

If you’ve ever used the spell-checker or autocorrect function in a popular product, you may have been a victim of gender bias in machine learning. Just look at how corrections can vary depending on the gender of the nearby pronoun.
Here’s the spell-checker in a popular word processor:

And here’s the autocorrect feature in a popular operating system:

As a user, you might be appalled by this. As a machine learning practitioner, you might start feeling uneasy about your own work. I certainly did when I read this interesting article on the subject, which inspired me to do my own investigation into how we were dealing with the issue at Grammarly.
In this post, I will describe the problems we faced and the steps we took to mitigate gender bias when working to create an autocorrect feature for Grammarly’s writing assistant.
Automatically correct
When Grammarly’s writing assistant detects a spelling mistake, it gives you an option to correct it. Even more likely is that it will give you multiple options to choose from. The spell-checker doesn’t need to have complete confidence in one particular suggestion—or even in offering any suggestion at all—since the final judgment on your preferred or intended spelling is up to you, the writer. If you don’t believe any of what’s been presented is an improvement to what you’ve written, you can just ignore the suggestions and move on—no big deal.
Sometimes, though, we can be sure enough about how to fix a misspelled word that we can simply apply the correction automatically. This saves you some time and unnecessary distraction from what you’re writing. But it also changes how we have to think about the change to your text. We are not offering an array of suggestions anymore but instead become responsible for judging which suggestion is correct and then choosing it for you. If the choice is wrong—and your text suffers for it—we are to blame.

Autocorrect works great when it’s on point but can be very frustrating when it isn’t—when you, the user, have to answer for the product’s mistake. And if an autocorrection is not just wrong but also displays any sort of bias, a bad situation can become a complete disaster. A biased correction ruins the user experience—and, most importantly, it reinforces and helps perpetuate the bias itself.
At Grammarly, we’ve worked over the years to mitigate bias in our writing assistant. This has meant consistently improving the algorithms that power the product. Here’s one issue of bias that a user encountered some time ago in our spell-checking feature—which we’ve since fixed.
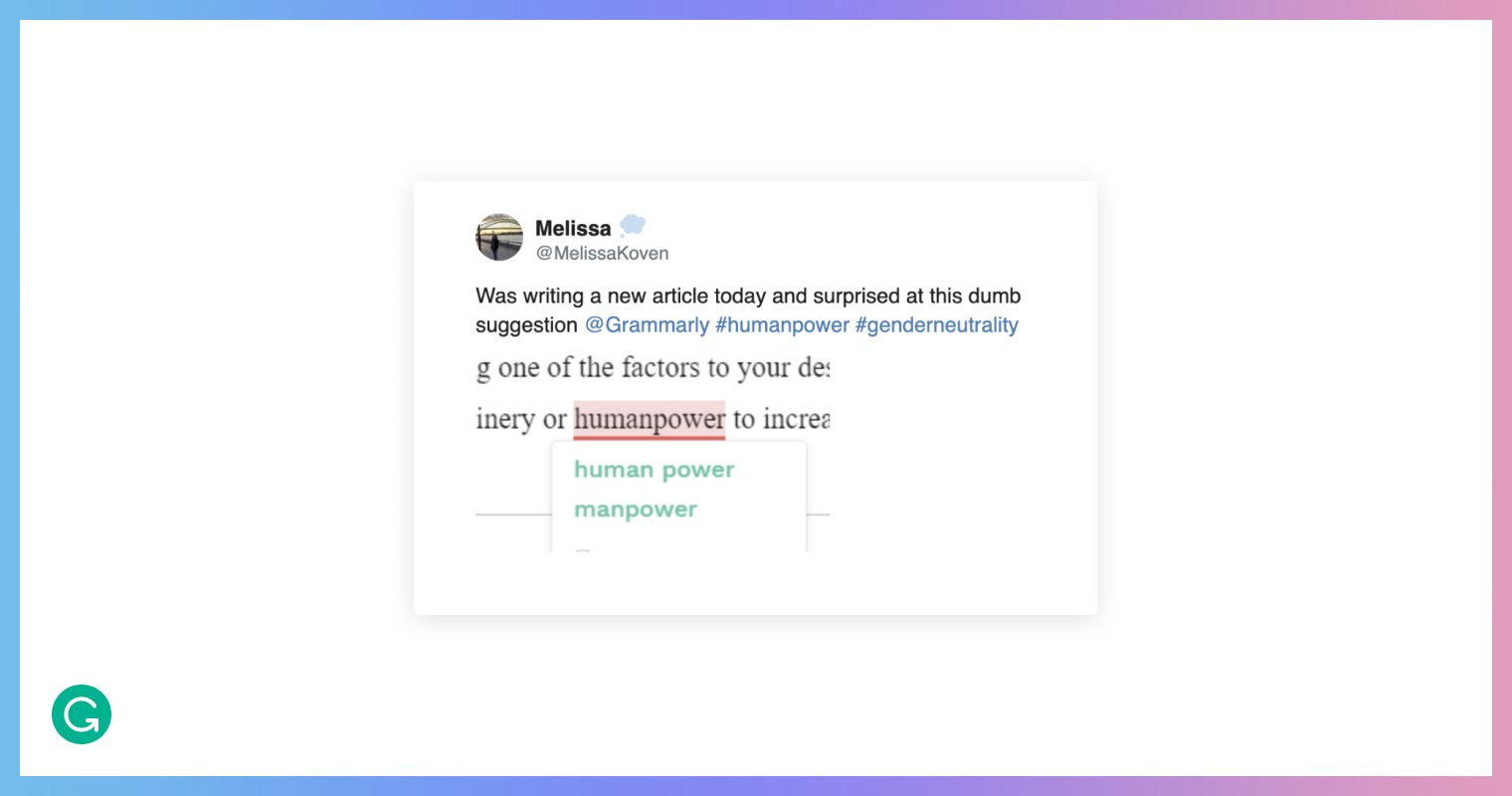
That was a regrettable suggestion for our product to offer. But imagine if an autocorrect feature had inserted it without asking you! That would be a much bigger issue.
