

As an engineering organization grows, infrastructure that was previously helpful can become a bottleneck. Grammarly built an in-house data lake and business intelligence (BI) layer solution called Gnar in 2015. By 2022, Gnar began to show signs of significant scalability issues. The volume, velocity, and variety of event-based analytical data at Grammarly produced by over 40 internal and external clients began to rapidly outpace Gnar’s capabilities. The underlying architecture and design also prevented us from easily modifying it to enable new capabilities, teams, and projects for Grammarly’s next level of growth.
So we embarked on a complete redesign of our data platform, utilizing technologies such as Spark Structured Streaming, Delta Lake, and Databricks Unity Catalog. In this post, we’ll share our journey, including important lessons we learned from migrating and backfilling over 6,000 different event types from 2015 to the present day and streaming into over 3,000 Delta tables daily. Along the way, you will gain insights into the challenges we faced building a new data platform, Grammarly’s Event Store, from scratch.
Background
Gnar allowed any client to send a JSON event with no end-to-end schema enforcement. We chose this approach because it enabled rapid experimentation and ease of use for clients to start sending analytical events. Under the hood, Gnar stored all events in one table-like structure called an Index, partitioned by event name and time into chunks of 2–3 million records. All data was stored on Amazon S3 in Parquet format. A MySQL metadata layer allowed us to query the correct files from our data lake; we used a custom DSL query language to abstract common analytical queries like retention, funnel, and user segmentation. All analytics at Grammarly leveraged this DSL to query our user behavior data.
As the volume of data increased over time and the system began showing signs of scalability issues, we invested in optimizing the existing Spark pipeline to reduce performance bottlenecks, allowing us to scale the pipeline end to end to process more data in less time. However, as we continued to grow, it became clear that a bigger redesign was needed to achieve several important goals:
- Let teams across Grammarly query our event-based data using SQL, allowing them to build their own pipelines, dashboards, and real-time alerting.
- Enable scalable feature-engineering infrastructure such as a feature store, a system that allows ML engineers to easily create and store features in offline and online databases.
- Improve our ability to audit and provide fine-grained access controls to our data while making it easy for users to discover data at Grammarly through a unified data catalog such as Databricks Unity Catalog.
- Accomplish all this with a system that meets our high standards for data security and privacy.
This redesign would also align with our long-term vision to introduce end-to-end schema management with Kafka for producers and consumers to improve data reliability and quality while reducing storage and computation costs across our entire infrastructure. As a first step to realizing this vision, we needed to migrate to a new, scalable Event Store that would allow for strict schema support and schema evolution. Our Event Store is a centralized data storage layer within our data lake for all event-based data at Grammarly. Schema management with over 6,000 event types and no strict enforcement had started to create many operational and data quality issues that needed to be addressed in the new data platform.
Approach and challenges
To develop our new Event Store, we chose Databricks as a platform, as we are heavily invested in Apache Spark and needed a scalable, secure, and collaborative environment to unify all analytics, ML pipelines, and workflows for Grammarly’s next level of growth. We settled on an open-source storage layer with ACID transactions that’s fully compatible with Apache Spark APIs using Databricks Delta Lake. In the new data lake design, each unique event type in the Event Store is stored in a separate Delta table, allowing each event to have its own schema that can evolve and enabling each table to scale independently. From this foundation, aggregate tables or composite views can be built for downstream pipelines or consumers using either SQL or BI tools such as Tableau.
We faced three challenges in migrating our system from our custom Gnar data layer to our new Delta Lake data platform.
- Merging event schemas and handling schema incompatibilities: how we defined schemas for over 6,000 different events
- Rebuilding our ingestion and storage layers in Databricks: how we deconstructed one giant Kinesis stream with nearly 3,000 unique events and mapped it to individual Delta tables (out of the 6,000+ total events in Gnar, around 3,000 are still in active use)
- Backfilling all our data from 2015 into our new Delta Lake: how we merged historical data to conform to the new schemas (including initial failures)
1 Merging event schemas and handling schema incompatibilities
Our first challenge was defining schemas for each of our analytics events. There were over 6,000 different events, with multiple schemas used to log them. In Gnar, we would infer the schema for each event that came into our system and store the schema in a MySQL table. Using this table, we knew all the possible schemas for an event since its inception. We needed to design an efficient and scalable way to merge all the known schemas for an event into one unified schema and create over 6,000 individual Delta tables.
For each event, we potentially had thousands of known schemas stored in our MySQL database. We created custom code to recursively merge two StructTypes into one StructType, handling nested Structs and Arrays and upcasting when possible. We then reduced all known schemas for an event into one unified StructType schema that could be used to bootstrap the initial Delta table. For columns that had multiple incompatible data types, our code selected one column at a time and stored a list of all known data types for that column. We used this information to determine the most common incompatible data types and built a generic way to transform or cast an incompatible data type to a target data type (such as String to Boolean). For complex transformations (like String to Array), we stored the raw data in a Map column called “_raw_transformed_data”—this preserved the raw data for that column and prevented our streaming or backfill jobs from failing with incompatible data type errors. And it allowed us to develop offline jobs that used custom code to convert incompatible data to the right data type.
