hiring applied research scientists, machine learning engineers, and many other roles. Check out our openings page for opportunities to help millions of people around the world communicate with one another.