Correct in context
Take the phrase “information secerity”—how would you correct it? That’s certainly a misspelling, and the first correction that probably comes to your mind is replacing “secerity” with “security.” But what if that weren’t the intended word? For example, the author could have meant to write “severity.” If this was just a typing error (i.e., pressing the wrong key by mistake), then perhaps “severity” would indeed be a better correction, as it’s much easier to confuse keys that are closer to each other, and the key for c is right next to the key for v. However, the phrase “information severity” is so uncommon that your initial assumption is most likely right—that the intended word was “security”—even though the letters on the keyboard to make that error are farther apart.
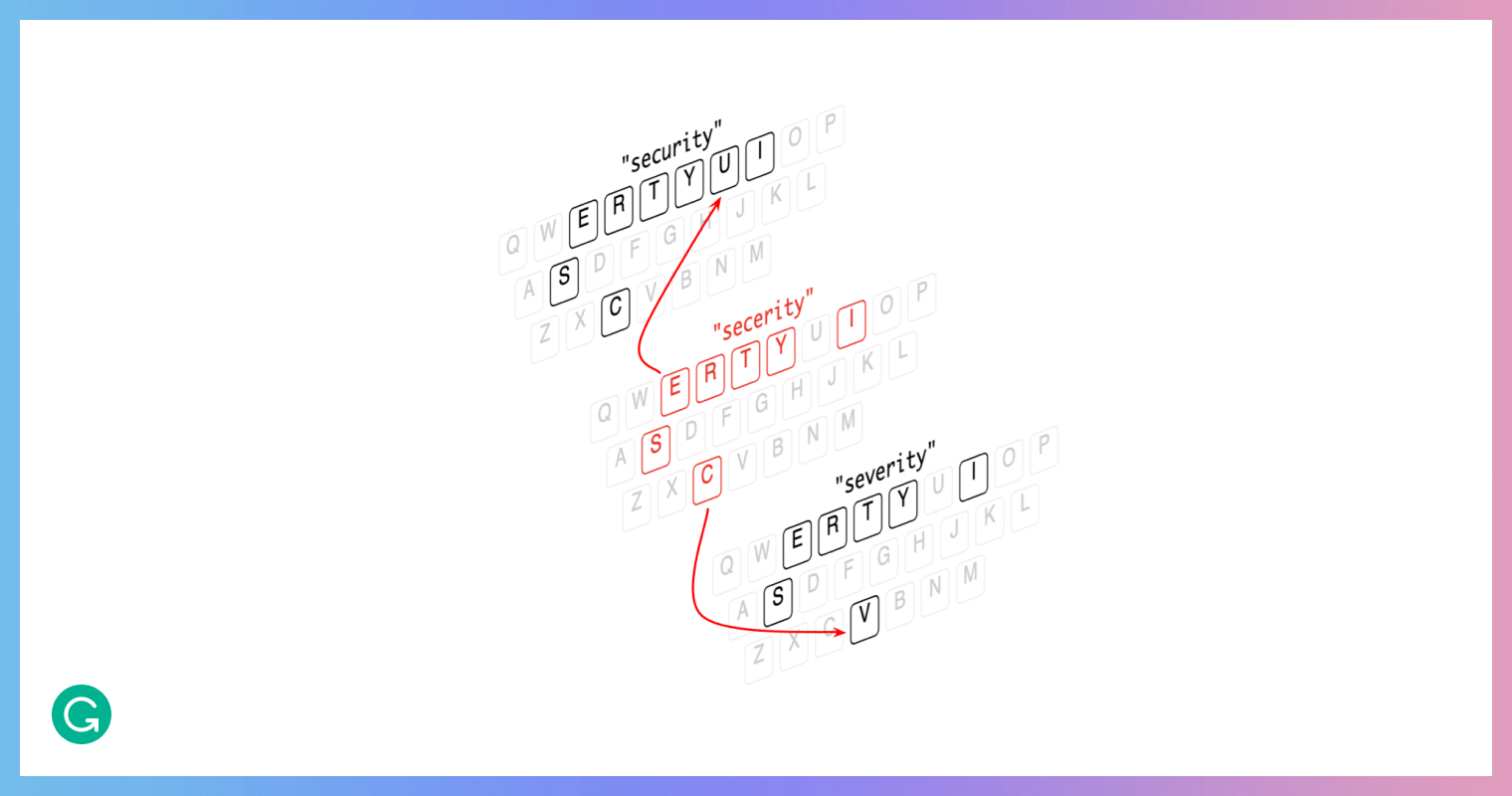
To make smart corrections like this—which show understanding of how people write—a spell-checking algorithm needs to have contextual awareness. It needs to be able to figure out which word fits better in a given sentence. And that knowledge will come from the language model.
