

Grammatical error correction (GEC) is an important problem in natural language processing (NLP) research. It refers to how we improve spelling, punctuation, grammar, morphology, word choice, and beyond. An intelligent GEC system receives text containing mistakes and produces its corrected version.
The more traditional approach for GEC is to use large transformer-based sequence-to-sequence models to “translate” the original text into a corrected version in one go. In 2020, we published our research on a faster, more space-efficient system named GECToR, which does sequence tagging to make iterative edits.
This article describes new research into improving GECToR’s performance through encoder configurations, ensembling methods, and knowledge distillation. With these experiments, we achieved a new state-of-the-art (SOTA) result for our ensemble model. And to our knowledge, our best single model is outperformed only by the much more compute-intensive T5 XXL model (Rothe et al., 2021), which is thirty times larger with 11 billion parameters.
You can read the full paper here: Ensembling and Knowledge Distilling of Large Sequence Taggers for Grammatical Error Correction by Maksym Tarnavskyi1 (Ukrainian Catholic University) and Grammarly researchers Artem Chernodub and Kostiantyn Omelianchuk. This paper was presented at the 60th Annual Meeting of the Association for Computational Linguists (ACL) in 2022.
Overview of GECToR
GECToR is a “tag, not rewrite” approach to grammatical error correction. It contains a transformer-based encoder stacked with two output linear layers that are responsible for error detection and error correction.
The system works by predicting the changes that will be made to each token in a sequence of text. Tokens are tagged as “keep,” “delete,” “append_t1,” or “replace_t2” (where t1 and t2 are new tokens). In addition to these tags, we use specific grammar transformation tags, such as changing the case or the verb tense.
After the sequence of tokens is tagged, GECToR applies the corrections. Since some corrections in a sentence may depend on others, the sequence is run back through the model in an iterative approach.
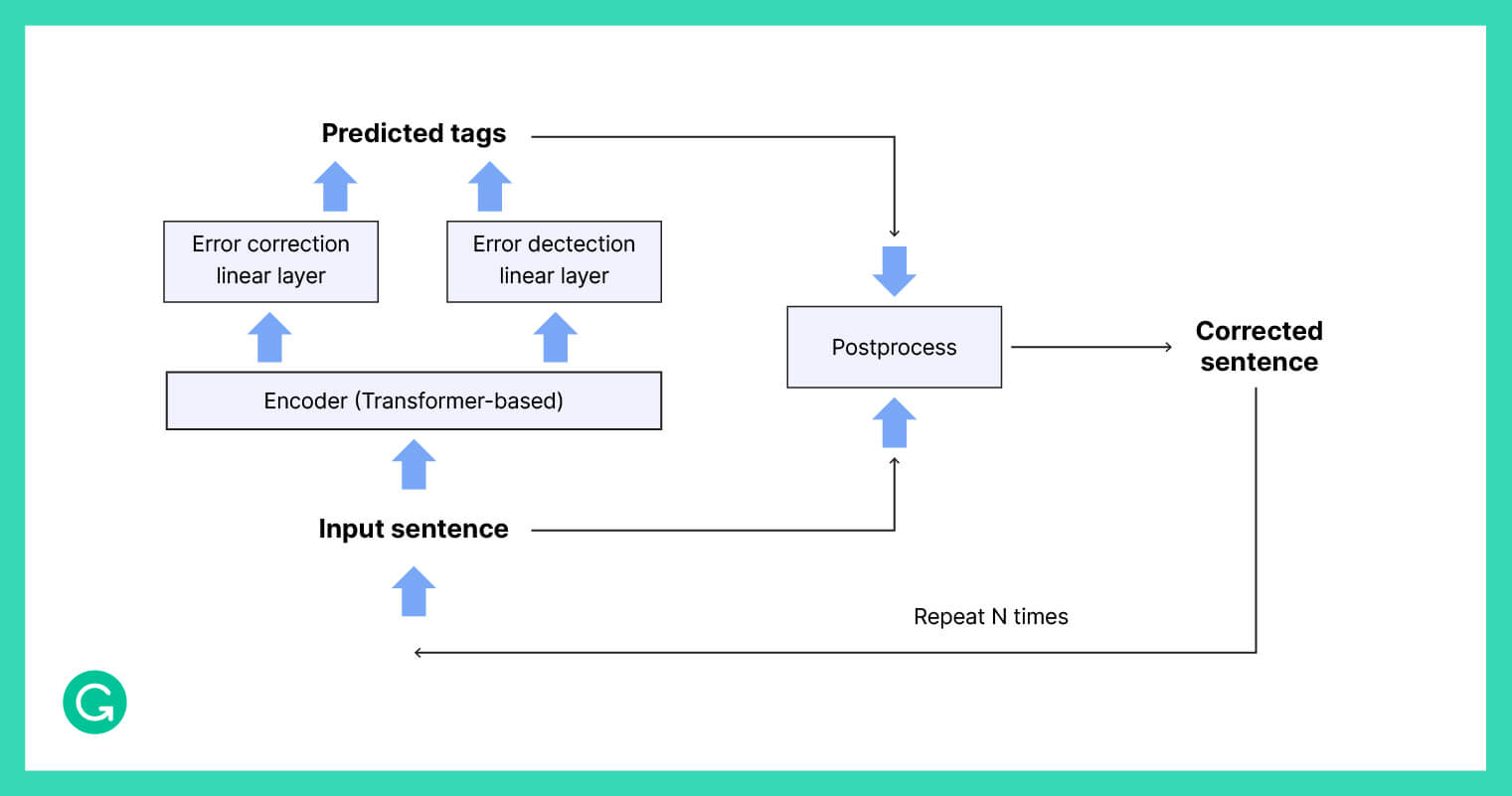
For a more in-depth description of GECToR, see this article. The source code is also publicly available.
