

In recent years, rapid developments in AI have made it possible for anyone with a basic background in computer science to download a model toolkit from the web, feed in some data, and start producing results. The democratization of machine learning (ML)—and especially deep learning (DL)—is an important advancement, but it’s crucial to remember that the quality of ML still depends largely on the datasets we use to develop our models.
As Grammarly’s language data manager, I have a close relationship with the datasets we develop—and how we can make sure they are setting us up to create an inclusive, sophisticated product. While building the systems that power Grammarly’s writing assistant, we’ve studied the kinds of assumptions about data that can hinder model performance down the line. Last month, at the Lesbians Who Tech Debug 2020 Summit, I had the opportunity to speak about some areas we watch out for—along with possible solutions. In this article, I’ll share my advice while walking through the steps of building a high-quality NLP dataset.
The need for quality data
At Grammarly, we power our writing suggestions with AI—specifically ML, DL, and a subfield called natural language processing (NLP). We use modeling to tackle various problems, from analyzing the sentiment of a piece of text to offering suggestions for clarity improvements. Below you can see a diagram showing the basic stages for how we provide suggestions to our users.

A variety of technologies and expertise goes into continually building our AI, but one often overlooked component is the annotated data used to train, tune, and evaluate the systems. (A corpus—plural, corpora—is a dataset or collection of texts.) An annotated corpus contains text that has been labeled or transformed (annotated) by people working off of a shared set of guidelines. Many ML and DL models need annotated data to learn from—the annotations “teach” the model how to react depending on the task and input data. Here are examples of what types of annotations may be collected.