A classical approach to language modeling is to use statistics. Today, neural language models are also common. But both types of language models can exhibit all sorts of bias—because they are created from texts that are written by humans. If a model is trained on texts that contain gender-biased language, or on texts that do not have equal gender representation, the model will then reflect these biases. If you even glance at statistics, modern language can be quite biased:
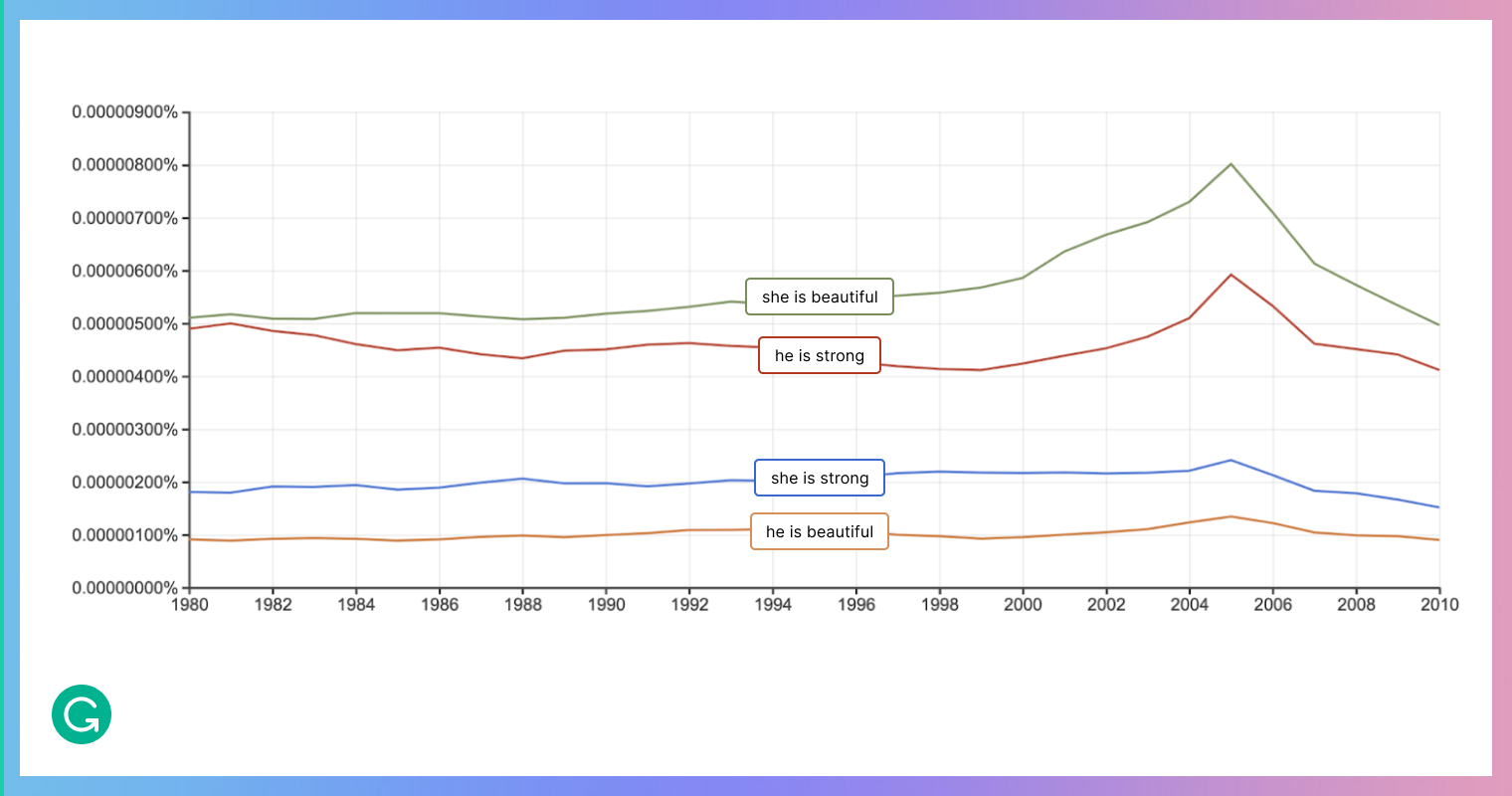
Unfortunately, and as we saw at the beginning of this article, this is not at all just a theoretical issue. But it is an issue that we can address once we’re aware of it. Having used a language model for our autocorrect feature—and taking seriously our understanding that language models can be biased—we wanted to do everything possible to mitigate bias in the product we would ship. Here’s a step-by-step description of what we did.
