

Recently our team released Grammarly for Windows and Mac. It’s our newest application, providing Grammarly’s writing assistance in your browser and on many of the most popular desktop apps including Microsoft Office, Slack, and Discord.
One of the challenges with this project was solving how to deploy this complex application to millions of users. We wanted to make sure each user got the right version, since they might be using a newer or older operating system and we frequently run A/B tests to do data-driven product development. We also wanted to make sure we could push updates without any delay.
For Windows, we solved this by migrating and modifying code that we wrote to deploy Grammarly for Microsoft Office about a year ago. This blog post explains how we built that deployment system, which involved developing our own query language, parser, and interpreter. Really, it’s a story about how F# and functional programming can help solve complex problems efficiently and in creative ways.
Requirements for our deployment system
When deploying a Grammarly application to a user on their desktop, we need to make sure that the right version of the application is always pushed to the right user in an efficient manner. We also have a complex list of rules and conditions that we’d like to put into place to determine which version of the application they should receive. This might be based on whether they have a newer or older operating system, are part of a certain A/B experiment, and so on.
Given this setup, here are the requirements to have in mind when building a deployment system like this:
1 Make decisions based on the client context
To help us provide the best user experience, the decision of which version to send needs to be based on limited environment data that lives on the client—such as the experiments a user is participating in or what operating system they use.
2 Support flexible update rules
We want to support a set of complex and easily extensible “update rules” that can take in the client context and return the right version.

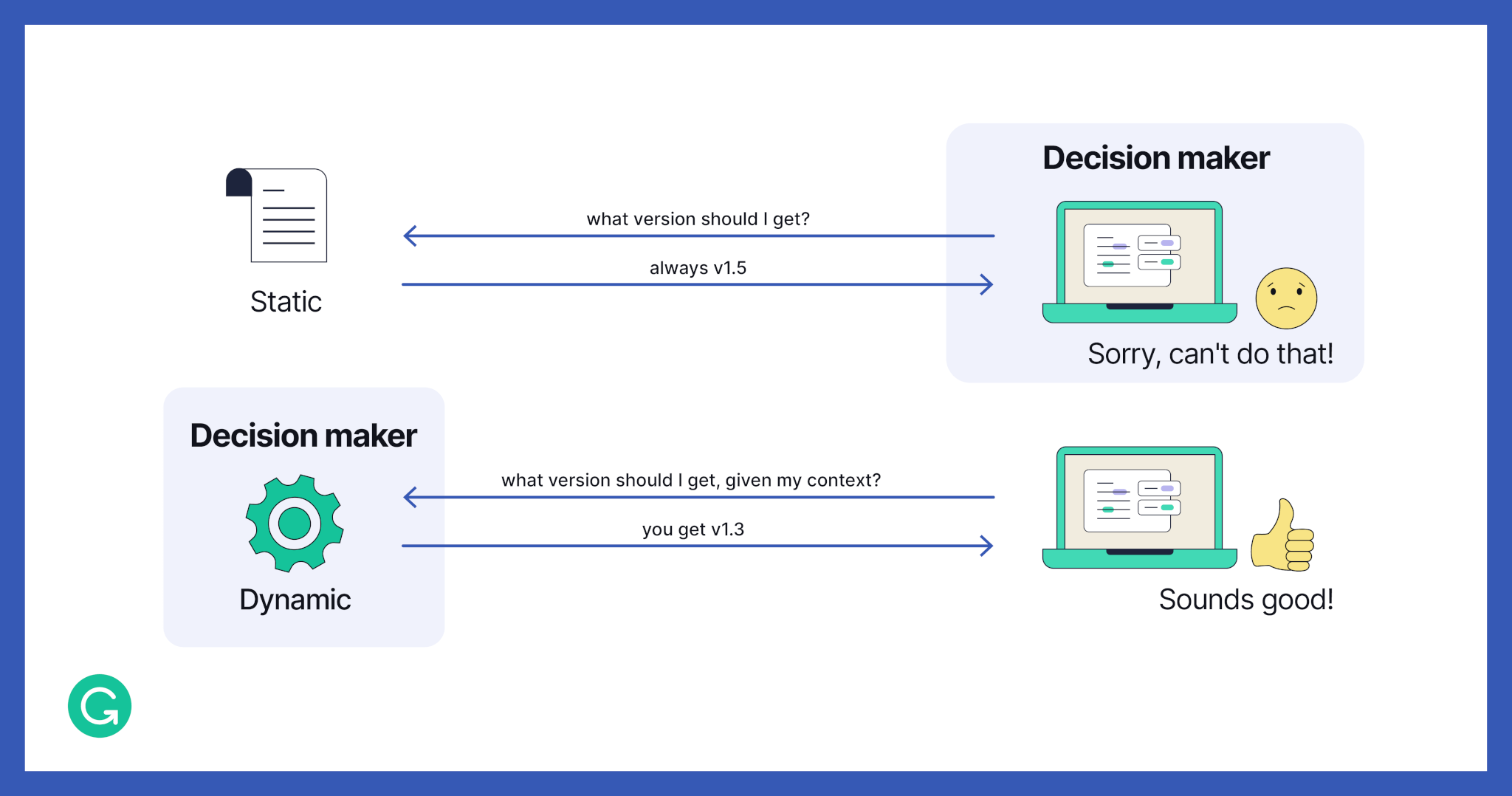
3 Make dynamic decisions
To push new updates and bug fixes quickly, we need to be able to make deployment decisions dynamically via a central decision maker that allows us to easily update our deployment rules.
Why we built our deployment system in-house
Once we’d identified what type of deployment system we needed, the obvious first step was to look into existing solutions and see if we could find something that fit our needs. After researching, we concluded that each existing option missed one or more of our key requirements for a variety of reasons:
- Versions were statically forced, so we couldn’t make flexible decisions based on client context.
- Decisions weren’t dynamic: Deployment decisions happened on the client rather than the server.
- The source code was closed and non-extensible, so we couldn’t add required functionality.
Therefore, we decided to design our own lightweight deployment solution, including our own domain-specific language (DSL) for matching the user’s context to a particular version.
Designing a DSL for JSON matching
But why did we need to develop a DSL? Well, the alternative—writing our versioning rules in a regular programming language—would expose us to potential problems:
- Each rule change would require a code deployment and some downtime.
- Usually, it’s harder to read an encoding in a general-purpose language vs. a DSL (as an analogy, imagine configuring SQL requests in code instead of writing SQL queries directly).
- A general-purpose language, while providing plenty of flexibility, introduces more ways for us to do something wrong.
We felt the investment in a DSL was worth it, especially since what we were looking for was a fairly simple language. Thus, Update Rules was born. It’s a DSL that lets us match rules on JSON context data from the client and outputs the correct application version number.
Here are a few examples:

Defining our syntax
When defining the syntax of our Update Rules DSL, we had a few requirements to keep in mind.
Because we wanted our DSL to be intuitive for developers to work with, we decided that the syntax around specifying fields should look like JSON:

For literals, we just needed to support the standard data types in JSON, along with arrays of those types:

To express our update logic, our DSL required special semantics around conditionals:
- Comparison operations (=, >, <, etc.) should work for strings and arrays in addition to booleans and integers, so we can have conditions like this:
currentVersion >= “1.1.0”orframework.major = [4, 5]. - We should have operators for containability for strings and arrays—for example, if a field is a substring of another string or an array contains a literal.
- We need an
existsandnot-existsconditional to ensure there’s a way to easily determine if a field was present at all in the JSON context data, on any nested level.
Naturally, we should also be able to combine these conditionals with AND and OR operators:

Last but not least, our syntax needed a way to describe outcomes based on conditions so that we could match user context to the right version of our app:

Parsing and interpreting our DSL
You might be thinking: OK, designing a DSL is one thing, but you still have to write a parser and interpreter for your DSL—isn’t that going to take forever? Well, we can reassure you that it’s not as bad as it sounds. Functional programming with F# and FParsec comes to the rescue to make things much easier.
An overview of FParsec
FParsec is a special parsing library called a parser combinator library. Although that might sound scary, it actually just means that we have a collection of various parsers in the library as well as many ways (functions) to combine them. Parser combinators are easy to understand but powerful enough to parse XML or even entire programming languages. Let’s take a look at how FParsec works in practice.
First of all, FParsec defines a Parser type. This is simply a function that takes a stream of characters and returns the result, failure or success, depending on the parsing outcome.