Exploring improvements to GECToR
GECToR achieves near state-of-the-art results on the canonical evaluation datasets for GEC—while also being faster and less memory-intensive than systems that use a machine translation approach. In our research, we explored ways to improve GECToR’s performance even further using different encoder configurations, ensembling methods, and knowledge distillation. For space reasons, we’ll skip over our system setup, but you can read more about it in the paper.
Encoder configurations
The original GECToR system always used encoders in their Base configuration to trade off inference speed and quality. We investigated using the Large configurations instead, and we added another architecture, DeBERTa, that wasn’t explored in the original GECToR paper.
Results
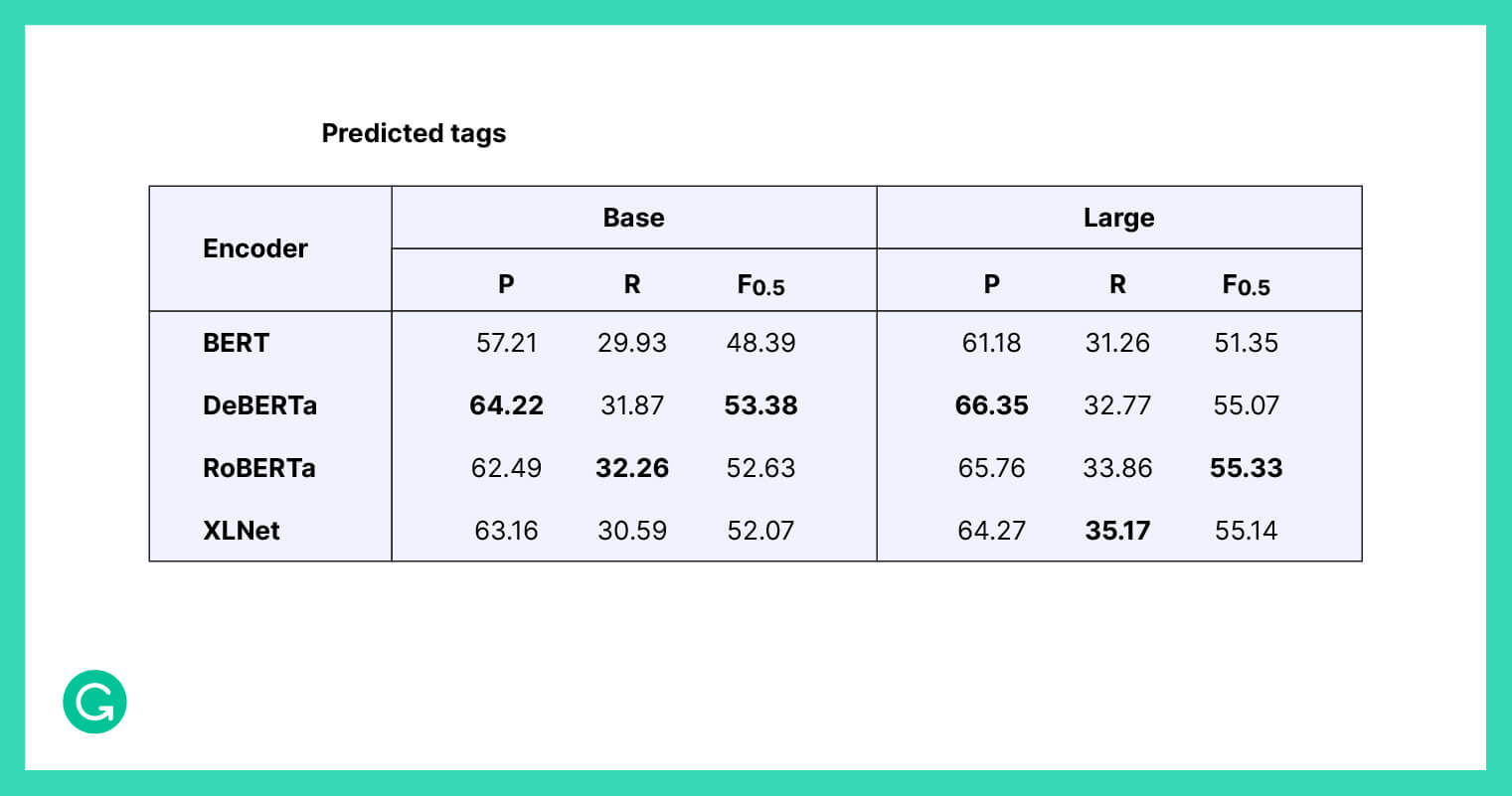
We found that switching from Base to Large configurations improves the quality by several F0.5 points for all encoders. However, it comes at the cost of 2.3–2.5 times slower inference on average.
Ensembling the GEC taggers
Ensembling combines the predictions from several models into a single prediction. It’s a proven way to improve quality for model sets with diverse outputs, and most of the recent GEC solutions achieved their best results with an ensemble method. In this research, we explored two different ensembling techniques.
Averaging output tag probabilities
One method of ensembling is to average the edit tag probabilities that different encoders produce and then use those computed averages to produce a corrected sentence. This approach was also used in the original GECToR paper.