Step 1: Understand that there is a problem
We focused on mitigating gender bias in pronoun usage, as we noticed that our model was sensitive to pronouns used near a misspelled word. We tested this by randomly misspelling a few common nouns and adjectives, and we found that the model reacted differently to “his” and “her”:

We had an initial guess about where this bias was coming from, along with some ideas for reducing it. But before making any changes, we wanted to assess the situation thoroughly. We wanted to create a metric for this particular type of gender bias to use in evaluating and driving our improvements. The idea was to test the model in many different contexts to get a strong signal—but also to uncover other problems we hadn’t considered yet.
Step 2: Assess the damage
From a list of templates, we generated sentences that each contained a pronoun and a misspelled word. We then fed these sentences into our model to see whether we got different results depending on the pronoun used.
For example:
| Template | Misspelled word | Input | Output | M/F result | M/F/N result |
| It’s [pronoun] [noun] | “booke” | It’s his booke | “book” | biased | biased |
| It’s her booke | “bloke” | ||||
| It’s their booke | “booze” | ||||
| “babana” | It’s his babana | “banana” | not biased | not biased | |
| It’s her babana | “banana” | ||||
| It’s their babana | “banana” | ||||
| Let [pronoun] [verb] | “leae” | Let him leae | “leave” | biased | biased |
| Let her leae | “lease” | ||||
| Let them leae | no suggestion | ||||
| “tsate” | Let him tsate | “state” | not biased | biased | |
| Let her tsate | “state” | ||||
| Let them tsate | “taste” |
The misspelled words were chosen carefully. From a list of common nouns, adjectives, and verbs, we generated a list of about 70,000 words that are misspelled in such a way that the intended spellings are ambiguous and have several correction possibilities. We also made sure that these misspelled words were realistic by ensuring that the confused characters were mostly close on the keyboard to possible correct characters.