2 Demultiplexing: Writing a stream of 3,000 events to individual Delta tables
The next challenge was rebuilding our ingestion and storage layers in Databricks. We needed to take one giant Kinesis stream containing 3,000 unique active events and map those events to individual Delta tables. We decided to adopt the Databricks Medallion architecture. Our Bronze layer would consist of a landing table ingesting raw JSON data and a validation table for events that pass our data quality checks. From the Bronze validated table, multiple streaming jobs deliver the events into a Silver layer, with each event type paired with an appropriate Delta table. The Silver layer enforces a strict schema with schema evolution enabled.
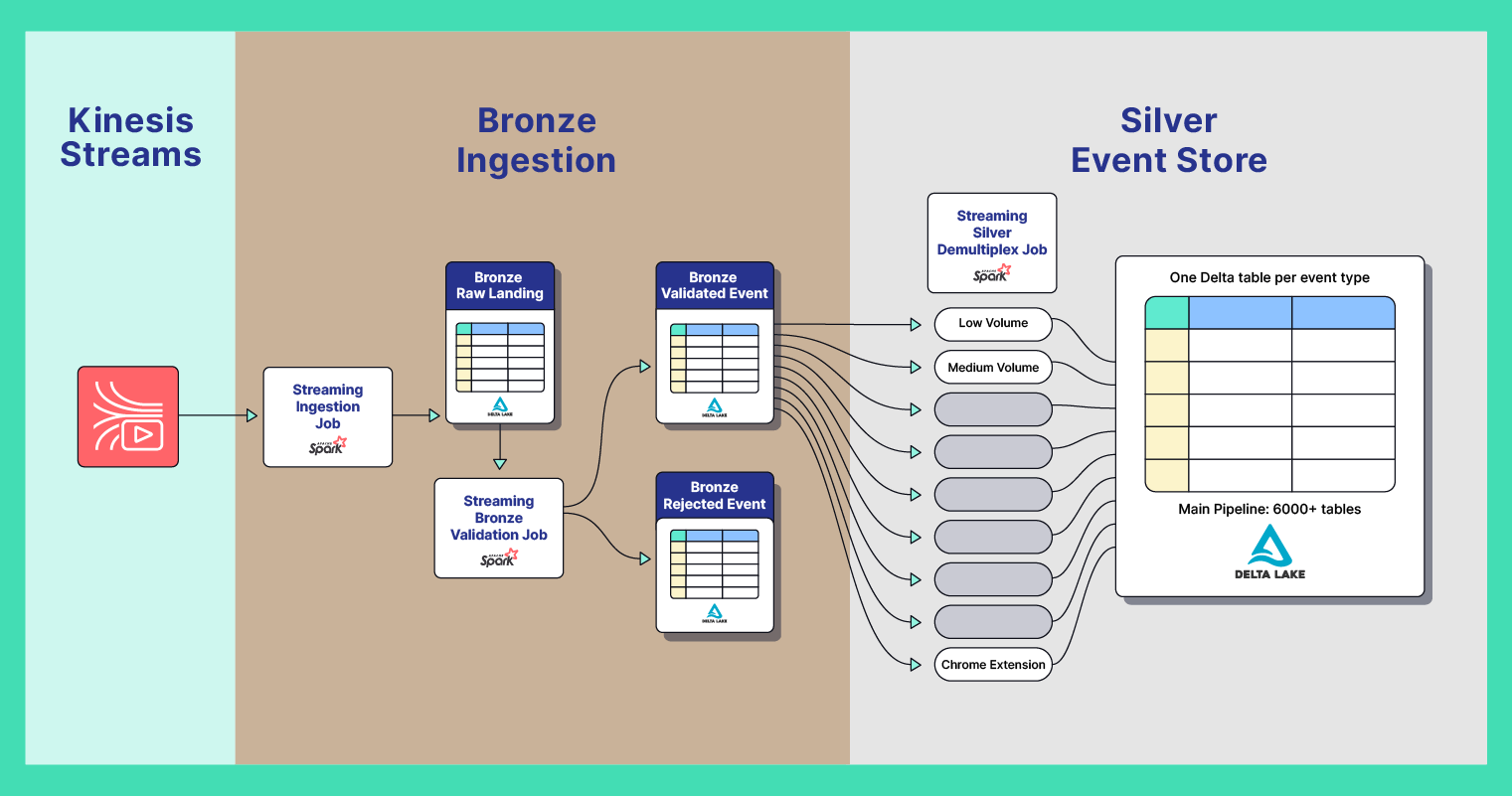 Event Store system design diagram with Bronze ingestion and Silver-layer demultiplex.
Event Store system design diagram with Bronze ingestion and Silver-layer demultiplex.
