

The Grammarly AI Writing Keyboard for iOS helps you write confidently on your iPhone and iPad, providing features like grammar and spelling suggestions. It supports both tap and swipe typing (a.k.a. slide to type).
While swipe typing can be a much faster way to enter text on the mobile keyboard (compared to tap typing), it’s challenging to decode a gesture into a word. We’ve recently revamped our approach for swipe gesture decoding. In this blog post, we’ll share how Grammarly engineers developed and improved the swipe typing decoder for iOS based on a neural net architecture: the Neural Swipe Decoder.
Swipe typing and its challenges
With swipe typing, instead of separately tapping each letter of the word you want to spell on a keyboard, you drag your finger to make a continuous “drawing” of the word. Since you don’t have to lift your finger, swipe typing can be faster than tapping, and can reduce the risk of repetitive stress injuries.
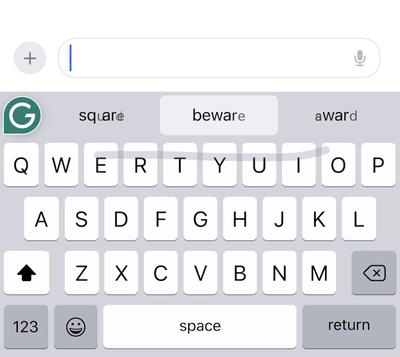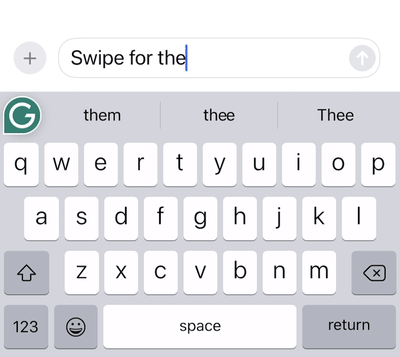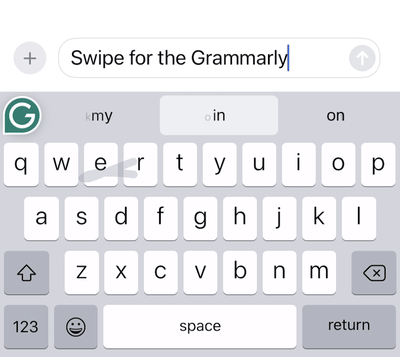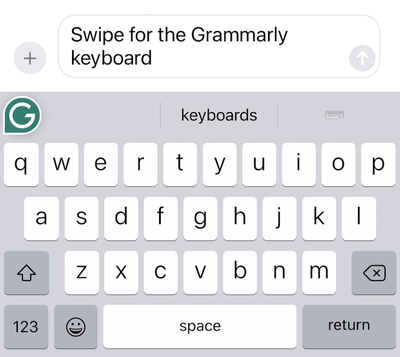
To build an excellent swipe typing user experience, we have to solve many interesting engineering problems. How can we detect the start of a gesture to determine whether the user is swiping or just tapping? How should we animate the swipe “trail” to provide just the right amount of feedback for the user?
This blog will focus on the most important problem: How do we decode what the user swiped based on their swipe pattern? To do this well, we have to grapple with three main challenges:
- Swipe patterns are very complicated.
- Physical memory (RAM) is restricted on mobile.
- Decoding with low latency and high responsiveness is a must.
Swipe patterns
Swipe patterns can be very complex, especially compared to how people tap on a keyboard. For one thing, many different words have identical or near-identical swipe patterns. Consider the words “god” and “good,” which have the same swipe pattern.

