

When you compose an email or document, it can be hard to articulate your thoughts in an organized manner. The most important ideas might end up buried in the text, and the paragraph structure could be confusing. As a result, especially if a reader is skimming through the text, they might not grasp what you were trying to say.
At Grammarly, we’re determined to help people communicate more effectively and with less doubt and worry. So we recently took on a new challenge: Can we let users know if their points are coming across clearly when they’re writing an email?
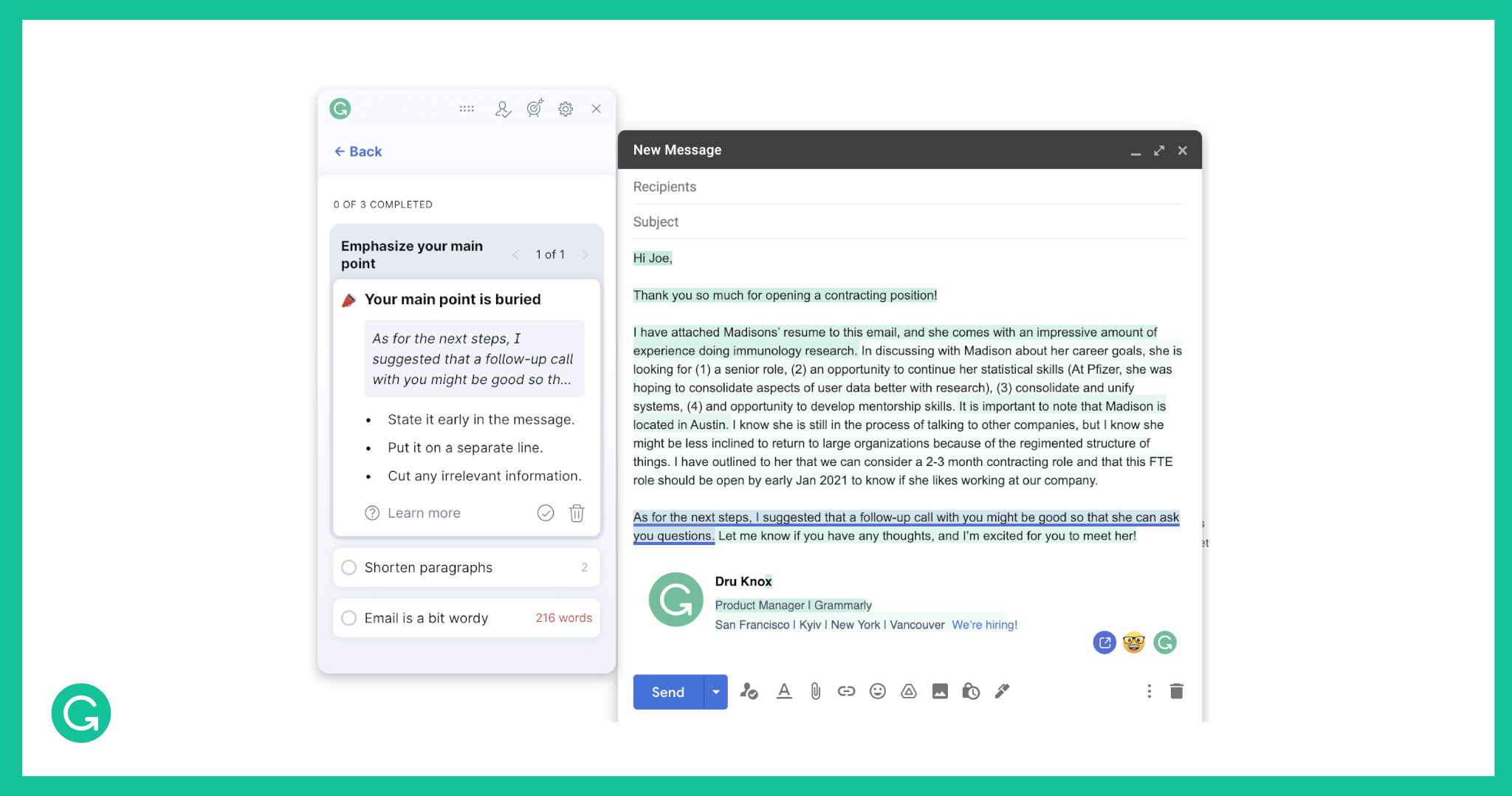
Our model helps power Grammarly’s new reader’s attention feature, which tells you how likely your main points will come across to your reader.
On the technical side, we broke this problem down into two pieces:
1 Extracting the main points from the text
2 Detecting where the reader is likely to focus their attention in the text
Extracting the main points from a text is a familiar problem in the field of machine learning (ML) and natural language processing (NLP) research, but our unique use case and constraints led us to apply a different approach to the problem. Grammarly needs to deliver writing suggestions at a very low latency that can scale to 30 million daily active users across a variety of devices and contexts. Throughout the model development process, we had to be thoughtful and creative to achieve successful results against these constraints.
Defining the task to model
Whenever we start working on a new NLP problem, we dig deep into the problem itself to make sure that we have a good handle on what success would look like. Before we even thought about modeling the task, we had our team of in-house analytical linguists clearly articulate what the main points of a text are by working through many examples. This helped us narrow down our definition of the problem.
For this feature, we decided to identify and highlight the sentences that represent the key ideas of an email. Initially, for any particular email each linguist would have a different answer about which sentences were most important. So we decided to get more specific about what we were looking for and account for the subjectivity of the task:
1 We separated action items from main points. For example, an action item could be “Please fill out the launch checklist before we meet” while a main point could be “We need to delay the launch by two weeks.” Creating these separate buckets would help us improve the accuracy of our model and ensure that we could build future ML-powered features around action items.
