

This article was co-written by Platform Engineers Stanislav Grichkosey and Artur Kiryiak.
We’re excited to share that Grammarly is in the process of scaling to multiple AWS regions as part of a massive infrastructure project on our Platform team. This will allow us to bring our neural networks and APIs closer to the user so we can show some amazingly responsive user interfaces. Because we’ve moved to a multi-environment infrastructure at the same time, this work has also helped Grammarly achieve its enterprise-grade security compliances and certifications, such as SOC 2 (Type 2) and ISO certifications.
Before: One AWS account per team, single region
Our legacy AWS infrastructure covered one region and three availability zones, and it was set up at the team level. There was one AWS account per team and typically one VPC per account. This meant that most of the time, a team’s environments (like QA, production, and pre-production) would share the same VPC, with isolation handled through security groups. Cross-VPC communication was done through peering.
As Grammarly grew, we realized that this was an unsustainable solution for several reasons:
- Team-based AWS accounts: Because teams are constantly changing, this method resulted in a lot of administrative overhead and didn’t provide great visibility into ownership and billing.
- AWS limits: As we scaled, we were starting to hit AWS-specific limits (per AWS account, per VPC, or per Availability Zone). We wanted to avoid micromanaging over 2,500 IAM permissions to segregate environments within each account.
- Multi-environment AWS accounts: To continue to build on our security commitment and meet our compliance requirements as we scale, we needed to isolate and segregate our environments.
- Hard-to-control VPC peerings: VPC peering is an easy and fast way to connect VPCs, but if you have hundreds of AWS accounts and VPCs, it becomes hard to manage the complexity.
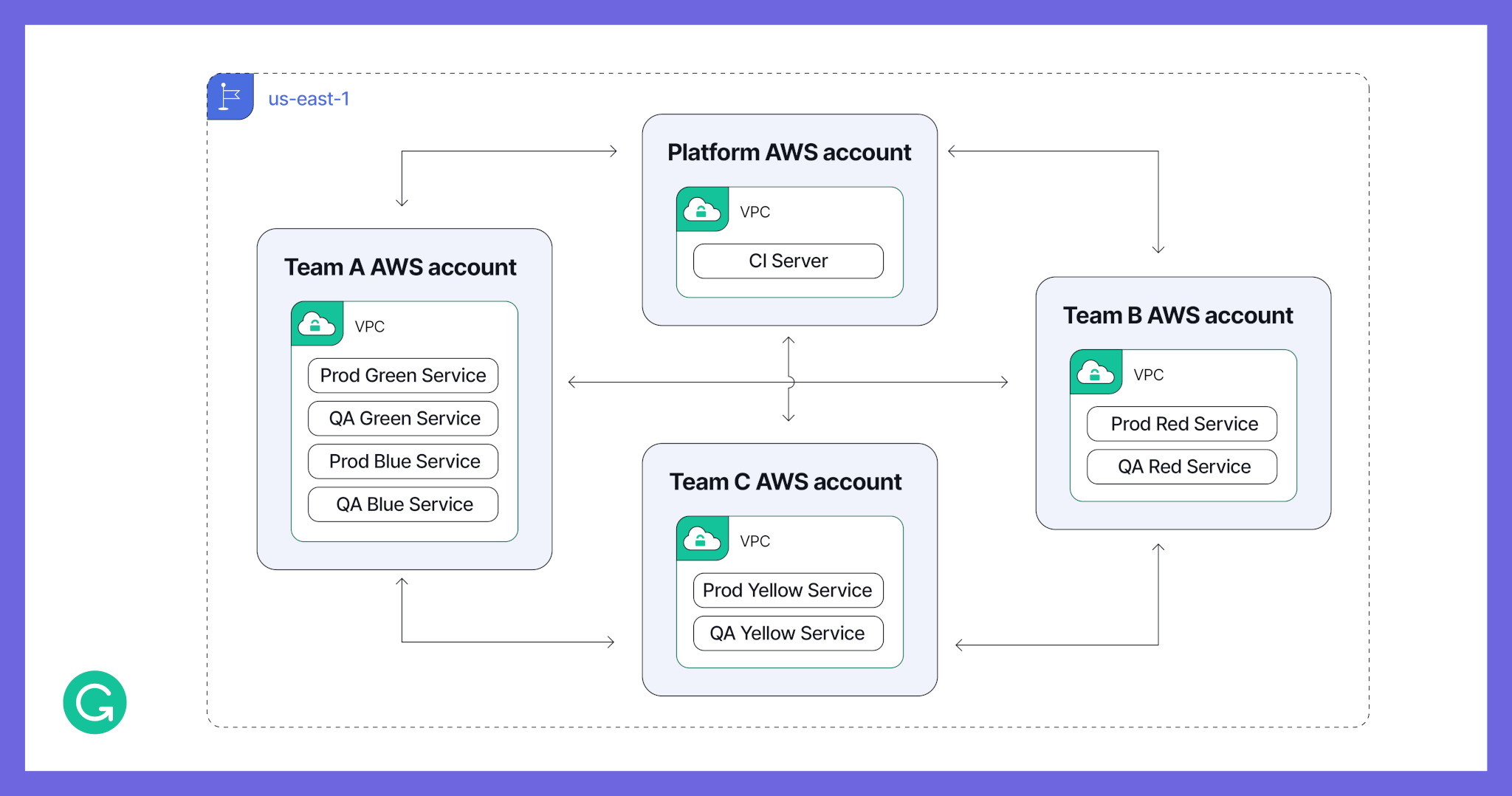
Here’s a basic diagram showing what our infrastructure looked like previously. Boxes show AWS accounts and their corresponding AWS VPCs, connected by VPC peerings.