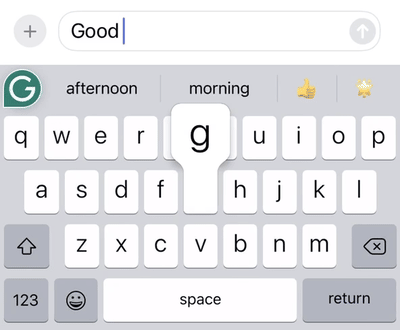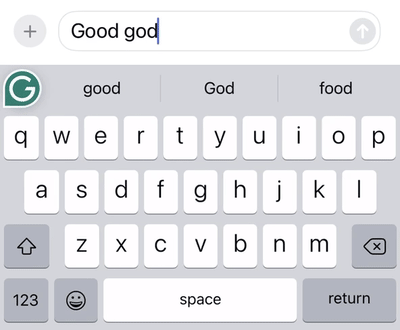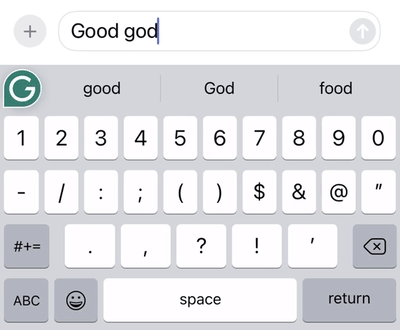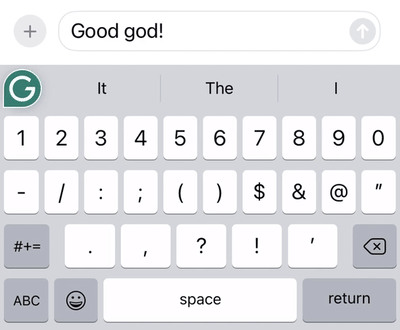
An example of the swipe system decoding the same gesture to the word “god” or “good” depending on the context in which the word occurs.
Or consider the words “good” and “food,” where the swipe pattern is almost the same. Even “play” and “pat”—very different words—have nearly identical swipe patterns!
The decoder must distinguish between all these similar patterns while handling small mistakes a user might make as they swipe. It also needs to be able to interpret prefixes and incomplete words correctly. For example, if you only swipe the first part of a word, like “specifical,” when you want to write “specifically,” then the keyboard should be able to complete your word.
Memory
Swipe decoding should be performed entirely locally, on the user’s device, to ensure data privacy. The amount of memory available to a third-party keyboard on the iOS platform is ~60 MiB (while this number isn’t published anywhere, we’ve determined it based on our experiments). This means that whatever experience we want to build needs to fit within the 60 MiB memory budget.
Latency and responsiveness
Real-time feedback: To provide feedback as you type, the keyboard produces results as soon as you start swiping—not after you’ve completed your full gesture and lifted your finger. This means the swipe gesture decoder must run continuously. When a new touchpoint is observed, it needs to update its suggestion quickly to be able to run continuously.
Latency and user experience: To provide a smooth user experience, we need to be able to process a gesture in roughly 17 ms on average. The iPhone samples touch points at 60 Hz (60 points sampled per second). If we cannot produce a result within 17 ms (1,000/60), we will likely miss a touchpoint since iOS won’t provide the next touchpoint’s move event if the Grammarly keyboard is not ready to accept and process it.
Swipe decoding with neural networks
Given these challenges, what’s the best architectural approach for a swipe decoder?
As with most engineering problems, there’s no single correct answer. Historically, the Grammarly Keyboard for iOS implemented the traditional approach of using a shape-based decoder. This technique compares the user’s input gesture (shape) to the standard shapes of different words, using a shape similarity algorithm such as dynamic time warping.
However, this approach can be brittle, given the complexity of swipe patterns. Our shape-based decoder still had accuracy issues even after adding pre- and post-processing of the user’s input and manual fine-tuning.
We decided to use machine learning to solve the problem. By training a neural network on a large amount of swipe gesture data, we could ensure that patterns we never thought to encode were accurately captured. What’s hard for a shape-based decoder is easy for a neural network system:
- Letter emphasis: A neural network can learn to translate more time spent on certain letters to help decide between words such as to/too and of/off. For example, looping on or spending more time on the letters “o” or “f” in the examples above will let the network decode the intended word.
- Prefix uniqueness: A neural network can learn to complete words even if the user swipes a partial gesture as input, as long as the prefix is unique to the word.
- Letter transposition: The network can learn to fix gestures that mistakenly transpose or leave out a few letters in the swiped word, as long as there’s no word the network can confuse the intended word with.
One reason not to use a neural network architecture might be performance. You must do extra work to ensure the model is memory-efficient and fast at inference. We’ll explain how we achieved this as we walk through the architecture of the Neural Swipe Decoder.