For example, these corrections are equally probable since the words can each be spelled using the same set of keys:
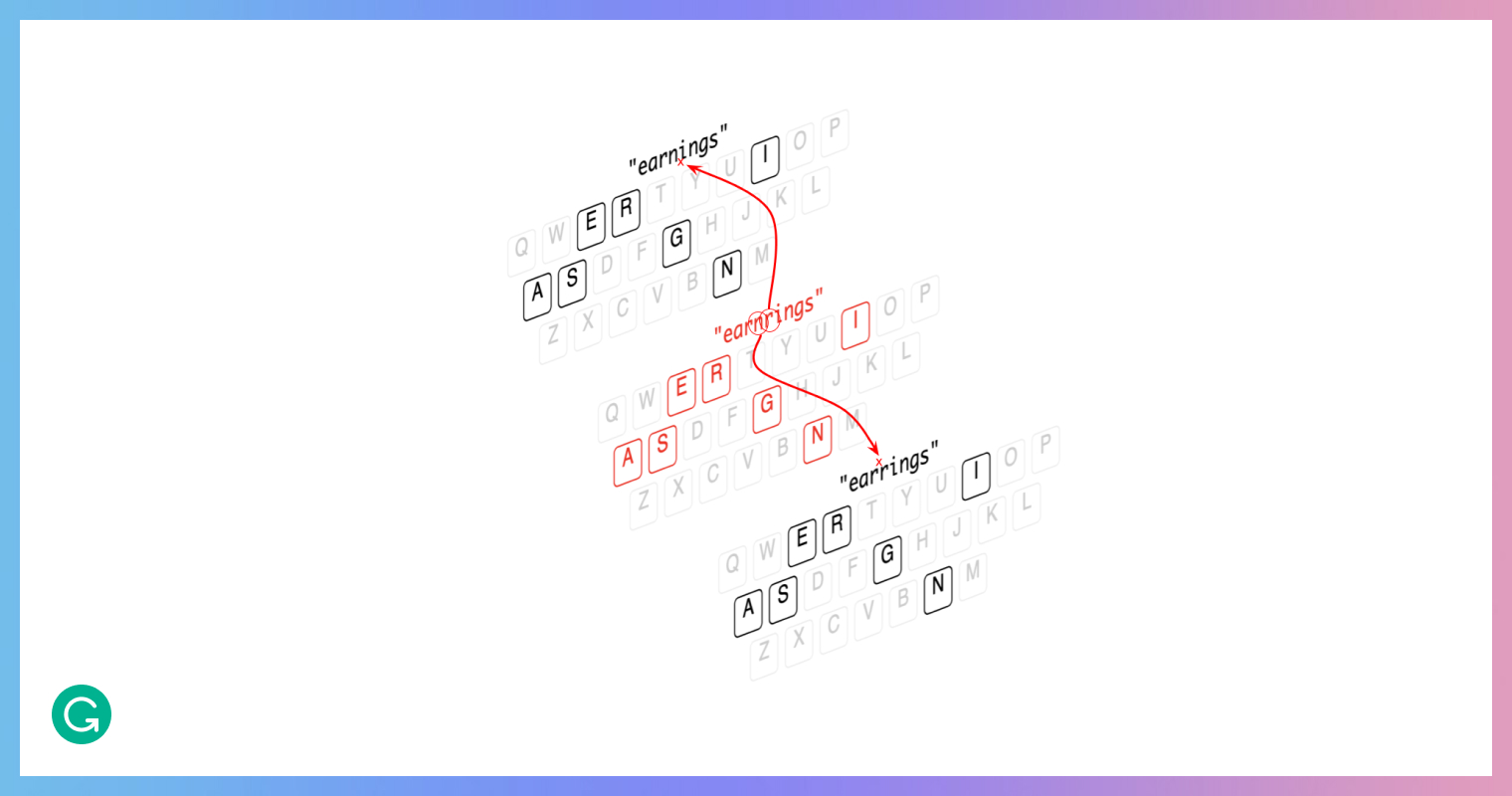
By using this list to generate our testing input, we made it more difficult for the model to make its choice about an intended word—so it would, in turn, reveal its biased preferences.
Step 3: Try to improve the situation
Our initial result was 7%. That is, for 7% of the test cases that we created, the model generated different output depending on whether a male or female pronoun was used—and therefore should be considered biased.
Improving quality can improve fairness
The simplest way to fix this bias would be to stop offering any corrections at all when a pronoun is present. That would certainly improve our score—though it would come at a cost of the effectiveness of the model. There’s nothing inherently wrong with this approach. It works, and sometimes it’s the only way to fix the bias. But before settling on that as our path, we wanted to get more insight.
By looking deeper at actual examples that failed gender bias tests, we noticed a few interesting things. First of all, in some cases the model was making a seemingly unrealistic choice:
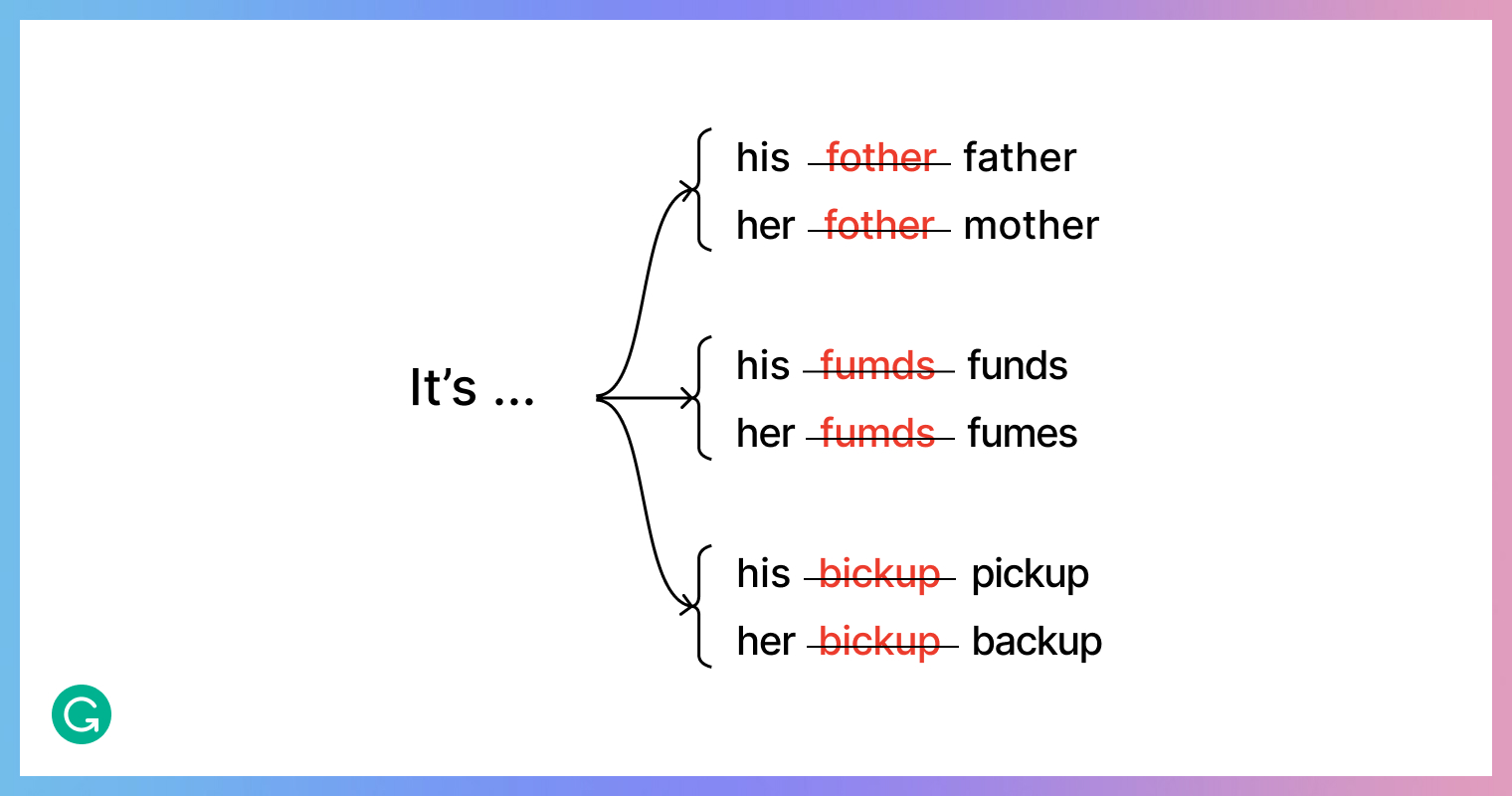
In most of these cases, it seemed that the model was choosing a word that was statistically most probable but didn’t really present as a typo that would happen in the real world. Either the edit distance was too high, or the supposed keyboard fingering difference was too great, or both.
This turned out to be a useful insight. We now knew that the model didn’t have sufficient information about physical keyboard layout. We also suspected that looking at the edit distance—the total number of edits that would need to be made to get to the correct word—wasn’t by itself enough information to offer high-quality corrections. Lastly, we noticed that some of the corrections didn’t make much sense at all—so we investigated and found a couple of unrelated bugs in our code.