With this in mind, here are some common functions you can use to build more complex parsers:

pint32 and spaces are simple parsers that move through the text and parse integer or spaces correspondingly. pchar is a parser constructor (or factory) that takes a character to parse and returns a parser for that character. And the last function, between, is a parser combinator. It returns a parser for text enclosed inside starting and ending symbols.
Example: Parsing a simple expression
To build more intuition around what it looks like to do parsing with these primitives, here’s an example:

We have a simple expression: (1 + 2), adding two numbers inside parentheses, and we want to parse those two numbers into a tuple. To do so, we’re using the library functions mentioned earlier and building a single parser by combining other, simpler parsers. In the highlighted row, we’re constructing the main part of the parser. Without going deeper into what exactly is going on yet, we can see the general structure: parsing integer --> parsing spaces --> parsing character "+" --> parsing spaces --> parsing integer.

On top of this, we also need to specify that the addition expression is enclosed inside parentheses. To do so, we’re using between. The starting and ending symbols are the open and close parentheses, and we’re passing in a parser that’s configured for what we expect to see between those symbols.
The only thing unknown for us now is the combinators containing >>, circled in yellow in the code snippet. Those are special combinators that specify the order of parsing and the value we should keep or discard while progressing through the text. They have quite handy mnemonics to remember what they’re doing: The arrows show the direction of the parsing flow, and the dot shows from which side of the combinator we should keep the value to work on later.

Using FParsec to parse our DSL
Writing a parser for our DSL using FParsec happened in a few steps.
1 Documenting our rule structure
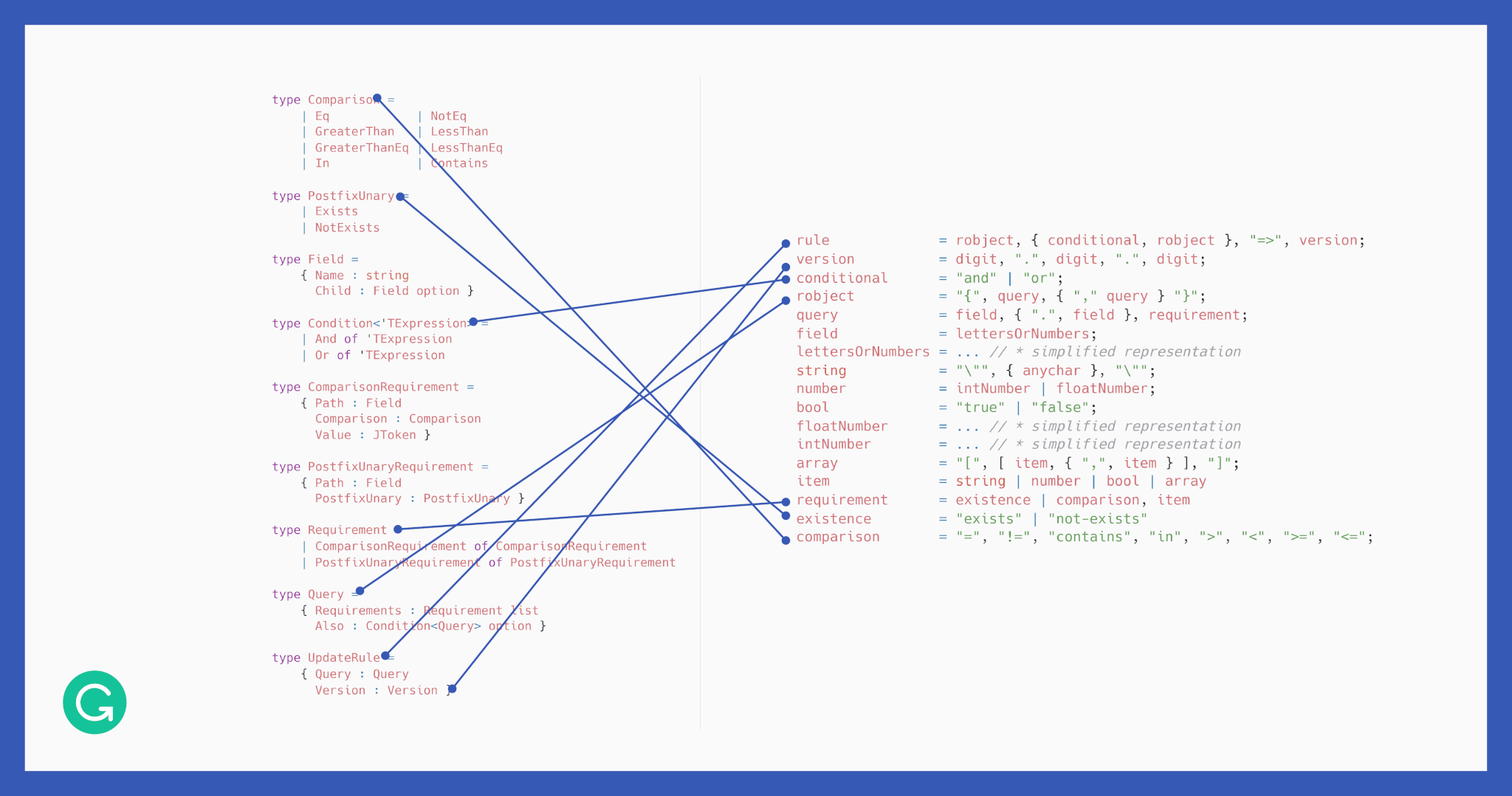
Before writing any code, we used EBNF-like notation to document our Update Rule structure in a compact, readable form. This provided a sort of cheat sheet to use when coding parsers, telling us what different rule substructures were generally supposed to look like.

