
At Grammarly, the foundation of our business, our core grammar engine, is written in Common Lisp. It currently processes more than a thousand sentences per second, is horizontally scalable, and has reliably served in production for almost three years. We noticed that there are very few, if any, accounts of how to deploy Lisp software to modern cloud infrastructure, so we thought that it would be a good idea to share our experience. The Lisp runtime and programming environment provides several unique—albeit obscure—capabilities to support production systems (for the impatient, they are described in the final chapter).
Wut Lisp?!!

Contrary to popular opinion, Lisp is an incredibly practical language for building production systems. There are, in fact, many Lisp systems out there: When you search for an airline ticket on Hipmunk or take a Tube train in London, Lisp programs are being called.
Our Lisp services are conceptually a classical AI application that operates on huge piles of knowledge created by linguists and researchers. It’s mostly a CPU-bound program, and it is one of the biggest consumers of computing resources in our network.
We run these services on stock Linux images deployed to AWS. We use SBCL for production deployment and CCL on most of the developers’ machines. One of the nice things about Lisp is that you have an option of choosing from several mature implementations with different strengths and weaknesses: In our case, we optimized for processing speed on the server and for compilation speed in the dev environment (the reason this is critical for us is described in the later section).
A stranger in a strange land

At Grammarly, we use many programming languages for developing our services: In addition to JVM languages and JavaScript, we also develop in Erlang, Python, and Go. Proper service encapsulation enables us to use whatever language and platform makes the most sense. There is a cost to maintenance, but we value choice and freedom over rules and processes.
We also try to rely on simple language-agnostic infrastructure tools. This approach spares us a lot of trouble integrating this zoo of technologies in our platform. For instance, StatsD is a great example of an amazingly simple and useful service that is extremely easy to use. Another one is Graylog2; it provides a brilliant specification for logging, and although there was no ready-made library for working with it from CL, it was really easy to assemble from the building blocks already available in the Lisp ecosystem. This is all the code that was needed (and most of it is just “word-by-word” translation of the spec):
(defun graylog (message &key level backtrace file line-no)
(let ((msg (salza2:compress-data
(babel:string-to-octets
(json:encode-json-to-string #{
:version "1.0"
:facility "lisp"
:host *hostname*
:|short_message| message
:|full_message| backtrace
:timestamp (local-time:timestamp-to-unix (local-time:now))
:level level
:file file
:line line-no
})
:encoding :utf-8)
'salza2:zlib-compressor)))
(usocket:socket-send (usocket:socket-connect
*graylog-host* *graylog-port*
:protocol :datagram :element-type '(unsigned-byte 8))
msg (length msg))))One of the common complaints about Lisp is that there are no libraries in the ecosystem. As you see, five libraries are used just in this example for such things as encoding, compression, getting Unix time, and socket connections.
Lisp libraries indeed exist, but like all library integrations, we have challenges with them as well. For instance, to plug into the Jenkins CI system, we had to use xUnit, and it was not so straightforward to find the spec for it. Fortunately, this obscure Stack Overflow question helped—we ended up having to build this into our own testing library should-test.
Another example is using HDF5 for machine learning models exchange: It took us some work to adapt the low-level HDF5-cffi library to our use case, but we had to spend much more time upgrading our AMIs to support the current version of the C library.
Another principle that we try to follow in Grammarly platform is maximal decoupling of different services to ensure horizontal scalability and operational independence. This way, we do not need to interact with databases in the critical paths in our core services. We do, however, use MySQL, Postgres, Redis, and Mongo, for internal storage, and we’ve successfully used CLSQL, postmodern, cl-redis, and cl-mongo to access them from the Lisp side.
We rely on Quicklisp for managing external dependencies and a simple system of bundling library source code with the project for our internal libraries or forks. The Quicklisp repository hosts more than a thousand Lisp libraries—not a mind-blowing number, but quite enough for covering all of our production needs.
For deployment into production, we use a universal stack: The application is tested and bundled by Jenkins, put on the servers by Rundeck, and run there as a regular Unix process by Upstart.