The Neural Swipe Decoder model
The Neural Swipe Decoder started as a Grammarly hack week project. A handful of engineers trained a deep learning model using a publicly available dataset. When the results seemed promising, the entire team rallied around the effort, and we were able to build and ship the feature in about four months.
The Neural Swipe Decoder is an LSTM encoder-decoder (seq2seq) model with dot-product attention. It’s trained to accept a list of input touchpoints, each with 33 input features, and output a single English letter (a–z) at each decoding step.
Model architecture
We chose an LSTM (Long Short Term Memory) encoder-decoder with attention because these models can perform well on a small input sequence (the typical input gesture is ~70 touchpoints on average). Our LSTM encoder-decoder can run inference with a low memory footprint and low latency—these are critical for mobile feature development.
The model has a 2-layer LSTM for both the encoder and the decoder. We found this to be a reasonable number of layers to ensure high accuracy while keeping latency low. It has 7.5M trainable parameters, which means it’s relatively small and can fit on-device.
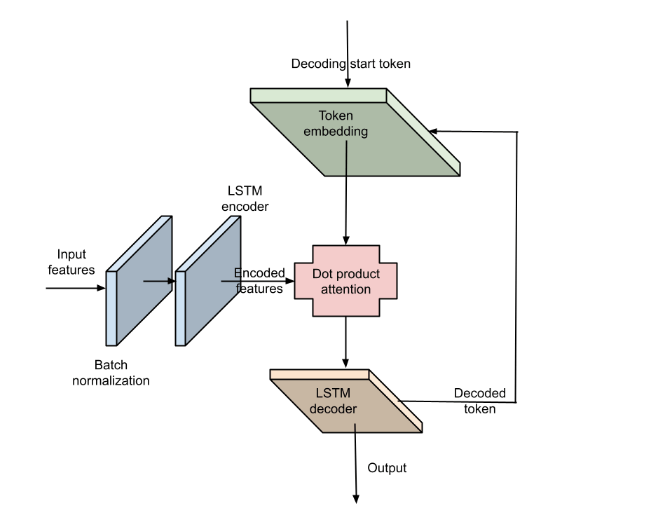
Neural Swipe Decoder model
For inference, we first perform a pruning step to remove touchpoints too close to each other. We provide the model with 33 input features per sampled touchpoint:
- Normalized x and y coordinates: We scale the keyboard to be a unit-sized square to account for the different keyboard sizes from which the touchpoints were collected.
- A set of 26 probabilities that indicate the likelihood of this touchpoint being associated with one of the 26 English letters. We compute the probability by taking the inverse of the distance of every key center from the touchpoints and computing the softmax over all 26 letters. A paper published by Google titled “Long Short Term Memory Neural Network for Keyboard Gesture Decoding” presents a scheme that uses 30 letters, including common punctuation symbols, and one-hot encodes them instead. We believe that using the softer probability-based formulation is better than the harder one-hot encoded representation since it gives the model more information for making predictions.
- The angle of approach from the previous point (between 0 and 2𝛱)
- Time from gesture start (in seconds)
- Time from the previous touchpoint (in seconds)
- Velocity (in normalized pixels per 10 ms)
- Acceleration (in normalized pixels/10 ms/ms)
We use BatchNorm on the inputs to ensure a zero mean and unit variance independently for each of the 33 input features.
Data collection and training
We used the following datasets to train the model and validate its performance offline:
- The public How-We-Swipe shape-writing dataset contains swipe data from 1,338 users with 11,318 unique English words. The data includes event timestamp, x and y coordinates, touch radius (in x and y axes), and rotation angle, as well as keyboard size and target word. (The development of that dataset is described in “How We Swipe: A Large-Scale Shape-Writing Dataset and Empirical Findings.”)
- Synthetic swipe data was generated using WordGesture-GAN. We generated gestures for 26,597 common English words with different noise standard deviation values (σ = 1, 1.3, 1.5; σ controls the standard deviation of the Gaussian distribution for sampled latent codes, which will increase the variance of swipe gestures as it increases).