2 We used an importance score to account for the fact that there’s some subjectivity around what the main points are in a message. When working with annotated data, we could average and normalize the scores given by different people to achieve a general consensus.
With this framework in place, we were able to start collecting ground truth data with our team of annotators. Our annotators were asked to identify the main point sentences and the action item sentences in a set of representative email texts, and also judge the importance of each main point.
It’s important to note that when analytical linguists create a nuanced definition like this, we spend a lot of time thinking about how to explain the reasoning to our users. So as we were kicking off the model development cycle, we were also working with the Product and UX teams to land on the right designs and phrasing for our in-product descriptions—and ensuring these aligned to the methods we used to detect the main points.
Developing a model
With a well-defined problem and our annotation pipelines in place, we were then able to turn to the task of modeling. Because we initially had only a small evaluation dataset, we decided to build a model based on reinforcement learning with a set of heuristic features.
Here are several of the key steps we took to build the model:
- Reviewing the research. We were able to learn from traditional academic approaches to extracting the main points (“extractive summarization”).
- Developing features. We worked with our in-house analytical linguists to build a robust set of language-based features.
- Optimizing our model. Our model was initially slow on longer texts, leading us to use various optimization strategies to reduce the scope of the problem and bring down our model’s inference times.
Each of these steps will be described in more detail in the following sections.
Reviewing the research
Extractive summarization—pulling out the most important sentences from a piece of text—is a well-studied problem in the NLP field. (Compare this to abstractive text summarization, a process where a summary of a text is written from scratch.) We were influenced by some traditional NLP solutions that identify the important points in a text.
One brand of solutions for extractive summarization are algorithms inspired by PageRank. PageRank tries to find the most important websites based on how well-connected they are to other pages on the web. LexRank and TextRank use the same approach to try to find the most important sentences based on how well-connected they are to other sentences in the text. While PageRank measures the number of links between pages, LexRank and TextRank look at the number of words that a sentence has in common with other sentences in the text. These methods don’t perform quite as well as newer deep learning methods—but we ended up using the LexRank of each sentence as a feature in our model.
A more modern NLP approach to text summarization is called BERTSUM. You run the text through a massive language model to get a latent representation for each sentence, and use labeled training data to teach the model which sentences are the main points and which aren’t. The model then finds the set of sentences that have the highest probability of being the main points. A deep-learning approach like this can be quite effective, but requires a lot of training data—which we didn’t have at the beginning, because we were setting up annotation pipelines to develop datasets.
Developing features
In addition to using LexRank, we developed a set of semantic features that would tell us when a sentence was likely to be a main point. These features might be different for different domains—in emails people tend to put their most important points at the beginning and end of their message, while in a longer document the main points might be found in the title and section headers. Structures like “I wanted to let you know . . .” can also indicate an important point. We worked again with our team of analytical linguists to bring their language expertise to this problem.
Optimizing our model
To make our reinforcement learning model perform with low latency, we had to put optimizations in place, especially to handle longer texts. Consider an email with 10 sentences. The main points could be any set of those 10 sentences: sentences 1 and 2; sentences 3, 4, and 7; and so on. Combinatorially, that’s 210 potential scenarios for the model to consider, or 1,024. Not so bad, but if you add just 10 more sentences to the email, the model now has to consider over a million potential options!
How could we make the problem more tractable? One way we achieved this was with sampling. The idea is, instead of looking at the entire set of possibilities, we take some random groupings of main points and score them against our features. The next time we sample, we bias toward the sentences that were found in top-scoring groups. In other words, if we do an initial sample and find that sentence 2 always appears in the best summaries, the next time we sample, we’ll be more likely to choose sentence 2.
In theory, this algorithm will always converge to the best subset—but that can easily take a long time for even a short email. So we needed to employ a number of strategies to balance latency and model performance while avoiding the trap of local minima. For example, we track the trajectory of weights that the model gives each sentence at each sampling iteration. On the first iteration, all sentences will have a weight of 0.5, representing a 50% chance of being a main point. On the second iteration, the model will have learned that some sentences have a weight of 0.6, while others are at 0.4. If over time a sentence looks like its weights are consistently going toward 1, while others are moving toward 0, we’ll stop considering those sentences and assume that they will converge to that binary value.
Additional optimizations we performed include dropping sentences that are obviously not a main point—such as the salutation at the beginning of the email and the signature at the end. We also saved our computations so that as we were continuously sampling, we wouldn’t have to recompute values that we’d learned in previous iterations. With all these techniques, we were able to reduce the inference time significantly. Our initial implementation was taking 1–1.5 seconds for inference, and we were able to cut that down to around 8 milliseconds.
We’re able to do even better than this for the large fraction of emails that are very short. For emails with fewer than 10 sentences, we can skip the sampling step and enumerate everything in memory rather than perform iterations. This only takes around 1 millisecond, so our 99th percentile latency for inference ends up being around 4 milliseconds.
How to try the model for yourself
The model described above performed with 80% precision, and with the development of robust annotated datasets, we were recently able to move to a deep learning approach that preserved the same level of precision while improving recall from 40% up to 62%.
The reader’s attention feature, available to users of Grammarly Premium, helps you ensure readers focus on your main points and helps maximize the impact of your emails. It is currently enabled in the Grammarly browser extension and also works for email clients like Gmail, Yahoo Mail, and Microsoft Outlook. Suggestions will appear in the Predictions section under the header “Readers may skim parts.” We hope you’ll give it a try and test out the speed and quality of our suggestions for yourself!
Grammarly is hiring applied research scientists, machine learning engineers, and analytical/computational linguists on our NLP/ML team. We are moving to a remote-first hybrid working model. Check out our open roles here to learn how you can build features that help 30 million people and 30,000 teams communicate with confidence every day.