Overall, the problems we face with integrating a Lisp app into the cloud world are not radically different from the ones we encounter with many other technologies. If you want to use Lisp in production—and to experience the joy of writing Lisp code—there is no valid technical reason not to!
The hardest bug I’ve ever debugged

As ideal as this story is so far, it has not been all rainbows and unicorns.
We’ve built an esoteric application (even by Lisp standards), and in the process have hit some limits of our platform. One unexpected thing was heap exhaustion during compilation. We rely heavily on macros, and some of the largest ones expand into thousands of lines of low-level code. It turned out that the SBCL compiler implements a lot of optimizations that allow us to enjoy quite fast generated code, but some of them require exponential time and memory resources. Unfortunately, there’s no way to influence that by turning them off or tuning somehow. However, there exists a well-known general solution, call-with-* style, in which you trade off a little performance for better modularity (which turned out crucial for our use case) and debuggability.
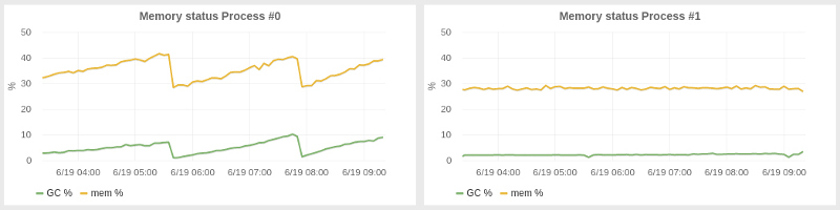
Less surprising than compiler taming, we have spent some time with GC tuning to improve the latency and resource utilization in our system. SBCL provides a decent generational garbage collector, although the system is not nearly as sophisticated as in the JVM. We had to tune the generation sizes, and it turned out that the best option was to use an oversize heap: Our application consumes 2–4 gigabytes of memory but we run it with 25G heap size, which automatically results in a huge volume for the nursery. Yet another customization we had to make—a much less obvious one—was to run full GC programmatically every N minutes. With a large heap, we have noticed a gradual memory usage buildup over periods of tens of minutes, which resulted in spans of more time spent in GC and decreased application throughput. Our periodic GC approach got the system into a much more stable state with almost constant memory usage. On the left, you can see how an untuned system performs; on the right, the effect of periodic collection.
Of all these challenges, the worst bug I’ve ever seen was a network bug. As usual with such stories, it was not a bug in the application but a problem in the underlying platform (this time, SBCL). And, moreover, I was bitten by it twice in two different services. But the first time I couldn’t figure it out, so I had to develop a workaround.
As we were just beginning to run our service under substantial load in production, after some period of normal operation all of the servers would suddenly start to slow down and then would become unresponsive. After much investigation centering on our input data, we discovered that the problem was instead a race condition in low-level SBCL network code, specifically in the way the socket function getprotobyname, which is non-reentrant, was called. It was quite an unlikely race, so it manifested itself only in the high-load network service setup when this function was called tens of thousands of times. It knocked off one worker thread after another, eventually rendering the service comatose.
Here’s the fix we settled on; unfortunately, it can’t be used in a broader context as a library. (The bug was reported to SBCL maintainers, and there was a fix there as well, but we are still running with this hack, just to be sure :).
#+unix
(defun sb-bsd-sockets:get-protocol-by-name (name)
(case (mkeyw name)
(:tcp 6)
(:udp 17)))Back to the future

Common Lisp systems implement a lot of the ideas of the venerable Lisp machines. One of the most prominent ones is the SLIME interactive environment. While the industry waits for LightTable and similar tools to mature, Lisp programmers have been silently and haughtily enjoying such capabilities with SLIME for many years. Witness the power of this fully armed and operational battle station in action.
But SLIME is not just a Lisp’s take on an IDE. Being a client-server application, it allows to run its back-end on the remote machine and connect to it from your local Emacs (or Vim, if you must, with SLIMV). Java programmers can think of JConsole, but here you’re not constrained by the predefined set of operations and can do any kind of introspection and changes you want. We could not have debugged the socket race condition without this functionality.