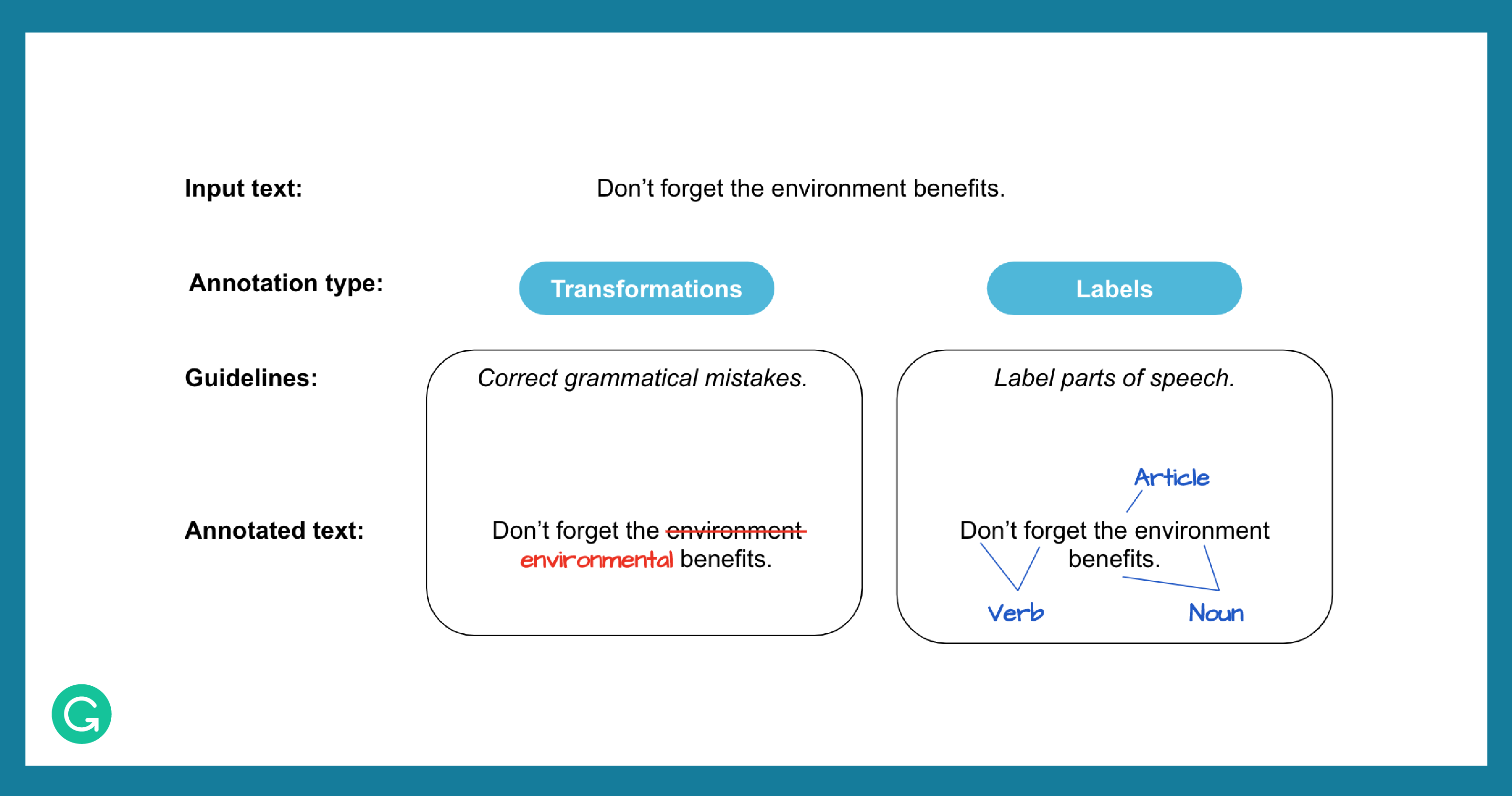
It’s vital to prevent issues in annotated datasets—so we can safeguard against failures in the models. The four primary problems that can arise in a corpus are:
- Data scarcity: There aren’t enough examples of the phenomenon in question.
- Low quality: The annotations are unreliable or inconsistent.
- Overfitting: The corpus and annotations represent a limited perspective.
- Dead angles: There are types of data or annotations we don’t know about, which are absent from the corpus.
When these issues occur in the data, the model in turn will not have a clear signal about the targeted phenomenon and will not be able to generalize to new input data. It’s critical to get to know your data and eliminate any assumptions that could lead to these oversights and poor performance when the model encounters real-world scenarios.