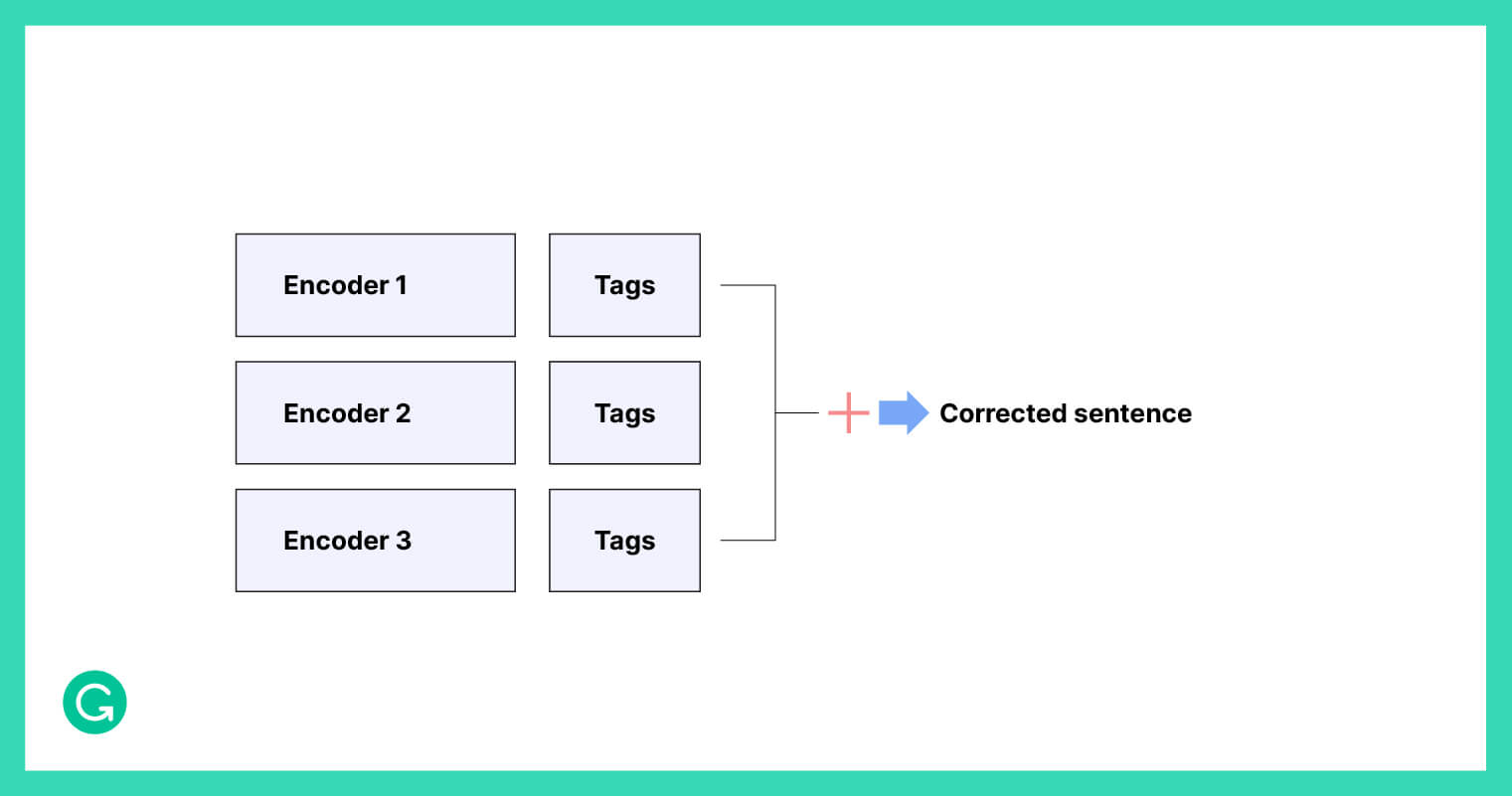
We found that averaging tag probabilities improves the quality of corrections, and the more models we combine, the better results we obtain. However, we had even more success with a second approach, described in the next section.
Majority vote on output edits
Another way of ensembling is to go a step further and actually generate separately corrected sentences from different GEC models. Then, we retain only the edits where a majority of the models also made this edit in their corrected sentences.
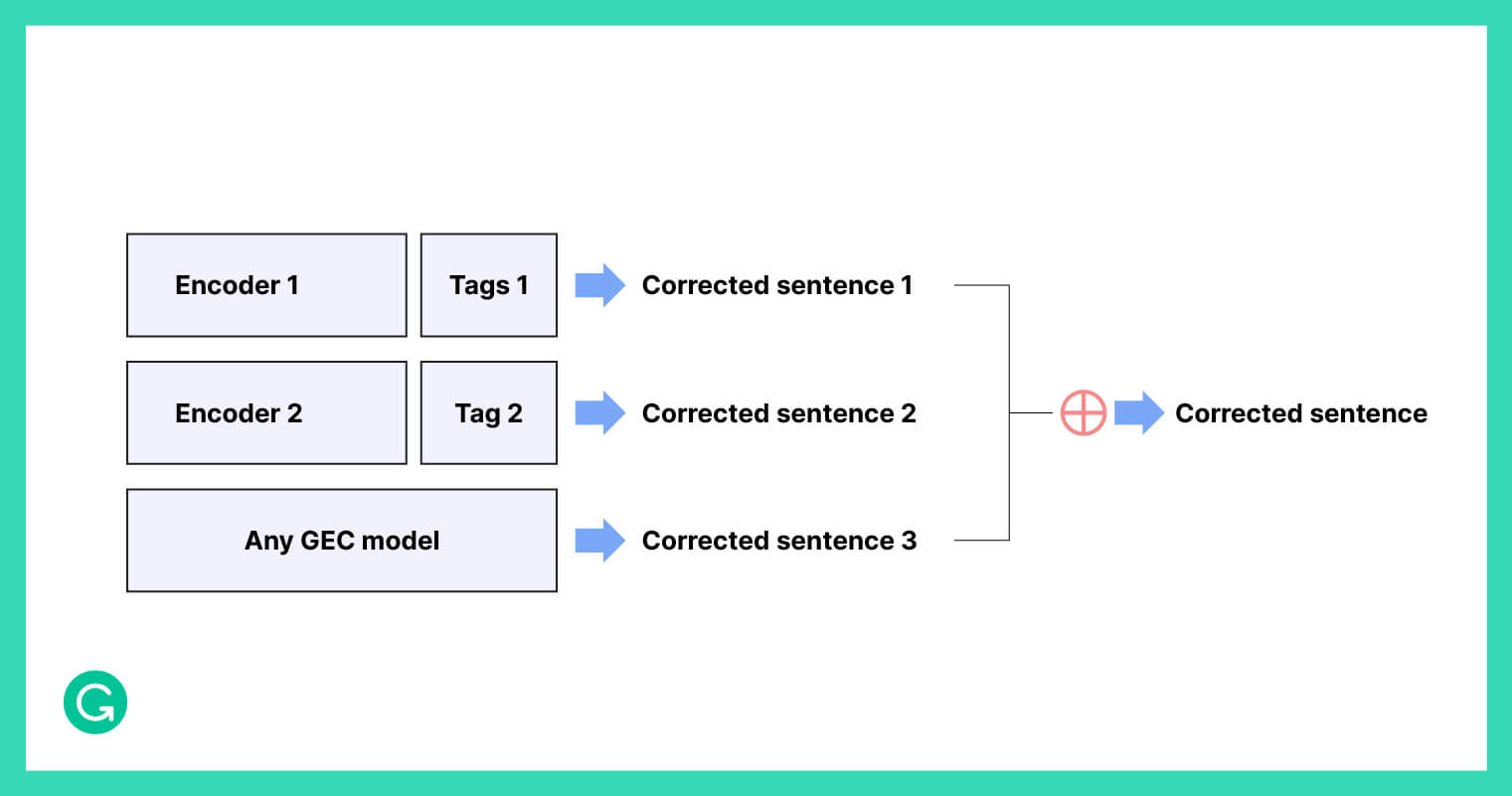
The advantage of this method is that we can combine the results of models with different output dimensions and even different architectures. In our work, it allows us to combine models with different tag vocabulary sizes.