- An internal swipe dataset was collected from Grammarly employees with their explicit consent. We used a similar approach to How-We-Swipe and collected 20,844 unique words from 25 users.
Data preprocessing and cleaning
As the data collection was performed in the wild, some data appeared invalid (e.g., the swiped gesture did not match the target word). We removed gestures that were too short (less than 6 touchpoints) and gestures where the starting point was not near the first letter of the target word, removing 2.1% of the total swipes.
Our data contains many instances of very-high-frequency words (for example, words such as “the” and “one” show up hundreds of times, whereas less frequent words show up just a handful of times). Therefore, we cap the maximum frequency of a word to 7 during training. This prevents the model from overfitting on any single word.
Data augmentation
To augment the training data, we randomly applied the following transformations to the dataset:
- Extend the beginning or the end of the gesture.
- Apply an affine transformation, including translation, rotation, scaling, and shear. We used a computer vision library for these transformations.
- Adjust the timestamp of the gesture using time scaling to speed it up or slow it down.
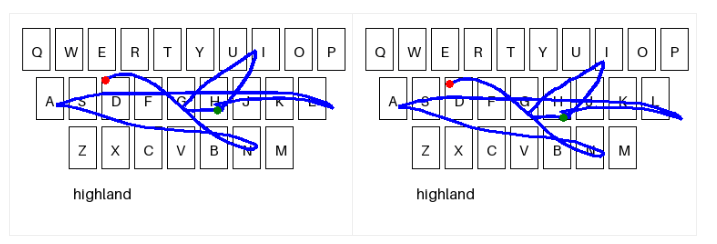
Sample gesture before and after applying the affine transformation. The green dot denotes the start of the gesture, and the red dot represents the end of the gesture.
Training
We used PyTorch to train this model with the following configuration:
- Cross-entropy loss. We tried Focal Loss and Weighted Cross-Entropy Loss to adjust for the imbalance in the frequency of letters in English. However, these didn’t perform better than standard cross-entropy loss and consistently produced worse results on the validation dataset.
- 30 epochs
- SGD optimizer. We tried AdamW, and while it converged much faster than SGD, the model trained with SGD showed better generalization performance in production. Others have observed this as well. See also this overview of optimization algorithms for more details.
- Exponential LR schedule running from 0.27 down to 0.02
- Weight decay of 1e-5
- Dropout of 0.2 after the encoder layer
Candidate generation, ranking, and filtering
We’ve shared how the Neural Swipe Decoder model works, but we’re not entirely done. The model’s prediction is a sequence of letters and not necessarily a coherent word. This needs first to be converted into a word. Additionally, this word may not be correct and may need to be adjusted based on context, so we need to generate multiple candidates from a single decoded gesture.
To do this, we leverage the same autocorrect system that the Grammarly Keyboard uses for tap typing. Autocorrect accepts the previous context (the text the user has entered so far) along with the word predicted by the Neural Swipe Decoder. It then produces a list of the top k (k is tunable by us) candidate words.
Autocorrect provides two scores for each candidate:
- A similarity score. This measures the “distance” between the candidate word and the word predicted by the Neural Swipe Decoder in terms of the number of insert, delete, or update operations needed to go from one word to the other. For example, if the neural model predicts the word “God,” “good” would have a higher similarity score than “food.”
- A language model score. Autocorrect uses a separate deep learning model to analyze how much a given candidate makes sense in the context of what the user has typed so far. If their sentence so far is “That sounds,” then the language model score would be high for “good” and low for “food” or “God.”
We blend these into a single meaningful score, rank the candidates, and then apply some filtering to remove potentially harmful or offensive words.
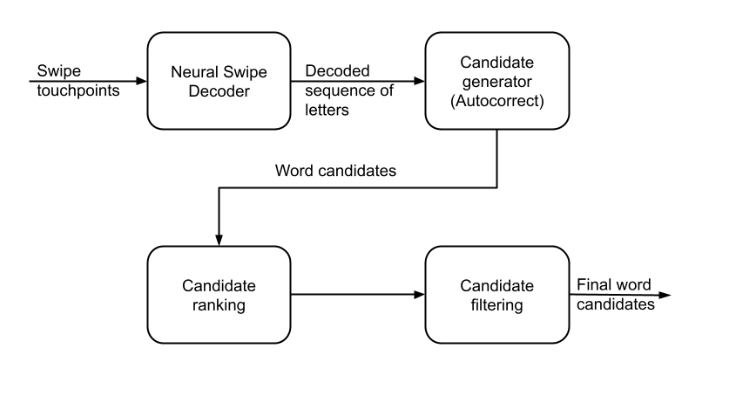
After decoding the user’s gesture, additional candidate words are generated, ranked, and filtered.