2 Encoding invariants within domain types
With an understanding of what our rules should look like, it was time to actually do some coding. With a language as strongly typed as F#, it’s always a good idea to start with encoding invariants within domain types.

Looking closer, you might notice that the most important parts of the domain nicely reflect the structure of our EBNF specification.
3 Parsing rules
Next, it was time to parse our rules. It’s important to note that when parsing rules, we don’t return primitive types—rather, we build an abstract syntax tree (AST) on the fly.
Here’s an example of real code for parsing some parts of a rule:

You’ll notice all the parsers and combinators we’ve discussed, and many more. Looking at our EBNF notation once more, you’ll see similarities with parsers as well.

And as an end result, we’re getting a clean final function that parses all the text into our AST or returns a nice error explaining why it can’t do it.

Here’s an example of a rule and its corresponding representation in our AST:

Interpreting our DSL
A parsed rule is quite nice-looking by itself, but we can’t do anything useful with it until we can properly interpret the encoded instructions. We do this with a match function.

Match works rather straightforwardly by recursively traversing the AST we built. With algebraic data types, we’re able to precisely encode our rule configuration, match it using the default F# pattern-matching techniques, and interpret it in the desired way.
Hosting our solution on AWS Lambda
Having implemented everything we discussed, the only thing left was to wrap it all up into a web application and conveniently host it somewhere.