Throughout this article, I’ll pull examples from grammatical error correction (GEC), a core area of focus in the NLP community and a central functionality for Grammarly. GEC uses a combination of ML, DL, and NLP techniques to identify and correct spelling, punctuation, and grammatical mistakes. (You can read more about some recent advances in Grammarly’s approach to GEC here.)
Here is an example showing some GEC suggestions in our product.
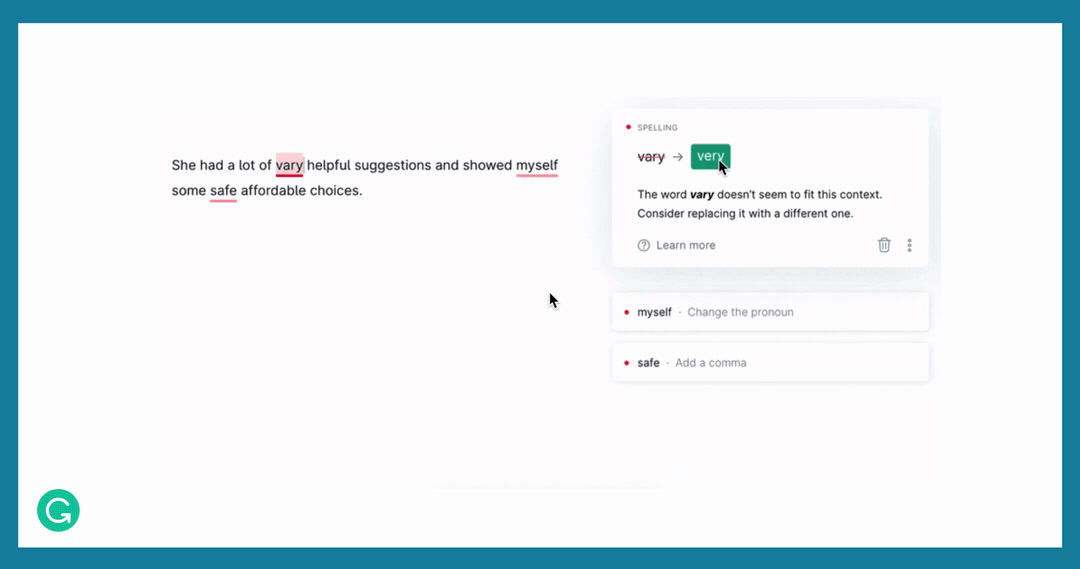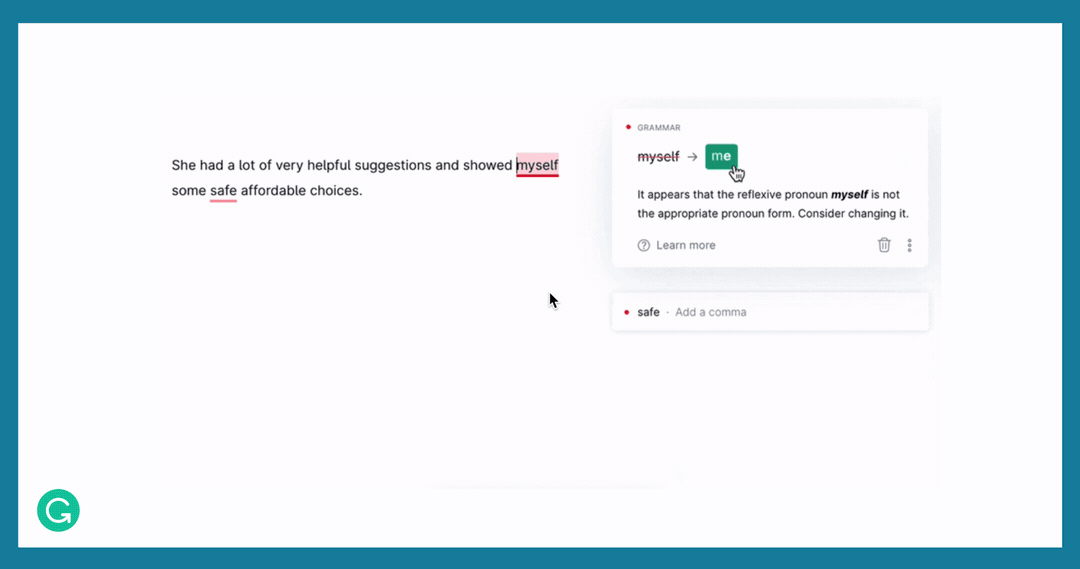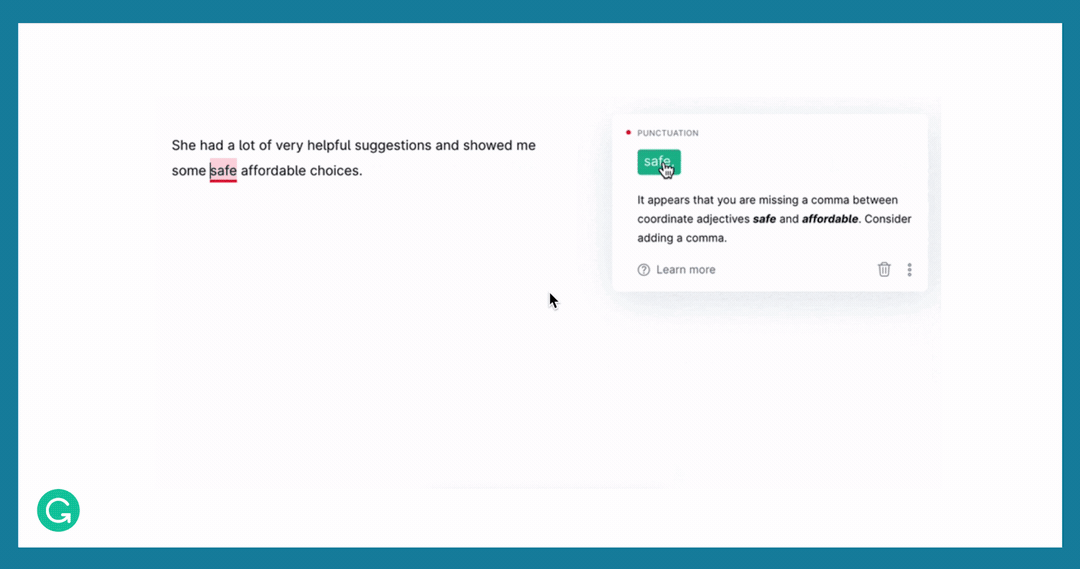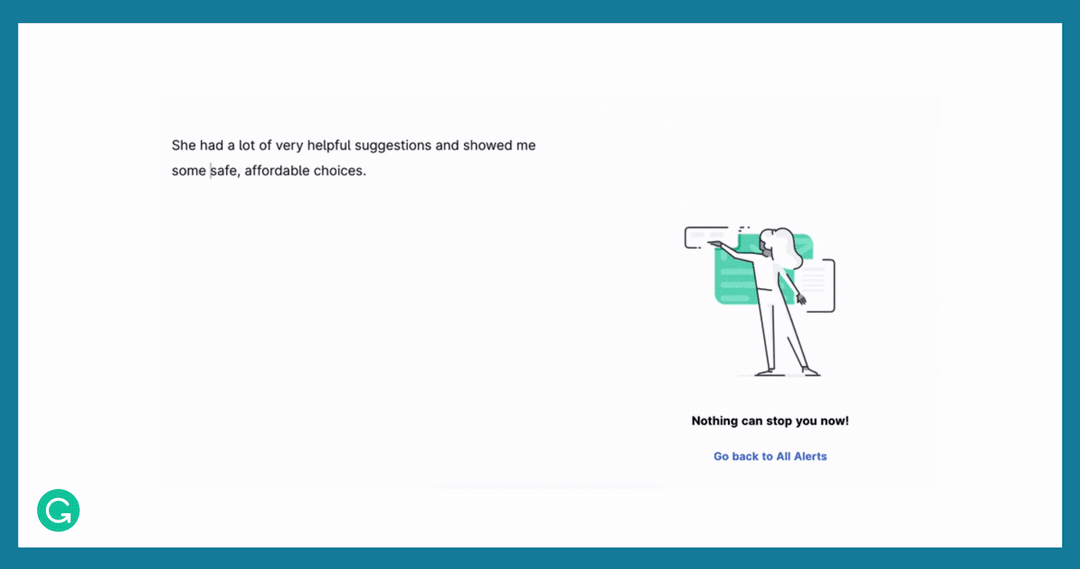
Stages of dataset development
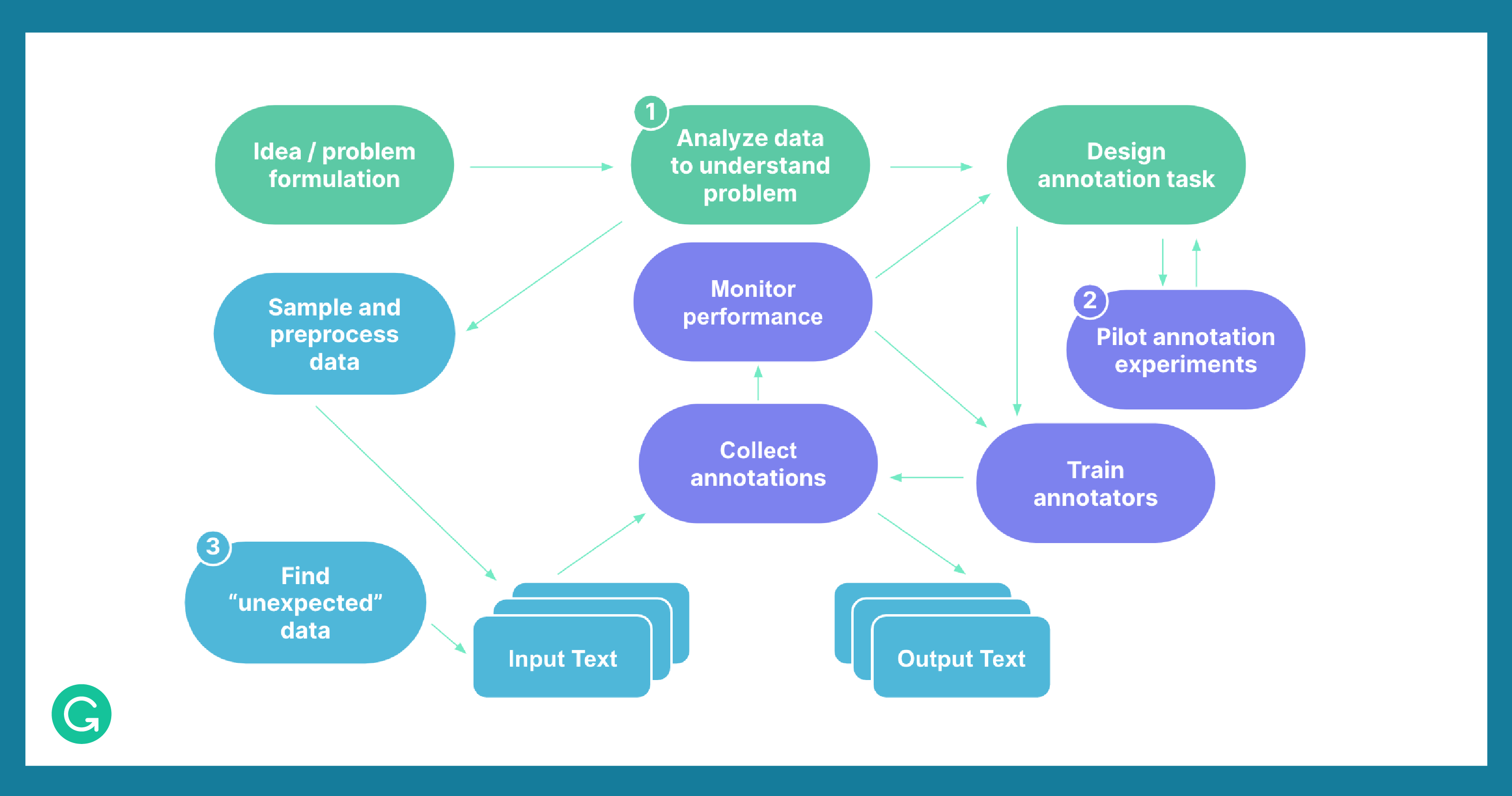
Below you can see a diagram showing the stages for developing an annotated corpus. We’ll focus on three tips that are often overlooked:
1 Data analysis
2 Pilot experiments
3 “Unexpected” data
By zeroing in on each of these areas, you can avoid some of the common data issues discussed above.
Analyze data to understand your problem
At the outset, it’s important to articulate the problem you are trying to solve with your model. This will inform everything you do from that point forward—from what data annotations you generate to how you measure the success of your model. And to understand your problem, the key is to start digging into data right away.
You can begin by finding a wide range of examples of the phenomenon you will model. When addressing a GEC issue, for instance, that might mean looking beyond the canonical datasets generated by English-language learners toward less obvious sources, such as web forums or social media. Try to identify the errors in the sample texts and generate outputs that feel correct. (This is an extremely useful process to engage with even if you aren’t a linguist or professional proofreader—the vast majority of your users won’t be, either!) Ask yourself: How would you intuitively correct errors in the text? Get a feel for the limitations of these corrections. Then pass the data to another person and see how their approach to the problem might differ. That will help gather a variety of perspectives.