The top candidate is inserted into the text, and the user will see up to three additional candidate words in the box above the keyboard.
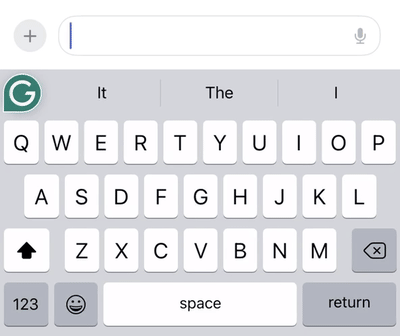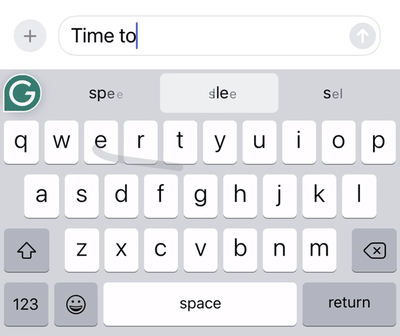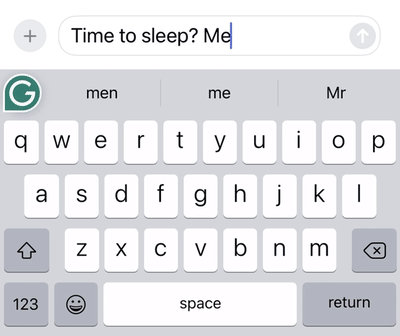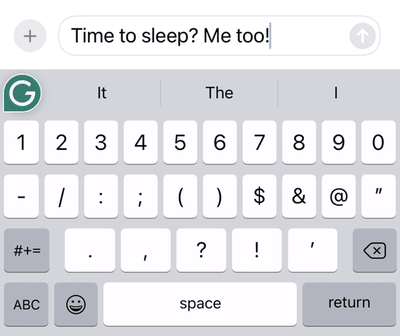
Candidate generation, ranking, and filtering at work: The same swipe pattern for the words “to” and “too” results in different decodings based on the context of the previous sentence.
Takeaways
Now you’ve learned how we built the Neural Swipe Decoder, the deep learning model that helps us decode a user’s keyboard swipe gesture into a word. You’ve also learned how we generate, rank, and filter multiple candidate words to hone the model’s output further.
Here are a few things our team learned along the way:
- The best systems generalize to problems they were never designed for or intended to solve. With minor tweaks to the hyperparameters, it was surprisingly easy to reuse tap typing’s autocorrect system to generate candidates for swipe typing. This not only saved us time, but it also ensures that in the future, both tap typing and swipe typing benefit from any improvements made to Autocorrect.
- Good things can come from small beginnings—we built the prototype of the Neural Swipe Decoder in just a week. Grammarly’s culture allows a small number of engineers to make a big difference in the product experience.
We’d like to thank the entire team that worked on this project: Dhruv Matani, Suwen Zhu, Seungil Lee, Kosta Eleftheriou, Roman Tysiachnik, Ihor Savynskyi, Sri Malireddi, Ignat Blazhko, Illia Dzivinskyi, Kyron Richard, John Blatz, Max Gubin, Oleksii Chulochnykov, Ankit Garg, Phil Mertens, Igor Velykokhatko. We’d also like to thank Viacheslav Klimkov and Vipul Raheja for their input on model training best practices.
We hope you’ll try the improved swipe typing experience on the Grammarly AI Writing Keyboard for iOS. And if you’re excited about the speed at which we ideate, build prototypes, and ship features, please consider applying to Grammarly!






