

Declarative programming can help you write code that’s more concise, easier to read, and mistake-free. In other words, declarative programming can improve your code in a similar way to how Grammarly’s product can improve your writing! With declarative programming, you tell the program what to do without specifying how it should be done. By contrast, imperative programming focuses on the control flow and state changes of a program.
These definitions are pretty abstract and can be confusing. So we’ve put together this article to provide a survey of many real-world examples of declarative programming, with a specific focus on .NET and how it’s pushing the declarative paradigm forward with C# and F#. We will also give a few examples of how we use declarative programming at Grammarly, particularly on the team that works on our add-in for Microsoft Office. We hope that after reading, you will understand the power of this programming paradigm, learn some new applications, and know enough to continue exploring related topics that spark your interest.
The declarative paradigm is everywhere
To get in the mindset of thinking declaratively, we’ll start with a few overarching examples before diving into actual code.
Functions
First, let’s imagine a simple function that you probably know from school: f(x) = sin(x). What are you picturing when you think of this function: A or B?
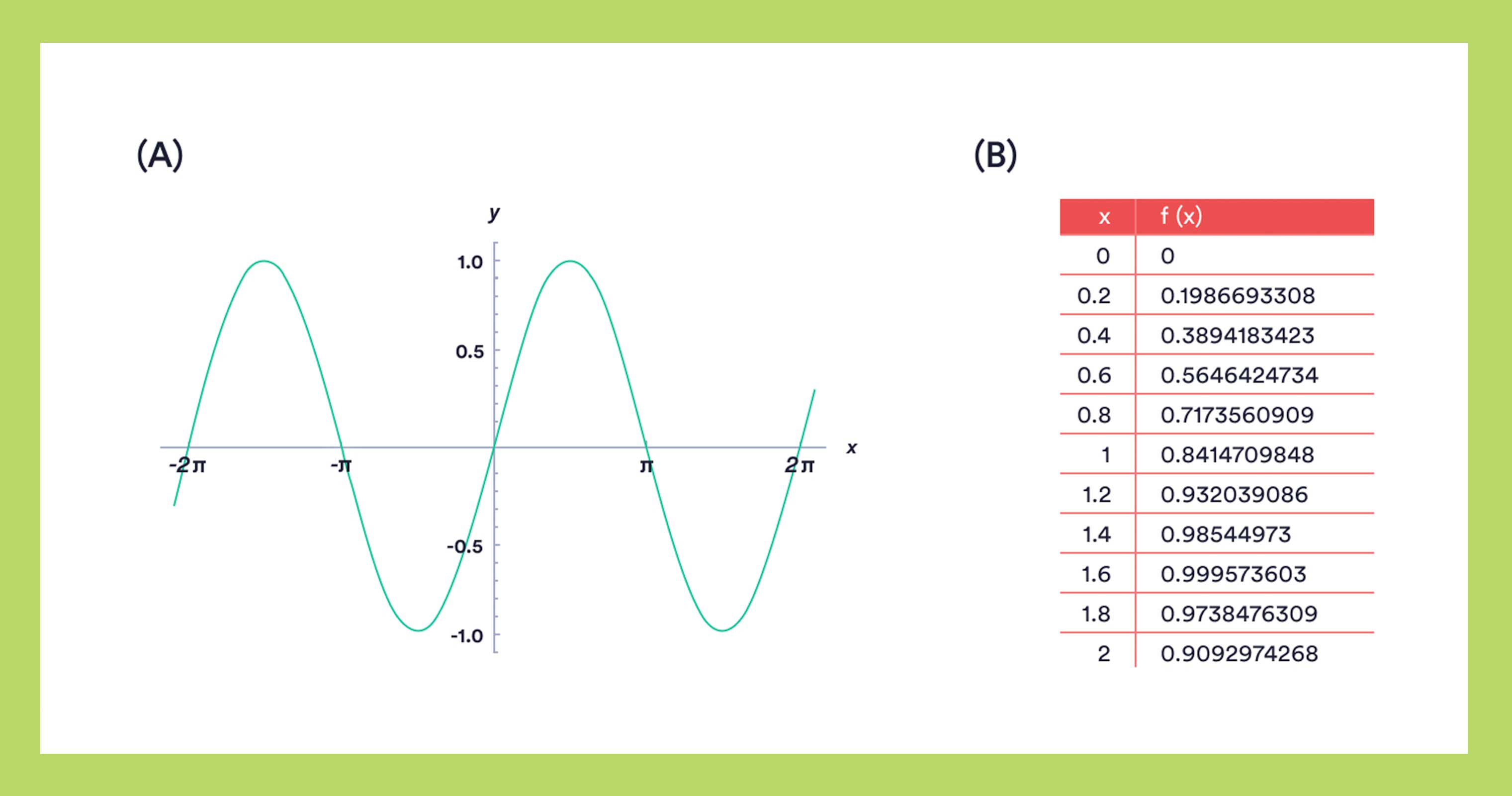
You’re probably imagining A, right? To understand a concept like sin(x), you don’t have to recreate it step-by-step. Unless you need to get some precise output, your brain doesn’t have to do any calculations; it knows the relationship that’s being represented, and that’s enough. This is the key insight behind declarative programming.
DSLs
Even though some declarative programming concepts might sound new, this paradigm has been around for a long time. It’s probably safe to say that every modern programmer is familiar with domain-specific languages, or DSLs, such as SQL, HTML, and XML. But at one point in time, these languages were brand new and their declarative strategies were cutting-edge.
The innovation of HTML was to simply declare how elements on the screen should look rather than use a graphical API to tell the browser what specific renderings to perform. This gives the browser the ability to apply optimization techniques under the hood without breaking existing pages.
In the early days of databases, SQL represented a declarative breakthrough as well. At the time, querying databases required specific knowledge of the workings of the database itself. But SQL was about simply declaring what data is needed—and nothing else. The rest of the work, like query optimizations, indexing, and cache usage, is done by the DB engine itself.