From the Bronze table of validated events, we built a Spark Structured Streaming job called the Demultiplexer that does the following:
- Takes in a stream of heterogeneous JSON events
- Filters for events for a known client such as `ChromeExt` or `SafariExt`
- Within a `foreachBatch`, does a parallel `foreach` using Scala parallel collections to start multiple concurrent Spark streaming jobs
- Filters events within a batch by event name
- Infers the schema and explodes it out from a nested Struct column
- Performs a `MERGE INTO` the final table
- If a schema mismatch is detected with `AnalysisException`, it gets the column names from the error message and attempts to transform them to the target type of the table or write to the _raw_transformed_data column
One of the trickiest aspects of the demultiplexing project was figuring out the right partition structure for events in the Bronze table. During testing with an original partition of year, month, and day, we discovered that it was not feasible to spin up one giant cluster that could read from the Bronze-validated Delta table and write to 3,000 different events ranging widely in the volume of events per micro-batch. So, after analyzing our data and daily volume, we devised a new way to partition events: by the client that sends us the event. This allowed us to create more than 40 different partitions in the validated events table while also partitioning by year, month, and day.
Using this new partitioning structure, we could spin up individual clusters for high-volume clients that were scaled appropriately and group low- and medium-volume clients into smaller clusters for better performance and resource utilization. This significantly improved the reliability of our pipeline, as a problem with one client no longer impacts the streaming of other clients. We can also scale each cluster appropriately for the size of the data and adapt to changing ingestion volume for individual clients.
3 Backfilling 6,000 tables from 2015 to 2022
The most challenging part of this migration was backfilling: taking our entire data lake, which could only be queried using our custom DSL, and translating that data into the correct schema of the target Delta table for each event. This was especially complex because there had never been any schema enforcement in our pipeline previously—a client could change any data type for any column, and Gnar would store these as separate Parquet files for the same event.
To perform the backfill, we were able to reuse much of the code in our Structured Streaming Demultiplex job, but we also had to account for a change in how we stored time data, from Pacific Standard Time (PST) in Gnar to UTC in the Event Store. We heavily leveraged Databricks’s ability to create individual Databricks jobs and automated much of the backfill by kicking off a backfill job for each client, which was configurable by date. Since each client has a wide variety of data volume and size, a lot of effort was spent tuning and tweaking our backfill clusters and code to effectively run as many jobs in parallel as possible.
Our first attempt at the backfill was not successful, as it left many data gaps in data due to schema mismatches and other silent job failures. To debug these issues, we built a data quality automated job that compared the counts and data in both systems for our real-time ingestion pipeline and repurposed this code to run automated data quality checks on the entire backfill. The Data Infrastructure team partnered with the newly formed Data Engineering team to build more complex tooling and reporting to understand the backfill problems. Our automated validation job now gathers statistics for specific columns—such as `struct`, `array`, and `map`—and reports event-based outlier intervals. We were thus able to identify specific data gaps from our first backfill attempt, such as missing date ranges, null columns, and missing events. This allowed us to focus our attention on these problems and work in iterations to eliminate issues in waves while double-checking that there were no new ones.
Our Data Engineering team put together a comprehensive plan and strategy for how to efficiently backfill. There were issues casting complex data types such as `StructType` and `ArrayType`, causing the backfill job to throw an error and null out the data. To handle these cases, we retrieved the raw JSON from Gnar using the `to_json` Spark function and then parsed it using the `from_json` function with the data type from the target Delta table schema to correctly cast the data. We invested a lot of time and engineering effort to get the backfill right so we could be confident that our internal customers could rely on the new data.
Lessons we learned
One of the big lessons we learned was the importance of schema management and enforcing schemas early on to improve data reliability and cost. Our existing system allowed for rapid experimentation and ease of use for clients, but scaling a pipeline that used JSON strings for all ingestion and enrichment has been costly in terms of cloud resources and the engineering effort required to maintain it. We also have shifted from using a custom data lake storage format and query language to adopting open-source big data technologies to allow us to focus on delivering value to our customers, instead of reinventing the wheel.
We underestimated the effort that would be required to backfill our existing data due to the number of events, range of backfill, and schema incompatibility issues within each event. Improving our data quality tooling and reporting early on would have surfaced data gaps from the start of the migration and saved our Data Engineering team a lot of time debugging data mismatch problems between the two platforms. On the other hand, adopting Spark Structured Streaming allowed us to reuse much of our streaming code for backfilling, saving us a lot of engineering effort—we didn’t have to build two separate jobs for real-time ingestion and backfilling. Automated data quality and alerting is an area we are actively working on as we make the final switch to our new platform.
Impact
This foundational work has enabled us to accelerate the adoption of Databricks as a unified platform for data, analytics, and AI workloads at Grammarly. It’s allowed our Data Engineering team to build downstream rollups and aggregates for teams to save costs and improve query performance. We’ve used the data in the Event Store to create more than 100 features powering the Growth and Data Science teams’ models for the feature store. By switching to an end-to-end streaming architecture, we’ve also reduced the time it takes to make data available by 94 percent, allowing us to better serve our internal customers with more reliable and fresh data. This project also set us up for the next phase in the development of our platform: to provide end-to-end schema-based ingestion using Avro and Kafka for all clients across Grammarly.
If you like solving big problems and dealing with massive amounts of data, join us.