As we developed a plan to address the short-term needs of our growing organization, we were thinking ahead to how we can support multi-region in the future. Among different less granular options, we decided to stay flexible in terms of potential future growth by segregating our infrastructure into the small-enough blocks that allow us to build a flexible architecture.
After: One AWS account per environment per project, multi-region
We’re handling multiple environments by having each AWS account host a single environment for a single project. This supports the least privilege principle, which Grammarly adheres to, and lets us easily apply different service control policies based on the needs of a particular project. For example, we can have fewer restrictions in a QA environment. We group and manage environments using AWS organizational units (OUs).
Furthermore, we’ve decoupled AWS accounts from VPCs. This provides flexibility and lets us keep services linked together when needed. Some parts of the product require the lowest possible latency in their communication but still need to be administratively isolated and reside in different AWS accounts. We don’t want to reduce their performance, so we keep them in a single shared VPC. This also helps lower our traffic costs.
Finally, by decoupling VPCs from AWS accounts and making use of VPC sharing, we’ve been able to create one central networking AWS account per environment. This account facilitates the management and debugging of network issues, letting us delegate network ownership to the dedicated team.
To communicate between VPCs, we’re now using Transit Gateways instead of VPC peering. Transit Gateways essentially act as routers and enable a simplified configuration, which is especially important for managing cross-region communication. By setting up a proper IP addressing schema and benefiting from route summarization, we can define routes once, rather than constantly needing to create and maintain peering networks. With the addition of PrivateLinks, which we use to connect certain cross-environment services, we achieve a flexible, secure, and scalable network.
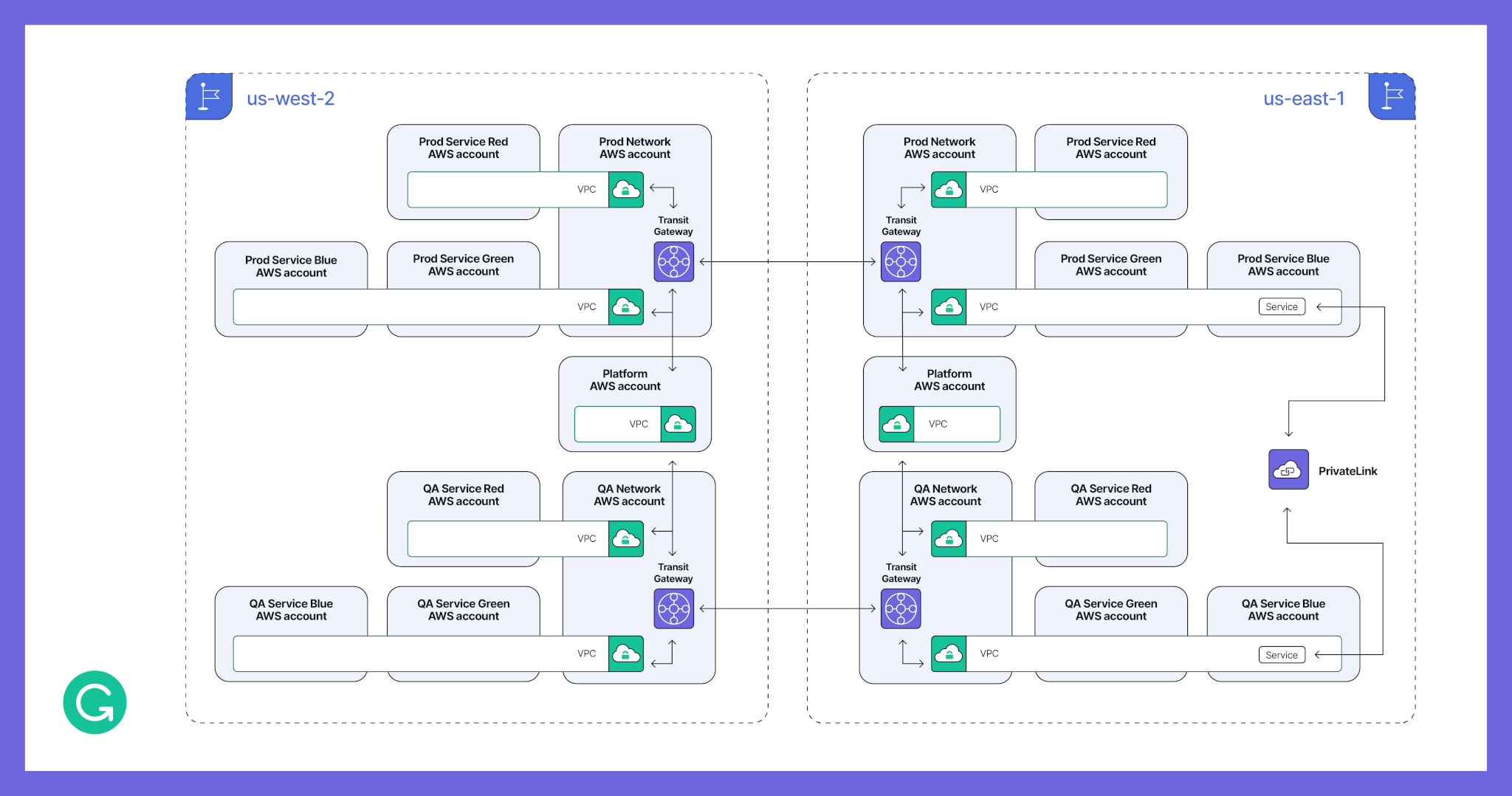
Here’s a diagram of how we support multi-environment and multi-region in AWS. A full mesh of transit gateways will handle cross-VPC and cross-region traffic. The routes on each transit gateway will define the traffic flow.
Dynamic scaling
Clearly, not every project needs the same-sized VPC. One important element of this infrastructure is that any project should be able to scale to the resources that it needs (but also not waste resources). Therefore, we shard IPs into different sizes, like small, medium, and large, to ensure that every project gets the resources it needs. As projects grow in scope, engineers can always request a new shard size. We don’t need to recreate and redeploy everything—we can simply add another network range to the VPC.