We experimented with different definitions of a majority vote, defining a “majority quorum” Nmin as the minimum number of votes required to trigger an edit. Increasing Nmin boosts precision by the cost of recall because it filters out more edits where single models disagree. Setting Nmin = 1 is a poor strategy because we can’t rely on a majority when resolving conflicting edits, so the resulting text might contain controversial and incoherent edits.
We found that increasing the number of systems in the ensemble leads to higher quality but requires adapting the Nmin parameter. Based on a limited analysis, we observed that Nmin = Nsingle_models− 1 achieved the best results. For our pool of models, there was no gain from using more than four models, but we want to explore adding more diverse seq2seq models to such an ensemble in the future.
Results
We evaluated our best majority vote ensemble on the canonical BEA-2019 (test) dataset for the GEC task and achieved an F0.5 score of 76.05. This is a significant improvement over F0.5 = 73.70 for the best ensemble from Omelianchuk et al., 2020. To the best of our knowledge, this is a new SOTA result for ensembles on the BEA-2019 (test) benchmark. It’s worth noting that the solution is obtained without pre-training on synthetic data.
Knowledge distillation
Knowledge distillation is the method for transferring knowledge from a large model (“teacher”) to a smaller one (“student”). It has strong practical applications because large models usually have expensive inference costs and are inconvenient for deployment.
Having created high-quality ensemble models, we were interested to see if we could distill their knowledge into a single GECToR sequence tagger. We ran the ensemble solution on data from public news and blog texts that contain naturally occurring grammar mistakes. Given input sentences with mistakes, the ensemble generated corrected output sentences. Then, we used those input-output pairs to create distilled datasets for training student models.
Results
After knowledge distillation, our single GEC sequence tagging models show near-SOTA results on BEA-2019 (test) in two different training configurations:
- Multi-stage training: By pre-training, training, and then fine-tuning our single model, we achieved an F0.5 score of 73.21, several points above the best results for the original GECToR single model solution.
- One-stage training: By doing a one-stage training on a distilled dataset that includes our highest-quality annotated data, we achieved an F0.5 score of 72.69. This also exceeds the results from the original paper, and the setup is very simple.
Conclusion
We set out to investigate the impact of encoder sizes, ensembling, and knowledge distillation on the GECToR system. We found that using Large encoders improves the quality while trading off on inference speed. Ensembling models is an effective technique: We achieved a new SOTA result for GEC with a majority vote approach that lets us combine models with different tag vocabulary sizes. Finally, with knowledge distillation, we used our ensemble of models to train a single model and achieved near-SOTA results that improved upon the original GECToR system.
There are many areas we’re interested in investigating in future works, particularly around ensembling. We’d like to explore ensembling models with different architectures, such as combining seq2seq models with sequence taggers, as well as pre-training the single models used in the ensemble.
If you find these problems interesting, Grammarly’s NLP team is hiring for applied research roles! Take a look at our open positions here.
1 This research was performed during Maksym Tarnavskyi’s work on a Master of Science thesis at Ukrainian Catholic University in 2021.
Reference: Tarnavskyi, Maksym. “Improving sequence tagging for grammatical error correction.” Master of Science thesis, Ukrainian Catholic University, 2021.