As an example, here’s how we could approach addressing the problem of “correcting grammatical errors.” Examining a variety of data helps us refine the stated problem in ways that we may not have thought of beforehand.
| Problem | Grammar mistakes need to be corrected. |
| Analyze data | In the present, the teachnology is a past of life. |
| Revisit problem | Grammar and spelling mistakes need to be corrected. |
| Analyze data | sorry gtg its time for the party 🥳 |
| Revisit problem | Grammar, spelling, and mechanical mistakes need to be corrected. The tone should be formal (no slang, abbreviations, emojis, or emoticons). |
This exercise might show you that you need to redefine your problem statement to be more open or more constrained. As you begin to create guidelines for annotating data, you will develop a better sense of how subjective your task is and where you may be overlooking complexities.
Pilot annotation experiments
When creating a user-facing product with ML or DL, you will likely want to spend time training annotators to hand-label large datasets specifically for your task. You’ll need to decide on the labels, create a UI (user interface) for annotations, and develop a QA (quality assurance) process. Before committing resources to these tasks, it’s a good idea to run a set of annotation experiments to clarify your guidelines and identify edge cases.
In such pilots, it’s best to have a diverse group of people annotate data from multiple domains. This will prevent overfitting to a single perspective, dataset, or context. In the GEC example, most common research corpora rely heavily on student writing from English language learners (ELL). But if we only look at this type of data, our model will underperform on a wider range of real-world applications. Consider the different types of mistakes found in these three different domains:
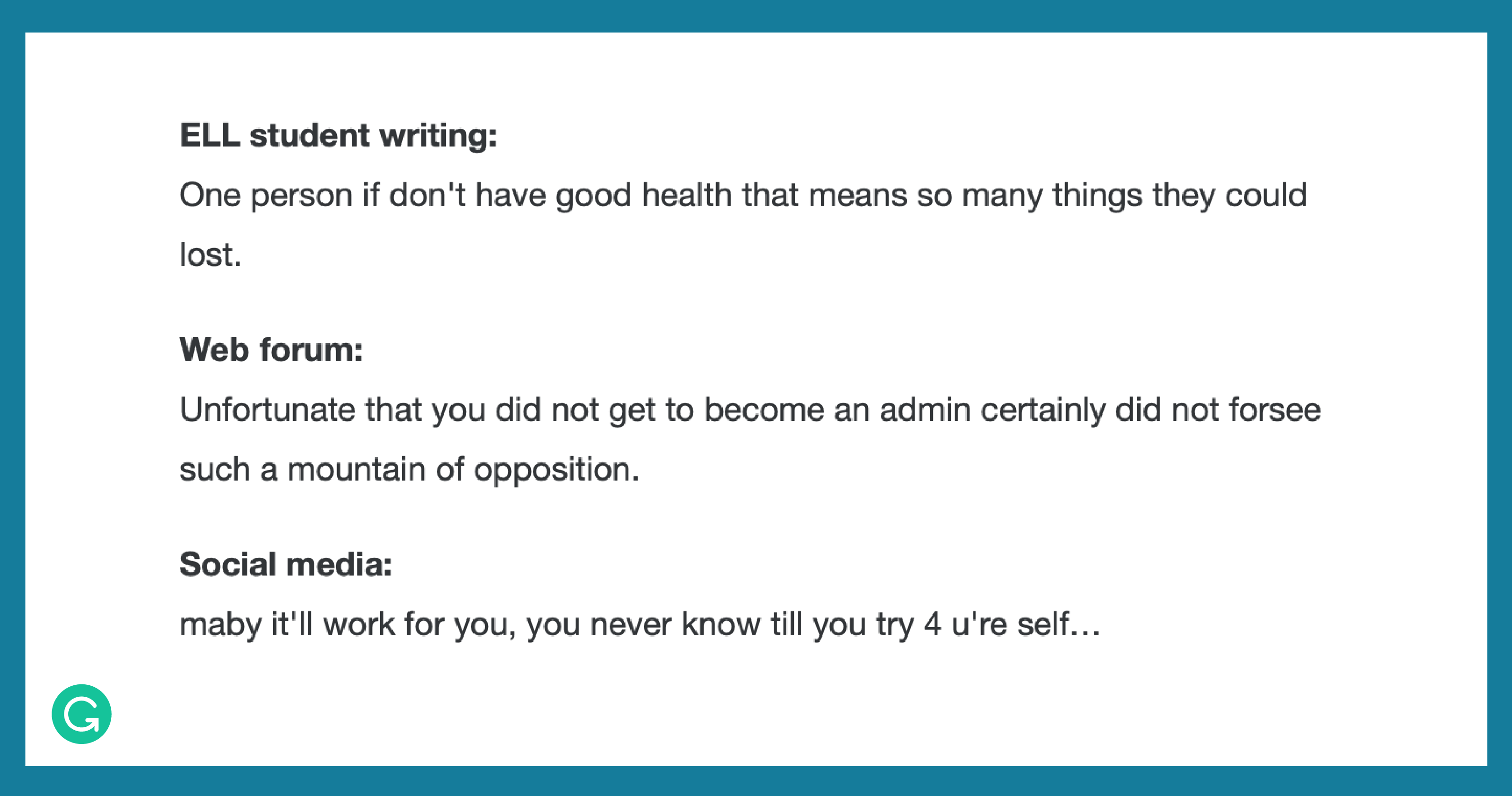
Beware of unnaturally constrained gold standards
As you run your pilot annotation experiments, it’s a good time to ask whether a single gold standard—one right answer—exists for your task. That is, ask yourself whether you can create a labeled dataset that every annotator will agree on. If you find that the answer is no, you’re not alone. For GEC, we’ve found that gold standards are usually overly restrictive.
For one thing, there is a lack of agreement about what constitutes an error in GEC. Trained experts tend to give equal weight to all errors, while fluent speakers will understand that some errors aren’t really so bad, or might even be acceptable. In the below grids, you can see how annotators marked what they viewed as containing an error (red x), a correct use of language (green check), or something that may be acceptable (blue question mark). Consider the text below:

Additionally, context matters. Annotators tend to be more forgiving when mistakes appear in an informal medium, such as a social post. Here’s an example of how different annotators might approach writing from such a source:

When there is no clear gold standard, you should be mindful of how you approach a pilot experiment. You can:
- Refine your guidelines until there is one gold standard—but keep in mind this may cause overfitting or a model that’s too brittle to handle new types of input.
- Collect multiple gold standards for each input to include in your corpus.
Find “unexpected” data
If you have considered a diversity of different data sources and annotators when creating an annotated corpus, you will be well on your way to avoiding model problems caused by the common data problems. However, it’s important to consider not only how your model performs in the typical case (and by extension, how your data should be labeled in the typical case)—but also how it does and should perform against slices of “unexpected” data.
There will always be surprises in the data—after all, the way people use language is constantly changing. A deployed model will frequently encounter noise (text with odd spellings, conventions, or non-words that the algorithm doesn’t understand, like omggggg, ¯_(ツ)_/¯, wait4it, or ���) or a completely new style of writing data from an unusual domain. But we can try to be aware of some common dead angles in our datasets ahead of time. In particular, we can look at toxic language. Toxic language can offend, perpetuate bias, or reinforce stereotypes, and it is usually stripped from corpora to prevent models from learning to propagate bias or amplify toxic language.
The reality is, however, that even though one might remove toxic language when creating datasets for building a model, once a user-facing product is live, that product is likely to encounter such language in user text. It’s important that a model knows how to take defensive action and react appropriately when toxic language appears in the input data.
To prepare a model to be able to respond in such cases, it’s a good idea to use metadata to identify various types of unexpected data (or create special datasets for this purpose) and conduct a targeted evaluation to see how your model performs across these slices.
Conclusion
We’ve looked at four areas to watch out for when creating annotated corpora to prevent common dataset issues: data scarcity, low quality, overfitting, and dead angles. While we’ve considered GEC as an example in this article, these principles can be applied to any NLP problem that you would like to solve with machine learning. As a parallel to the common software engineering refrain “know thy user,” we’d add a corollary: “know thy data.” The more that you are able to engage with the data yourself—and come to understand its particular nuances and pitfalls—the more successful your modeling efforts will be.
If you love solving problems with data and NLP—and want to help Grammarly continue to build its category-leading writing assistant—please take a look at our open roles!