There’s a pattern here: Although declarative programming seems to do less, we’re actually getting more in terms of flexibility and extensibility.
MVU
A more modern example of declarative programming is the Model-View-Update pattern for UI. In this pattern, the View is the declarative part that says what the behaviors and UI should look like, and it’s separate from the Model (the data). This helps programmers write code that can handle complex, asynchronous events while still managing to be readable, robust, and efficient.

Declarative programming in .NET
Let’s move on to introducing some practical tools for using this declarative paradigm in the .NET environment. Along the way, we’ll show you code that uses the more familiar imperative approach so you can see the improvements.
Making your C# code more declarative
Let’s start with a trivial example in C#. By taking a closer look at this approach, we can see the risks that one would usually want to avoid.
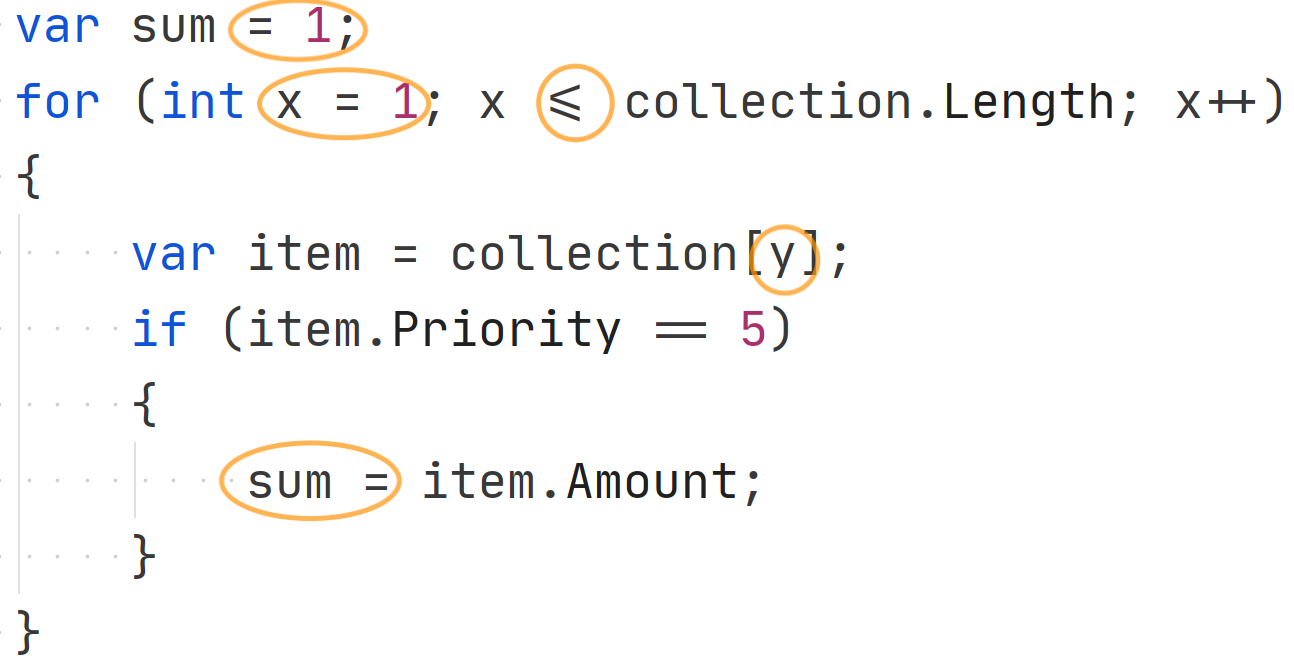
This is good old imperative programming: To traverse a collection, we manually specify each step and operation. By taking a closer look at this approach, we can see the risks that one would usually want to avoid.
- Using an iteration variable: The variable
icould have the wrong initialization or the wrong increment, and if we’re inside a nested loop, we could accidentally mix up our variables. - Accessing the item by the iteration variable: During access, we could use the wrong variable or accidentally modify it. We could also get a
System.IndexOutOfRangeExceptionif we weren’t careful enough about defining our loop. - Accumulating the sum manually: What we want is to sum the items that have a certain property, but we don’t actually care how this is done. In fact, our computer knows how to do this already. So why are we doing the work to write it manually in code, opening us up to human errors or suboptimal strategies?
The first thing we can do to improve this code is to remove the iteration variable—we don’t actually care about it, after all. Its only purpose was to give us access to the current item in the collection.