Migration challenges
An infrastructure change this big takes a long time (it’s still ongoing) and requires many operational changes as well as technical. Throughout the planning and implementation, we worked closely with our security and compliance teams to ensure that our infrastructure continues to be built to protect our users’ data according to high industry standards.
Of course, there were many components to connect and network rules to configure. When migrating each service, we manually created a cross-services communication map to avoid migrating legacy routes that are no longer needed. When it came to implementing that map, we wanted to avoid route micromanagement. So just like the internet, we’re doing route summarization. You can think of this as aggregating one or more smaller networks into a bigger network range. We have dedicated network blocks for each region and set global routes for these blocks. That way, we don’t need to specify the route to each VPC in all the intermediate Transit Gateways.
To make the migration go smoothly without a large tax for our developers, we’ve also invested in significantly improving our processes for provisioning AWS accounts. Our internal toolset, based on Terraform and custom Go applications, lets us avoid code duplication when setting up multiple regions and environments and gives us the ability to create new AWS accounts automatically, with all required AWS services preconfigured in around two hours. It’s not only automated, but also self-service for engineers, who can create an account by simply submitting a form.
Throughout the migration, we’ve needed to be careful to clearly define each project and its dependencies when we are dedicating an account to it—keeping in mind that there will always be some services that don’t fit in the model and which require some extra work to scale to multi-region. For example, consider common testing tools (such as Selenoid) that are used by different teams. It might be tricky to allocate such “shared responsibility” services into an “isolated by default” infrastructure.
To multi-region and beyond
With this infrastructure migration, we are ready to scale to at least five regions, bringing super low latency to all our users and allowing us to build new kinds of fluid, instantaneous experiences. And everything is isolated by default: environments, projects, and networks.
What else is coming in the future? One thing we’ll be investigating is how we can migrate to IPv6—and maybe, down the road, even a multi-cloud architecture. Interested in working on infrastructure projects that help millions of people wherever they write? The Platform team is hiring! Check out our roles here.