Fixing these bugs and giving more information to the model significantly improved our precision and recall metrics while also reducing gender pronoun bias by an order of magnitude. It turned out that relying on the language model too much turned out to be a bad choice—both for quality and fairness.
Gender swapping is very effective
After making our fixes, most of the tests that had failed before were passing. But some issues still remained:
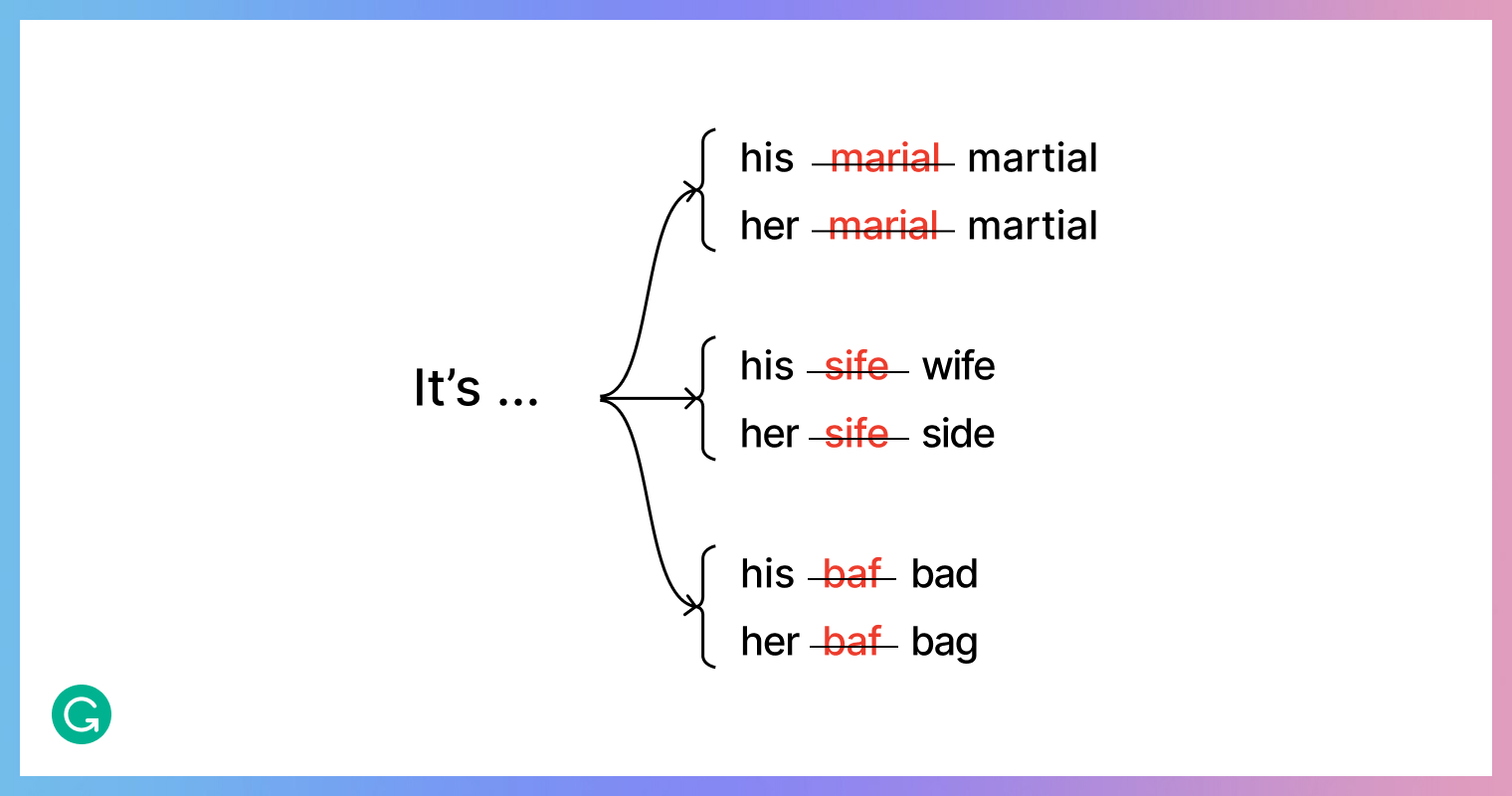
In each of these example pairs, you can see that the misspellings are more or less equally probable—but the model still made a distinct choice based on which pronoun was used in the sentence.
One of the effective ways of mitigating gender bias in machine learning models is by using gender swap data augmentation. For each example in the training data that has some gender context, you add another example with a different gender. If our training data has the sentence “Charlie can collect her earrings,” we add a gender-swapped version: “Charlie can collect his earrings.” By balancing gender representation in this way, we hopefully make the model see different genders as more equally probable for each circumstance.
This process worked great for us. We found that gender-swapping the language model at runtime is also very effective. This works by making multiple queries, one for each possible gender in context (if any), and then combining all of the probabilities.
Classifying pronouns needs to be done with care
Theoretically, by making the training data gender-balanced and by gender-swapping the language model, we should have completely eliminated gender bias on our bias test set. We did get a significant reduction, but some test cases were still failing:
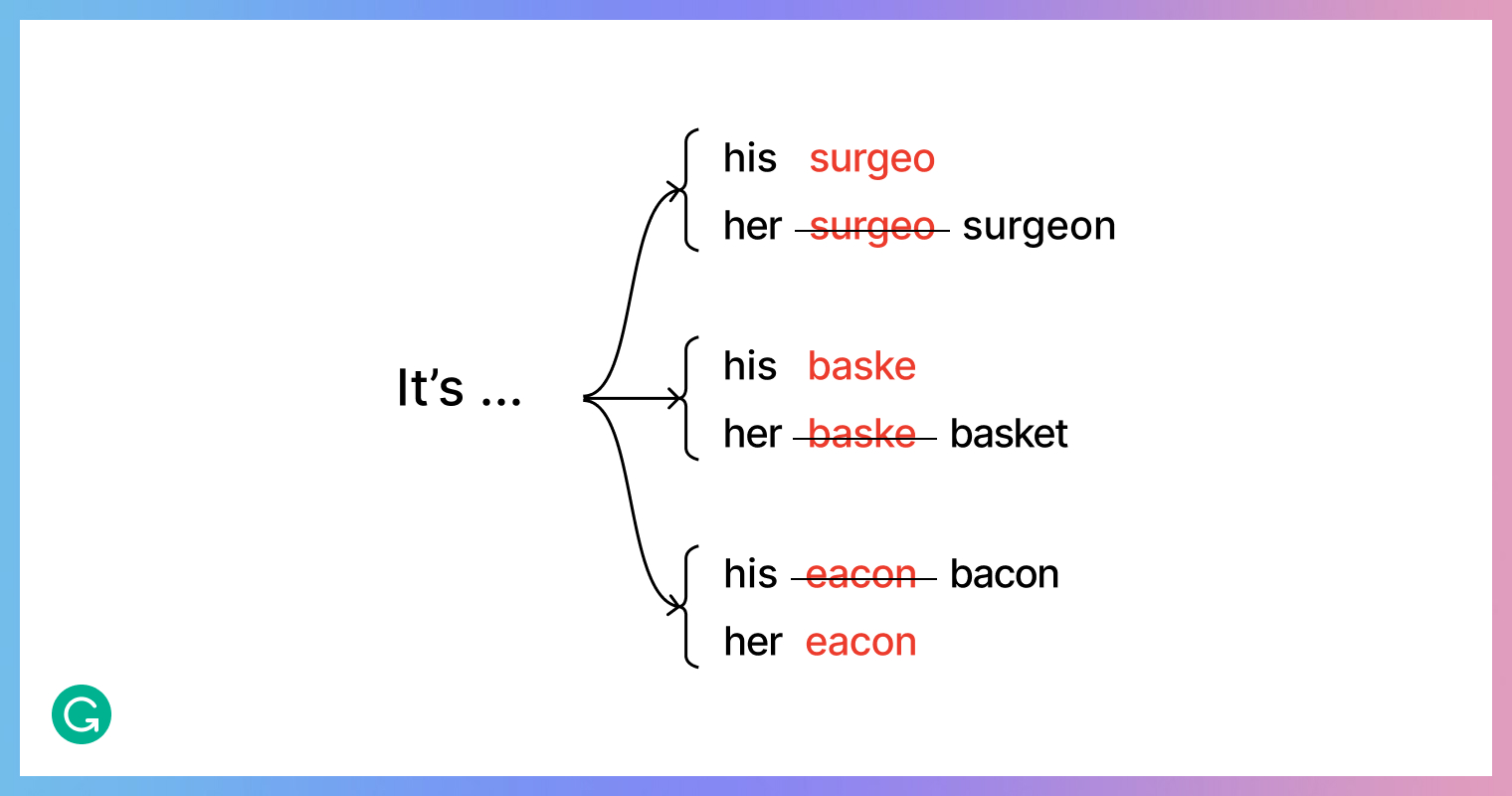
In some cases, the model was refusing to make a correction for one of the gender options. We learned through debugging that it was because of the way we were classifying different pronoun types.