To go even further, we can eliminate the imperative if statement as well as the manual summing. Our aim is simply to sum amounts for items in a collection that have a certain property. The following code declares that intent without any unnecessary details:

The shift to functional C#
When we look beyond one simple example, we can see even more possibilities. There are powerful tools emerging in C# to make the whole language more functional (functional programming is a type of declarative programming that expresses computations directly as a pure transformation of data). C# has always had a close relationship with the declarative paradigm. Many of its familiar features, like LINQ, async/await, and higher-order functions—and later on, pattern matching and more—came from Microsoft Research’s work on functional languages like Haskell, F#, and others. Now, as declarative programming in C# is becoming more popular, C# itself is changing quickly to become a more declarative language.
Here are some new concepts to look out for in C# that can make your programming more declarative.
Expressions
C# is making an important switch from a more statement-based syntax to a more expression-based one. Statements, which are imperative, exclusively produce side effects, while expressions, which are declarative, use limited language constructs to produce new value (and maybe side effects as well).
It’s usually easier to compose program parts out of expressions rather than statements, and expressions are more universal (you can’t pass a statement to a lambda function, for example). Here’s an example of the difference.
Statements vs. expressions
Below are functions that take an argument and store the result in the variable sum. All the functions that begin with Plus are statements—they do not produce a value but rather create side effects by modifying sum:

And below is the exact same idea rendered with expressions:

The benefits are clear. We don’t need to keep track of a sum variable, or any other variable, because we’re using nested expressions and there are no intermediate results that we have to worry about. We’re able to represent this idea in 9 lines of code instead of 32.
Pattern matching
Pattern matching is another idea that comes from functional languages. Let’s take a look at the latest and most advanced kind of pattern matching in C#.
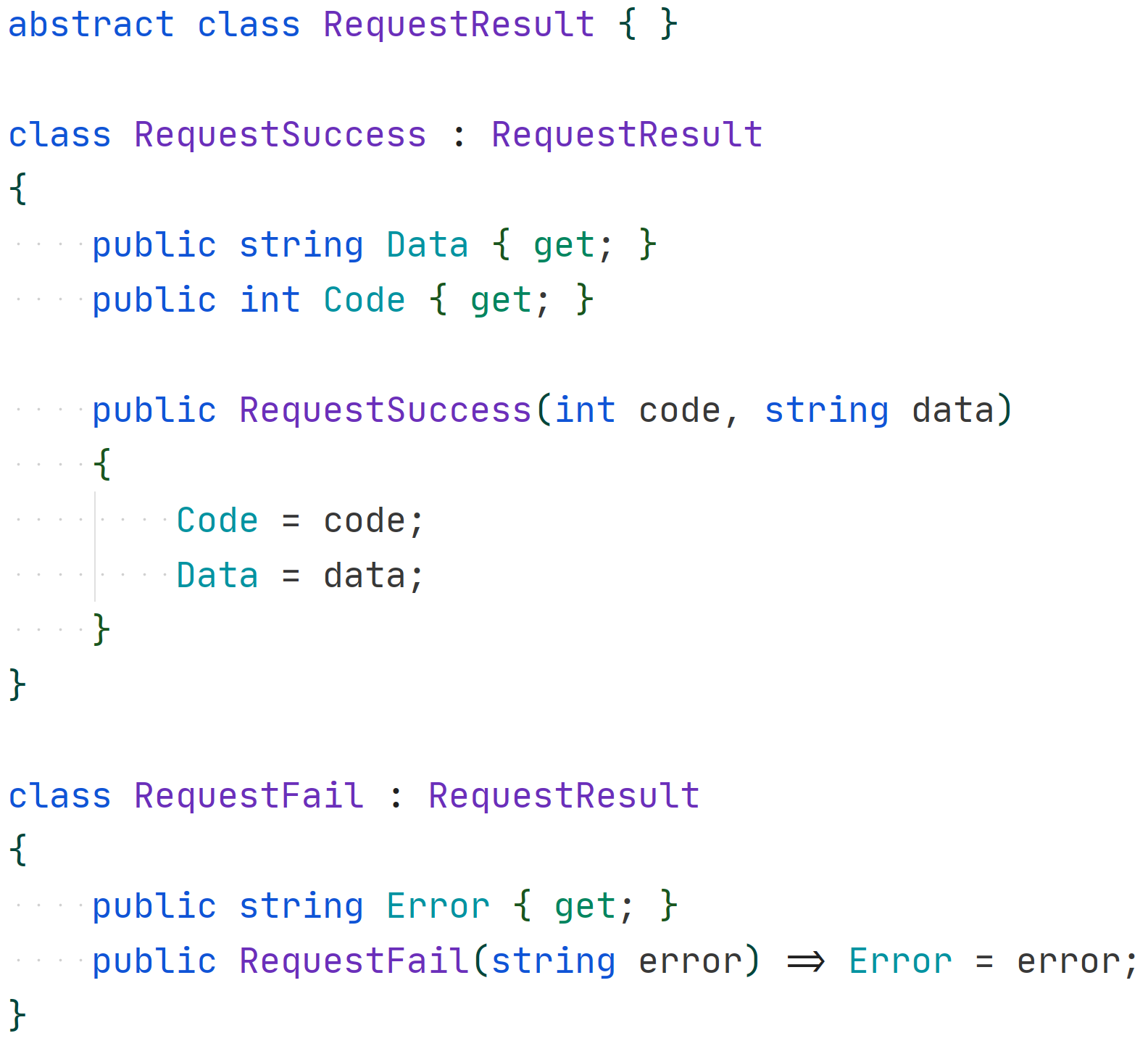
Here’s an example of some declarative code for outputting information about the success or failure of certain requests using expressions and the new pattern-matching syntax in C#.
Type definition:
Usage:
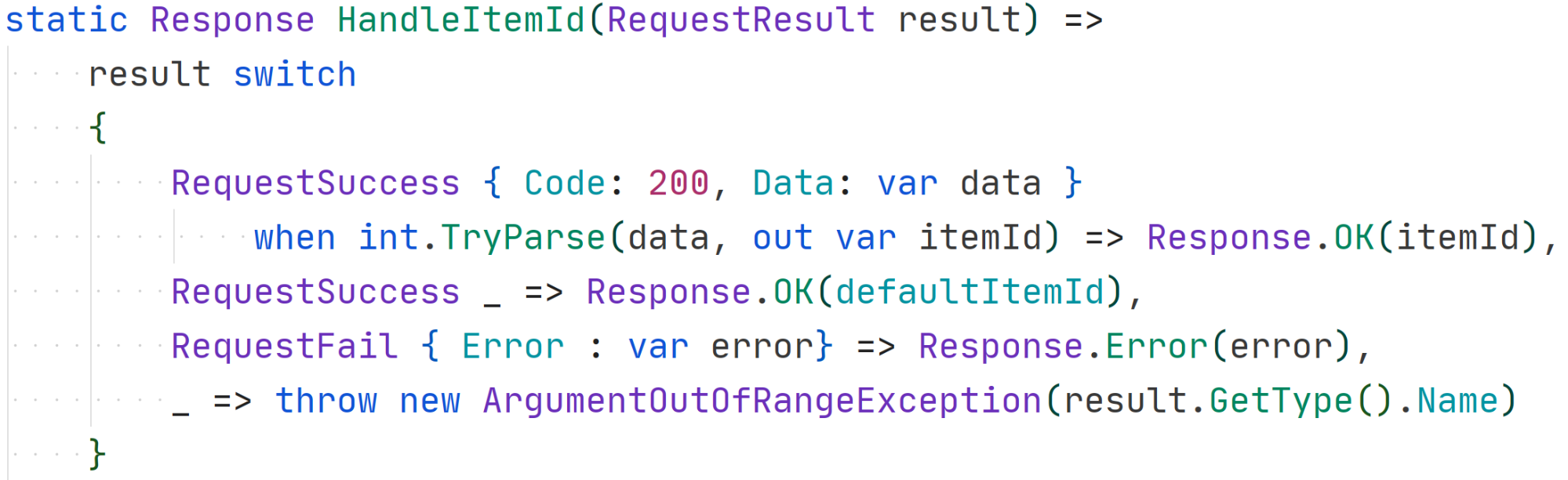
This new syntax, including the new expression-based form of switch, is declaring what we want the code to do rather than how to do it. When Code is 200, we use pattern matching to parse the data to an integer. We’re also able to retrieve the data variable without needing to use any other variables to reference it manually.
Let’s compare this to how the code might have been written before the new declarative pattern-matching syntax:
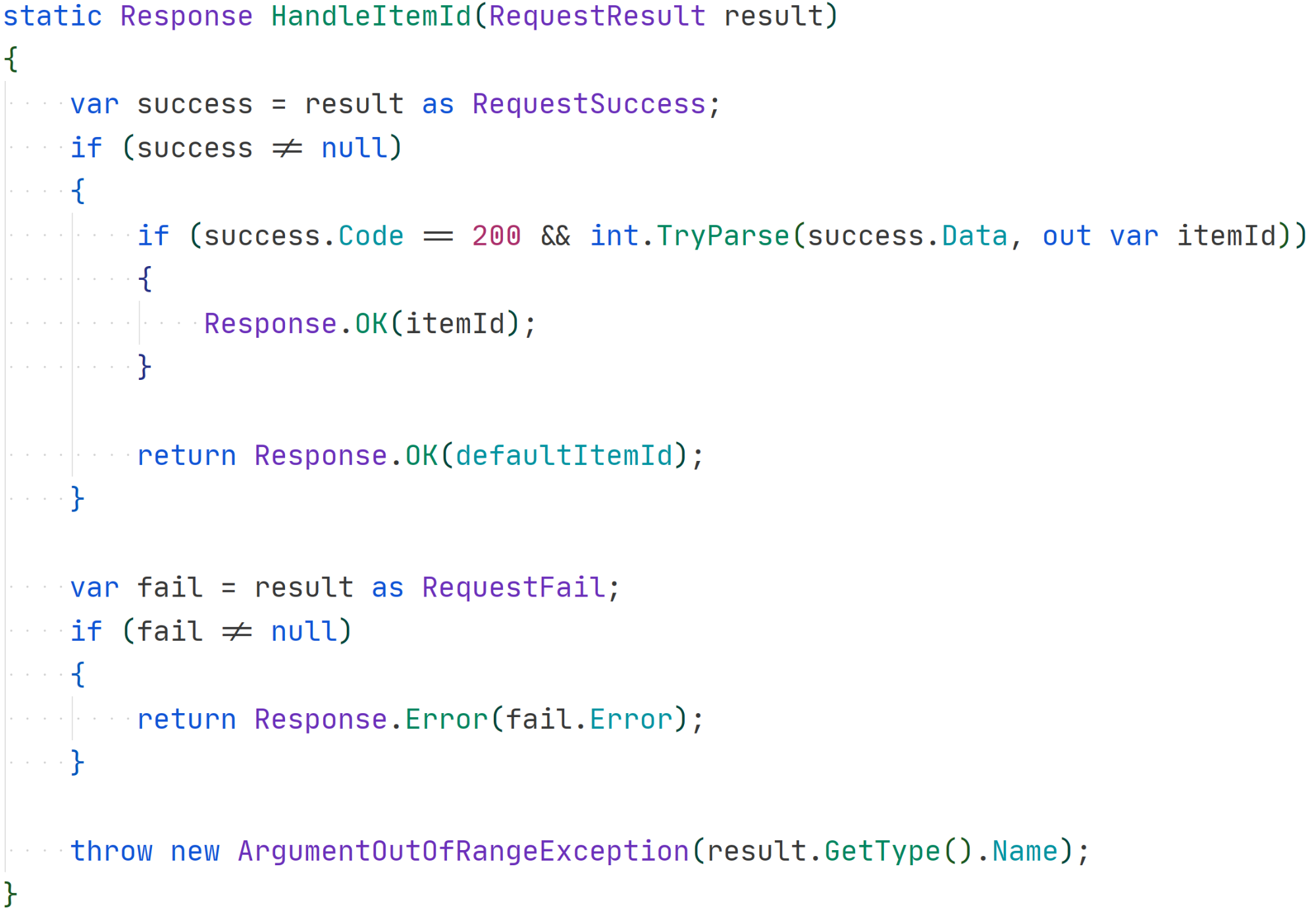
This imperative version is much more verbose, and it’s also much more error-prone. To illustrate this, we left out a return statement on line 9 on purpose, and the compiler said nothing about it. This error will be noticed only at runtime—and if there are no tests, it could even persist in production. Here’s an example of how declarative programming can help you catch bugs earlier, when they’re much cheaper to fix.
Advanced declarative programming with F#
F# is a “functional-first,” cross-platform, open-source language. Declarative languages like F# borrow from proven math research like lambda calculus and type systems research (and category theory), but that doesn’t mean they’re just for math applications. F# is a general-purpose language that can help you write many different types of software applications.
Having reviewed some of the latest C# features for declarative programming, let’s now look at how F# can provide us with even more powerful ways to leverage this paradigm.
First-class functions
To program declaratively, you will often want to treat functions as “first-class” values, meaning functions can be passed as parameters, accepted as arguments, assigned to variables, and so on. C# has first-class functions, but F# makes them much more flexible and convenient to use.
Here are some examples of first-class functions in C#:

That same code looks a lot nicer in F#:

Let’s go over some of the basic F# syntax. In F#, you can think of whitespace between a function and its arguments as an “operator” with the highest precedence: It applies the function to the argument on the right. All functions in F# are single-argument functions. But of course functions have to be able to take more than one argument—so how does this work? In F#, any function with more than one argument is, under the hood, a function generator. It takes the first argument and returns the function that takes the next argument and returns the function that takes the next argument…and so on (it’s functions all the way down!).
Piping
“Calling functions with arguments is so boring,” some of you might be thinking. “What if we could call an argument with a function? That would be fun!”
Well, F# has got you covered. Meet the pipe-forward operator, |>.
![]()
Above, we have the boolean literal true and the function not that reverses it. It looks like the boolean and the function swapped places, and the pipe-forward operator helped them do so. In fact, the pipe-forward operator is nothing more than a regular function that takes the argument and functions in the reverse order, and, under the hood, applies the function to the argument.
You might be wondering why anyone would want such a thing. For a single operation, it’s not that beneficial. But the pipe-forward operator provides a very clean way to structure chains of computations. If you’ve worked on Unix systems, you’re probably familiar with how piping helps transfer textual information from one command to another. Using the below example, for instance, we can easily isolate all the lines related to the metric we want to examine:

Function composition
Another powerful technique in F# is the ability to easily combine functions using the function composition operator, >>. In the following code snippet, we’re trying to map a list of numbers in such a way that each element is incremented by 2 and then multiplied by 3.
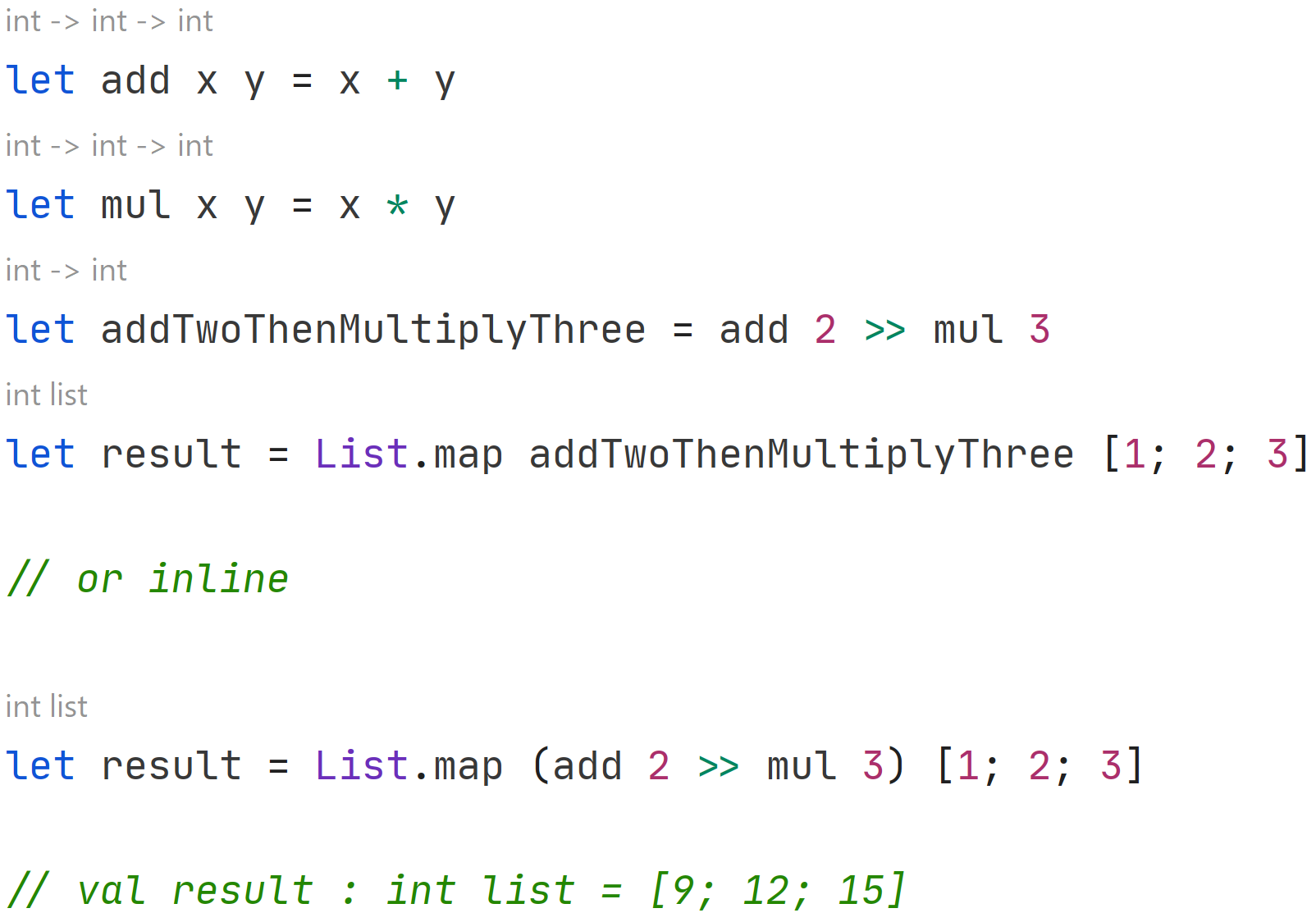
The operator >> essentially takes two functions and performs them in sequential order. It generates a new function that applies the function on the left first, then takes the result and applies the function on the right to it. By using the function composition operator, we can easily declare our intent in a fairly intuitive way.
Note: There are other operators for functions in F#, but at their core they’re just different variations of the main ideas we’ve reviewed. For more reading, you can look at F# documentation.
Example: Collection operations with F#
Let’s return to the example we started with in C#. We rewrote a snippet of imperative code, which summed the items in a collection with a certain property in order to be more declarative. Remember the result?

In F#, this already simple code becomes even simpler. It reduces to a single line:
![]()
Let’s break down what’s happening here.
Item.Priority’andItem.Amount’are just static functions that return these properties, pretty much the same as we have on the C# version inside the lambdas.(=) 5creates the equality function by using a partial application.>>composes the function on the left with the function on the right.
You might notice that there is no actual function argument anywhere—we don’t need it! We’ve eliminated another potential defect: using the wrong variable inside the lambda function.
Discriminated Unions and domain invariants
F# has some very useful types called Discriminated Unions. At first glance, they look kind of like enums on steroids, and they can carry custom information. Their structure is quite simple. On the left is the type name, and on the right, specified by the of keyword, are tags which may or may not contain additional information, joined by the | operator.
Here are some examples, including a common type to represent a missing value, a type that can be used to indicate an operation that may fail, and a type that shows how one can easily encode a more complex data structure:

As you can see, with Discriminated Unions we can fully describe the structure of simple types in a single, intuitive line.
Using Discriminated Union types, it’s easy to describe domain models and—even more important—domain invariants. With domain invariants established up front, issues are likely to be caught at the compilation stage. There’s a tongue-in-cheek saying in the functional programming community: If it compiles, it has no bugs.
Let’s take a look at a simple example with FirstName and LastName types and a register function to see how we can program more safely with Discriminated Unions:

Traditionally, we might have implemented the register function with regular strings for the name parameters, but if we did that, we could end up swapping the first and last names, or even passing in an unrelated string as an argument. Using Discriminated Union types, we’ve achieved a version that specifies which name is which. The nice thing about this declarative approach is that once the arguments are initialized (here it’s done simply, but we could also apply some validation logic), we know that we don’t have to worry about the data being invalid or swapped.
How we use declarative approaches at Grammarly
To wrap up our discussion, we’ll now cover a few ways declarative programming has helped our team solve real-world problems while building our add-in for Microsoft Office.
Verifying data at system boundaries
As is often the case, some of the trickiest parts of our system exist at the boundaries between domains. Problems tend to arise when handling responses from servers, communicating with databases, reading files, etc. The main issue is always: How do we make sure that the data from the outer dependency is in the correct format so we can proceed with applying some business logic? You’re probably already picturing the answer. Just validate the data, right?
Well…kind of. Let’s imagine that we want to set up an endpoint for saving users’ emails. (On our team, we encounter similar problems, though unrelated to email.)

Once we validate the email string in this particular place, we pass it along to the SaveEmail function. But there’s an issue. Imagine that SaveEmail invokes a SendEmail function that also accepts the string email. What if we forget to do a validation within the SendEmail function because we think the email argument is already valid, but then our teammate calls SendEmail from somewhere else without validating the email first? If we forget just one validation somewhere, we might have trouble down the road. How can we do better?
Parse, don’t validate
The motto “parse, don’t validate” has become quite popular in the functional programming community. In other words, to ensure that some data is valid in your domain, you should parse it into your domain object. The simplest example might be parsing strings into integers:
![]()
Before parsing, you can’t be sure if the string is a number or not. Parsing is a way to declare that certain data is a valid part of the domain model. It can be helpful to think of it this way: Parsing = validation + transformation.
Building a JSON parser in F#
The team at Grammarly that works on the Microsoft Office add-in works with a lot of different JSON specifications in our backend, and we wanted to handle errors more gracefully when receiving messages with the wrong structure. So we built a DSL that allowed us to declaratively specify the structure we expect from a JSON message and parse the data into the message Entity itself, using the F# operators described below.


As you can see, when we apply the configuration to a string in order to extract the entity, there are only two possible outcomes: success (Ok), or failure (Error). Thus, we guarantee that all entities passed parsing and we can rely on their data inside our domain.
Version distribution
Our users should always get the right version of Grammarly’s add-in for Microsoft Office, based on their device specifications, opt-ins, etc.
We wanted update rules that would give us precise control over the version distribution and a clear way to specify which version should go to which user. But among existing tools for .NET, we couldn’t find the “goldilocks” solution that fit just right. Some solutions involved bloated, imperative syntax. Others required code deployments for each rule, or had heavier machinery than we needed for the task.
So we used a declarative approach to develop our own declarative tools for versioning:

As a result, we have version update rules that are JSON-like, with easy-to-remember, intuitive syntax. It’s safe to adjust the behavior without deploying any code, and it’s straightforward to tune the rules without changing the configuration.
Conclusion
We’ve explored many of the ways declarative programming produces safer, cleaner, and more efficient code, reducing errors and improving readability and maintainability. While some of these concepts might have been new to you, you could say that a lot of the ideas we’ve been talking about are just plain old abstractions, and you wouldn’t be wrong. The idea behind declarative programming is simple. Define the bare minimum that you need in order to focus on your problem domain itself, and let the implementation details take care of themselves—you’ll be doing more with less!
If you enjoyed this discussion, you might want to learn more about Grammarly’s tech stack and check out our open roles. If you’re passionate about writing clean code and want to help millions of people around the world write with clarity and confidence, please get in touch!