Where do you go when you want to spawn a scalable server for your small service with minimal configuration? That’s right, you go to the “stateless,” “serverless” building blocks that each of the major service providers has: AWS Lambda, Azure Functions, or Google Cloud Functions. As we’re already running a lot of our services on Amazon, it was quite natural for us to look into AWS Lambda first. And surprisingly, AWS has everything needed for F# functions to run, from the .NET runtime to tooling and scaffolding templates.
The overall solution looked something like this:
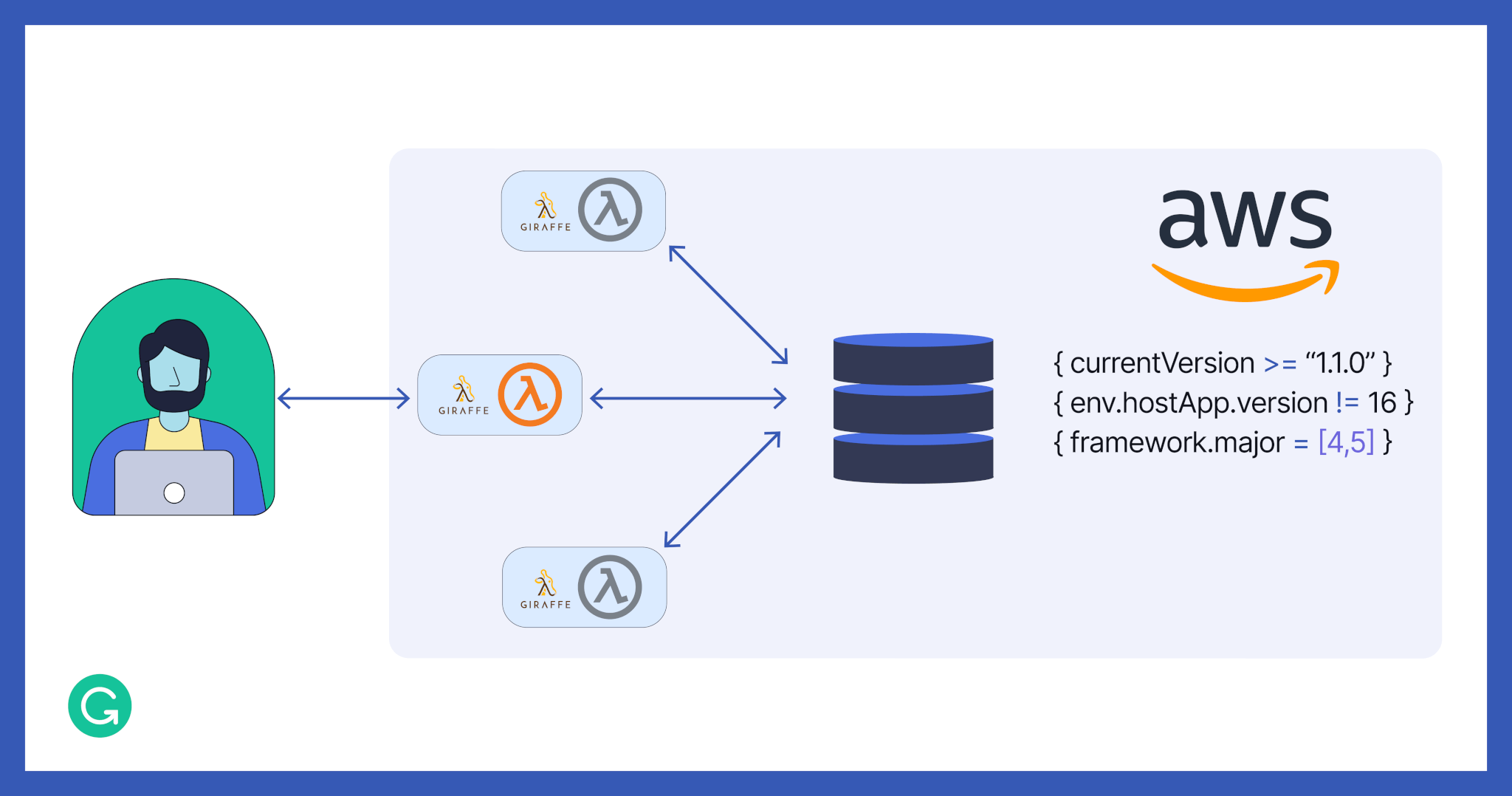
AWS already has F# templates based on the Giraffe web framework with all the necessary boilerplate for query parameters and other AWS service communication configurations built in. We simply needed to bundle up the core matching mechanism and deploy this code as a Lambda service. Here are the nice things about Lambda:
- It’s easy to configure and deploy code to it.
- It has automatic scaling, so there’s no need to worry about your load patterns.
- Costs are lower since you’re just paying for your current load and work actually performed.
The benefits of F# and functional programming
Having gone deep into the details of writing our DSL, parser, and interpreter, let’s zoom back out to mention a few points about F# and functional programming in general.
- If it compiles, it has no bugs! But seriously—we haven’t found a single production bug since launching this code a year ago.
- It’s great for fast prototyping. The initial prototype for this deployment system was developed over a single weekend’s exploration.
- Even though F# might not top any charts of most-used programming languages, it has reasonably good vendor support, as we saw with AWS Lambda scaffolding.
- Functional programming in F# and the rich ecosystem surrounding it opens the door to creative solutions for problems that can be implemented relatively quickly.
Tricky problems with a big impact (like deploying a new desktop app to millions of users) are one of the reasons it’s so exciting to be an engineer at Grammarly. We’re hiring—check out our open roles here.