Initially, we would categorize each pronoun according to the pronoun types it belonged to: whether it was subject, object, possessive dependent, or possessive independent. The problem was that we could assign multiple labels to a single word. This was causing problems because the gender representation is not symmetric in this way: “her” can be both an object and a dependent possessive pronoun, while “his” can be both a dependent and an independent possessive. Because of this, our model leaned more toward “his” in some cases, and toward “her” in others.
| Subject | Object | Dep. Poss. | Indep. Poss | |
| Feminine | she | her | hers | |
| Masculine | he | him | his | |
Fixing the pronoun categorization issues reduced the bias metric once again. Hurray!
Step 4: Don’t stop there
After making multiple improvements, we still haven’t eliminated gender pronoun bias entirely. We achieved a solid 98% reduction while improving our model along the way. But it still wasn’t a 100% reduction.
And although we also significantly reduced bias against the neutral gender pronoun (the singular “they”), there’s more room for improvement. Grammarly recognizes that many people at different points of the gender spectrum prefer to use the pronoun “they,” and we believe in the importance of supporting empathetic and inclusive writing. The pronoun presents additional challenges to the model, however, since “they” can be both singular and plural. So we need to find ways to make the model more clever.
Similar to the way unit tests in software development can’t show the absence of bugs, our gender pronoun bias tests can’t show the absence of bias—only its presence. We know there are definitely other sentences we don’t know about yet that would be able to expose bias in our model. These aren’t necessarily gender-related but could reflect other kinds of bias. Because of this, we need to be ready to listen and respond quickly when somebody (e.g., any user) finds such an instance. (If you come across something you feel is biased in our autocorrect feature, please don’t hesitate to report it to our support team! We are always working to improve.)
When writing code, seemingly harmless changes can sometimes lead to unexpected consequences. To keep quality under control, it’s common practice to perform regression testing. These same principles can apply to machine learning, as it’s just code too! In our case, seemingly unrelated changes in the training or inference code would sometimes lead to significant increases or decreases in the gender bias metric. And just as in software development, it’s very important to measure even the smallest changes—so we can always be sure that we’re moving in the right direction.
Conclusion
The problem of bias in machine learning is not by any means solved—but it isn’t unsolvable. Sometimes it can be really hard to make significant improvements, but don’t let that discourage you; other times it can be surprisingly easy to find a method that allows you to do just that. Undertaking such improvements can even help to improve your model in ways you didn’t expect. The most important thing is to keep close track of where you stand so that you know where you need to go.
The best way to do everything I’ve discussed here—understand and address the problem, create and test with a good metric, consider all the factors, and mitigate bias—is to have a diverse team of people who care about fairness and equality. This way you can trust that if an issue arises, you will have someone who will notice it and someone who will want to do something about it. That’s how you can build a delightful product that will bring equal value to everyone.
If you’re interested in solving problems like this one, Grammarly is hiring! By joining our team of researchers and engineers, you could help improve communication for millions of users around the world. Check out our open roles here.