Furthermore, the remote console is not the only useful tool provided by SLIME. Like many IDEs, it has a jump-to-source function, but unlike Java or Python, I have SBCL’s source code on my machine, so I often consult the implementation’s sources, and this helps understand what’s going on much better. For the socket bug case, this was also an important part of the debugging process.
Finally, another super-useful introspection and debugging tool we use is Lisp’s TRACE facility. It has completely changed my approach to debugging—from tedious local stepping to exploring the bigger picture. It was also instrumental in nailing our nasty bug.
With trace, you define a function to trace, run the code, and Lisp prints all calls to that functions with arguments and all of its returns with results. It is somewhat similar to stacktrace, but you don’t get to see the whole stack and you dynamically get a stream of traces, which doesn’t stop the application. trace is like print on steroids; it allows you to quickly get into the inner workings of arbitrary complex code and monitor complicated flows. The only shortcoming is that you can’t trace macros.
Here’s a snippet of tracing I did just today to ensure that a JSON request to one of our services is properly formatted and returns an expected result:
0: (GET-DEPS
("you think that's bad, hehe, i remember once i had an old 100MHZ dell
unit i was using as a server in my room"))
1: (JSON:ENCODE-JSON-TO-STRING
#<HASH-TABLE :TEST EQL :COUNT 2 {1037DD9383}>)
2: (JSON:ENCODE-JSON-TO-STRING "action")
2: JSON:ENCODE-JSON-TO-STRING returned ""action""
2: (JSON:ENCODE-JSON-TO-STRING "sentences")
2: JSON:ENCODE-JSON-TO-STRING returned ""sentences""
1: JSON:ENCODE-JSON-TO-STRING returned
"{"action":"deps","sentences":["you think that's bad,
hehe, i remember once i had an old 100MHZ dell unit i was using as a
server in my room"]}"
0: GET-DEPS returned
((("nsubj" 1 0) ("ccomp" 9 1) ("nsubj" 3 2) ("ccomp" 1 3) ("acomp" 3 4)
("punct" 9 5) ("intj" 9 6) ("punct" 9 7) ("nsubj" 9 8) ("root" -1 9)
("advmod" 9 10) ("nsubj" 12 11) ("ccomp" 9 12) ("det" 17 13)
("amod" 17 14) ("nn" 16 15) ("nn" 17 16) ("dobj" 12 17)
("nsubj" 20 18) ("aux" 20 19) ("rcmod" 17 20) ("prep" 20 21)
("det" 23 22) ("pobj" 21 23) ("prep" 23 24)
("poss" 26 25) ("pobj" 24 26)))
((<you 0,3> <think 4,9> <that 10,14> <'s 14,16> <bad 17,20> <, 20,21>
<hehe 22,26> <, 26,27> <i 28,29> <remember 30,38> <once 39,43>
<i 44,45> <had 46,49> <an 50,52> <old 53,56> <100MHZ 57,63>
<dell 64,68> <unit 69,73> <i 74,75> <was 76,79> <using 80,85>
<as 86,88> <a 89,90> <server 91,97> <in 98,100> <my 101,103>
<room 104,108>))So to debug our nasty socket bug, I had to dig deep into the SBCL network code and study the functions being called, then connect via SLIME to the failing server and try tracing one function after another. And when I got a call that didn’t return, that was it. Finally, looking at man to find out that this function isn’t re-entrant and encountering some references to that in the SBCL’s source code comments allowed me to verify this hypothesis.
That said, Lisp proved to be a remarkably reliable platform for one of our most critical projects. It is quite fit for the common requirements of modern cloud infrastructure, and although this stack is not very well-known and popular, it has its own strong points—you just have to learn how to use them. Not to mention the power of the Lisp approach to solving difficult problems—which is why we love it. But that’s a whole different story, for another time.






